基于深度学习的隐写文本抗隐写分析能力增强方法
本发明属于信息传输中的信息隐藏,具体涉及一种基于深度学习的隐写文本抗隐写分析能力增强方法。
背景技术:
1、信息隐藏领域主要研究如何将秘密信息高效且安全地嵌入到其他信息载体中,目的是通过掩盖信息的存在性从而保障其安全。
2、近些年来,随着互联网的飞速发展,越来越多的人使用互联网进行信息的传递与互通交流,这使得保护秘密信息安全的主战场从特定场景逐渐转向开放域环境。在实际意义上,生成式文本隐写相较于检索式和修改式文本隐写,具有能够根据真实载体的统计分布特征生成符合真实环境统计分布特征的隐写文本、能保证一定隐蔽性的同时有着较大的嵌入容量、实用性高、噪声低等优势,所以更适合开放式网络环境。在社交媒体中的真实载体中充斥着大量的表情符号被用于强化句子的情绪、明确句子的含义。正是表情符号可以作为一种感情、视觉线索去帮助用户明确意图,大大降低接收方对于发送方意图理解的歧义,所以其越来越深受用户的喜爱,导致表情符号在社交媒体上的使用频率越来越高,在国内外常见的社交平台上,含有表情符号的网络文本占比高达20%左右,而同类工作并没有考虑表情符号引起的人类视觉感知问题,因此我们不能不重视这一问题。在以往相关研究中,研究者们都未能充分的考虑真实信道的分布特征,他们都忽略了真是信道中的表情符号的存在(即在预处理阶段就将表情符号从文本中剔除了),这势必导致隐写载体分布与真实载体的统计分布过大,导致隐写文本的抗隐写分析能力变差,即对秘密信息的保护能力变差,导致隐蔽系统变得更加不安全。
技术实现思路
1、针对以往研究都未能充分考虑真实信道统计分布特征这一问题,本发明提出了一种基于深度学习的隐写文本抗隐写分析能力增强方法,充分考虑了真实信道中的特征统计分布,并进一步提高了隐写文本在公共信道中的抗隐写分析能力。
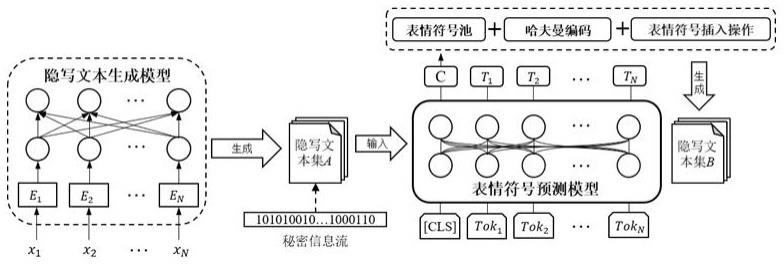
2、本发明的目的是通过以下技术方案实现的:一种基于深度学习的隐写文本抗隐写分析能力增强方法,该方法包含以下步骤:
3、一种基于深度学习的隐写文本抗隐写分析能力增强方法,包含以下步骤:
4、步骤1:从社交媒体平台中搜集网络文本;
5、步骤2:对数据集进行相应的预处理,包括清除特殊符号、超链接以及电话号码构成数据集;
6、步骤3:统计数据集中表情符号的统计分布特征并根据语义进行分类,并设计两种表情符号推荐算法:insert算法与replace算法;
7、步骤4:进一步处理数据集分别用于隐写文本生成模型和表情符号预测模型的训练;
8、步骤5:用步骤4中训练好的隐写文本生成模型生成具有秘密信息的隐写文本,并将隐写文本输入到步骤4中训练好的表情符号预测模型中,根据步骤3的推荐算法将表情符号加入到隐写文本中;
9、步骤6:计算步骤5中生成的隐写文本生成模型生成的纯文本隐写文本、经insert算法加入表情符号的隐写文本、经replace算法加入表情符号的隐写文本三组数据的基本指标,并输入进隐写分析模型中比较三组隐写文本的抗隐写分析能力强弱。
10、进一步地,所述步骤1包括以下步骤:
11、步骤1-1:首先利用相应社交媒体平台通用停用词库作为爬虫的关键词库;
12、步骤1-2:以随机的方式从停用词库中抽取一个停用词作为一轮数据爬取的关键词;
13、步骤1-3:自定义设置每轮爬取的关键词数目,以统计通信信道自身的统计特征为目标,
14、数据量大小不低于100万条。
15、进一步地,所述步骤3包括以下步骤:
16、步骤3-1:统计表情符号的频率特征:统计各个表情符的频率,以及含有表情符号的网络文本占比;
17、步骤3-2:统计含有标点符号的网络文本占比;
18、步骤3-3:统计表情符号在网络文本中的位置信息,划分为句首、句中以及句尾;
19、步骤3-4:统计含有各数目表情符号的网络文本占比;
20、步骤3-5:根据所统计的信息作为宏观调控,设计表情符号推荐算法。
21、进一步地,所述步骤3-5包括以下步骤:
22、步骤3-5-1:算法参数说明:
23、a:步骤5中隐写文本生成模型生成的纯文本隐写文本集;
24、s:a中的单条隐写文本;
25、s1:完成表情符插入后的隐写文本;
26、b:步骤5中经过表情符号推荐算法加入表情符号后的隐写文本集;
27、f:步骤3-1中统计出的数据集中含有表情符号的网络文本占比;
28、f1:步骤3-2中统计出来的含有标点符号的网络文本占比;
29、p:步骤3-3中统计出的表情符号在网络文本中的位置信息;
30、p:p中的具体值,取句首、句中与句尾其中一个;
31、p1:当前网络文本的标点符号位置索引列表;
32、p1:随机从p1中选取的具体值;
33、n:步骤3-4中统计出的含有各数目表情符号的网络文本占比情况;
34、n:n中的具体值,取值范围为n∈[1,5],其中n为正整数;
35、步骤3-5-2:设计表情符号插入算法:
36、1)从a中选取s,然后根据f的概率值,判断是否对其进行表情符号插入操作,如果判断结果为flase则进入2),为true则进入3);
37、2)将s输出到b中,该条隐写文本操作结束;
38、3)从n中选取数量信息n作为对s的插入表情符号数量;
39、4)表情符号预测模型对输入句子进行情感预测,然后从预测的表情符号分类池中根据真实统计分布选择一个表情符号,然后从p中选取位置信息p作为该表情符在s中的插入位置,此过程循环n遍;
40、5)完成4)操作后,得到s1,并将s1输出到b中;
41、步骤3-5-3:设计表情符号替换算法:
42、1)从a中选取s,判断s中是否含有标点符号,如果判断结果为true,则进入3),如果为flase,则进入2);
43、2)将s输出到b中,该条隐写文本操作结束;
44、3)根据的概率值,判断是否对其进行表情符号替换操作,如果判断结果为true,则进入5),如果判断结果为flase,则进入4);
45、4)将s输出到b中,该条隐写文本操作结束;
46、5)从n中选取数量信息n作为对s的插入表情符号数量;
47、6)计算当前隐写文本的标点符号位置索引p1,并从中随机选取替换位置p1;
48、7)使用表情符号预测模型对s进行n次预测,得到n个表情符号合并成一个字符串对p1位置的标点符号进行替换;
49、8)完成7)操作后得到s1,并将s1输出到b中。
50、进一步地,所述步骤4包括以下步骤:
51、步骤4-1:去除数据集中的所有表情符号,获得纯英文文本形式的数据集用于隐写文本生成模型的训练;
52、步骤4-2:抽取数据集中所有包含表情符号的网络文本,用于表情符号预测模型的训练。进一步地,所述步骤4-2包括以下步骤:
53、步骤4-2-1:根据步骤3-1中的统计结果,构建表情符号库s,构建标准是选取占比表情符号整体数量90%以上的表情符号;
54、步骤4-2-2:将表情符号库中的表情符按照其语义分成m类,并对每个分类进行编号和huffman编码,即:
55、s={c1,c2,…,cm}
56、ci={h1,h2,…,hn}
57、其中m表示s中表情符号按照语义共分为m类,cm表示第m类;ci表示s中的第i类(2≤i≤m),其中hn表示该类中第n个表情符的huffman编码;
58、步骤4-2-3:构建数据标签。
59、进一步地,所述步骤4-2-3包括以下步骤:
60、1)计算一条数据中的表情符频率,降序排序构成列表list;
61、2)当list长度等于1时,判断list1属于s中的ci类,则该条数据标记i;
62、3)当list长度大于1时,当list1>list2,判断list1属于s中的ci类,则该条数据标记i;
63、4)当list长度大于1时,当list1=list2,判断list1与list2是否属于同一类,如果是,判断list1属于s中的ci类,则该条数据标记i,如果不是,则该条数据丢弃;
64、5)将得到的带标记的数据集输入到表情符号预测模型中进行训练。
65、进一步地,所述步骤6包括以下步骤:
66、步骤6-1:bpw计算:衡量隐写文本秘密信息的嵌入容量大小,越大越好,使用下面的公式计算:
67、
68、其中bits表示隐写文本中的秘密信息比特数,words表示隐写文本的单词数;
69、步骤6-2:δmp计算:衡量隐写文本与真实文本的平均困惑度的相近程度,越小越好,使用下面的公式计算:
70、s={x1,x2,…,xn}
71、
72、δmp=|mean(pplstego)-mean(pplnormal)|
73、其中s表示待测句子,n为正整数,表示句子长度,在perplexity的计算公式中,2≤j≤n,且j为正整数,mean(pplstego)表示所有隐写文本的perplexity平均值,mean(pplnormal)表示所有正常文本的perplexity平均值;
74、步骤6-3:kld(kullback-leibler divergence)测量:kld越小表示隐写方法越安全,计算方法如下所示:
75、
76、其中vx和vy分别表示隐写文本和正常文本在空间中的向量表示μ和σ分别表示句子向量的平均值与标准差;
77、步骤6-4:使用基于隐写分析工具去测试三组隐写文本的抗隐写能力,用分类任务中常用的评估指标来评估隐写文本抗隐写分析的能力,即准确度acc和召回率r概念和公式描述如下:
78、
79、
80、其中tp表示由模型预测为正的正样本的数量,fp表示预测为正的负样本的数量;fn表示预测为负的正样本数量,tn代表预测为负的负样本数量;
81、步骤6-5:根据实验结果,比较加入表情符号后的隐写文本与纯文本隐写文本的安全性和抗隐写分析能力强弱,同时根据指标结果比较两种推荐策略的优劣。
82、本发明有益的技术效果:与之前的方法相比,本发明弥补了之前工作中隐写文本缺少视觉线索的问题,并且根据真实环境中的表情符号分布,设计了一种表情符号推荐算法以尽可能的使隐写文本中表情符号的统计分布接近与真实环境中表情符号的统计分布。最终使隐写文本在加入视觉线索后,其各项安全性指标均有进一步的提升。
- 还没有人留言评论。精彩留言会获得点赞!