一种基于Python协程和DataX的数据同步平台
本发明涉及异构数据库数据同步领域,实现了一种基于python协程和datax的数据同步平台。
背景技术:
1、数据库技术蓬勃发展,每种数据库都有自己的特点,以及其适合的场景。因此在生产环境中,开发者有了更多的数据库选择,甚至选择组合数据库方案。因此,异构数据库之间的dts需求日益明显。其中,dts(data transmission service, 数据传输服务)可帮助用户在业务正常运行的前提下完成数据库迁移、同步等操作,其可以利用实时同步通道轻松构建安全、可扩展、高可用的数据架构。dts能通过数据订阅等操作为用户实现商业数据挖掘、业务异步解耦等需求。
2、在有些场景中,比如随着业务的快速发展和用户的持续增长,需要把业务进行多地域部署(异地部署)。如果该业务的某些用户在地理位置上的分布较为分散,那么地理位置较远的用户在访问业务时就会出现较高延迟,影响用户体验;并且如果将业务部署在唯一地理单元,那么当该业务的此地理单元出现问题时,用户所访问的业务就会崩溃。因此将该业务部署在多地理单元,既能让所有用户较低延迟访问服务,就近访问服务,提升用户体验;又可以实现业务数据的灾备问题。因此这就需要dts服务进行不同业务地理单元之间的数据同步,保证各地数据一致性等。
3、除此之外,目前市面上很多公有云厂商都已经提供了dts服务,虽然可靠性较高,但是成本也很高。并且一般公有云厂商所提供的dts服务与自家云数据库产品的耦合度较高,对于该云厂商之外的异构数据库支持不是很好;另外,不同用户对于dts的需求不一样,因此许多公有云厂商所提供的dts虽然可以较好地实现数据同步,但是在数据订阅、不活跃数据、存储周期较长数据的冷存储等方面,不能满足不同用户之间的需求。
技术实现思路
1、本发明的目的在于针对现有数据同步技术的局限性而提出的一种基于python协程和datax的数据同步平台,其可以在对基准数据库和目标数据库侵入性较小的情况下,实现异构数据库之间的数据同步。该平台支持用户基于自有的服务器资源,构建稳定、可靠、高效、可定制化、支持分层存储的数据同步平台,使得用户在满足自身需求的前提下,为用户提供低成本、稳定高效的数据操作服务。
2、实现本发明目的的具体技术方案是:
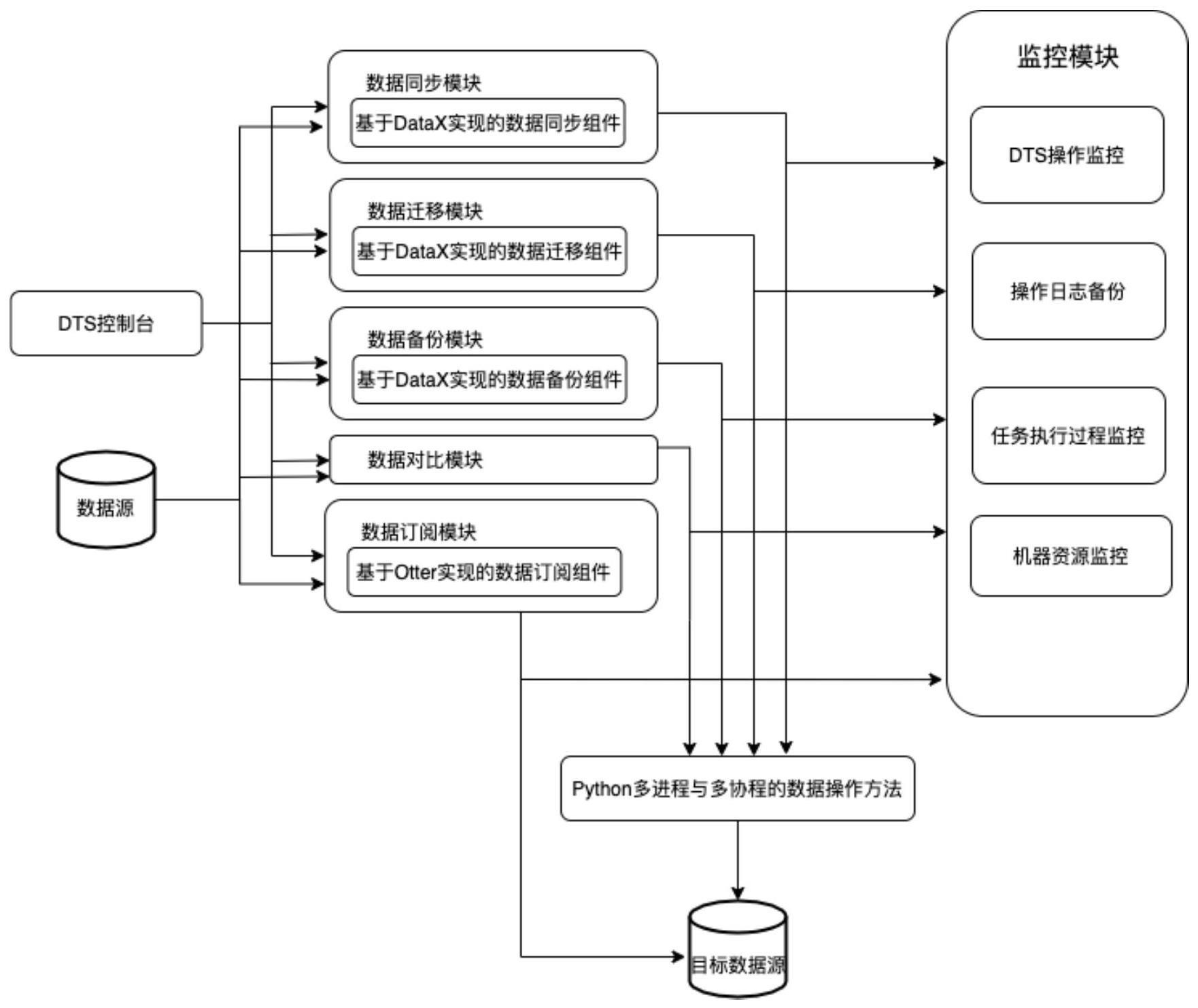
3、一种基于python协程和datax的数据同步平台,特点是所述平台包括:
4、数据同步模块、数据迁移模块、数据备份模块、数据对比模块、数据订阅模块以及监控模块,其中,
5、所述数据同步模块,使用控制台或者文件接收用户数据同步任务的参数配置,生成数据同步组件执行数据同步任务所需的json配置文件,执行最终的数据同步任务;对数据同步任务所需的json配置文件进行参数审核,检查json配置文件中配置参数是否合法,参数属性是否存在;数据同步模块中,数据同步任务目标为将基准数据库中待同步数据表中的数据同步到目标数据库中指定数据表;数据同步组件基于开源数据同步组件datax设计实现,数据同步任务的执行依赖于数据同步组件,数据同步组件使用数据同步模块中python多进程和多协程并发执行任务的数据同步方法完成数据同步任务;基于python多进程和多协程划把数据同步任务分割为多个数据同步子任务,每个数据同步子任务处理数据同步任务中的一部分数据,针对基准数据库中每张数据表启动一个python进程,每个python进程中多个协程并行处理数据表中的数据,完成数据同步子任务,最后完成整个数据同步任务;数据同步模块中的基准数据库,就是待同步数据库,以该数据库为基准,使用该数据库中的数据对目标数据库中对应的数据存储单元进行完全的数据覆盖,关系型数据库中的数据存储单元即为行列结构的数据表;数据同步模块支持使用linux内置的cron进程和shell脚本设置定时数据同步任务;数据同步模块包含数据同步任务队列,数据同步模块从数据同步任务队列取出待执行的数据同步任务,并行执行数据同步任务;
6、所述数据迁移模块,使用控制台或者文件接收用户数据迁移任务的参数配置,并生成数据迁移组件执行数据迁移任务所需的json配置文件,执行最终的数据迁移任务;数据迁移模块中,数据迁移目标为将基准数据库中的所有数据迁移到目标数据库中,此处的数据迁移是针对基准数据库中所有数据表中全部数据的全量迁移;数据迁移组件基于开源数据同步组件datax设计实现,数据迁移任务的执行依赖于数据迁移组件,数据迁移组件使用数据迁移模块中python多进程和多协程并发执行任务的数据迁移方法完成数据迁移任务;数据迁移模块中的基准数据库,就是待迁移数据库,将该数据库中的所有数据全部迁移到目标数据库,或者迁移到nfs或oss存储中;数据迁移模块支持使用linux内置的cron进程和shell脚本设置定时数据迁移任务;
7、所述数据备份模块,使用控制台或者文件接收用户数据备份任务的参数配置,并生成数据备份组件执行数据备份任务所需的json配置文件,完成最终的数据备份任务;对数据备份任务所需的json配置文件进行参数审核,检查json配置文件中配置参数是否合法,参数属性是否存在;数据备份模块对多基准异构数据库以及一个目标异构数据库进行数据备份任务;数据备份模块中,数据备份流程是将基准数据库中所有数据表的全部数据备份到多地域的多类型存储介质中,实现基准数据库中全量数据的异地多活备份;数据备份组件基于开源数据同步组件datax设计实现,数据备份任务的执行依赖于数据备份组件,数据备份组件使用数据备份模块中python多进程和多协程并发执行任务的数据备份方法完成数据备份任务;数据备份模块中的基准数据库,就是待备份数据库,将该数据库中的所有数据全部备份到目标数据库,或者备份到nfs或oss存储中;数据备份模块支持用户自定义数据备份周期以及选择备份存储介质;数据备份模块支持使用linux内置的cron进程和shell脚本设置定时数据备份任务;
8、所述数据对比模块,使用控制台或者文件接收用户数据对比任务的参数配置,对数据对比任务进行数据实例化操作,完成数据对比任务;数据对比流程是将基准数据库与目标数据库中所有数据表中的数据进行对比,数据对比模块基于python多进程和多协程并发执行任务的数据并行方法进行数据库之间多级别的数据对比,避免所述数据对比模块中基准数据库与目标数据库直接进行全量数据对比所带来的开销,对比任务完成后生成数据对比结果,然后根据数据对比结果进行消息通知;数据对比任务在多python协程中执行,由监控模块监控任务进度;数据对比模块的基准数据库,就是待对比数据库,以该数据库为基准,目标数据库中的数据一旦与该数据库中的数据不一致,就要把差异结果输出到控制台;多级别的数据对比包括:数据表、视图、存储过程、存储函数和触发器数据库对象级别的差异对比,数据表的数据总量进行对比,以及每张数据表中数据记录项的对比;数据对比模块支持使用linux内置的cron进程和shell脚本设置定时数据对比任务;
9、所述数据订阅模块,用户界面化进行数据订阅任务的配置,用户需要添加数据订阅任务的参数,生成最终配置的数据订阅任务;数据订阅模块中,数据订阅分为单向增量数据订阅和双向增量数据订阅;单向增量数据订阅是以基准数据库为基准,数据订阅模块监测基准数据库,当该数据库中的数据发生改变时,变化数据被更新到另一个数据库中,实现数据订阅;双向增量数据订阅涉及两个数据库即第一数据库和第二数据库,数据订阅模块监测第一数据库,第一数据库中的数据发生改变时,变化数据被更新到第二数据库中,此时第一数据库是基准数据库,第二数据库是目标数据库,并且,数据订阅模块同时检测第二数据库,第二数据库中的数据发生改变时,变化数据被更新到第一数据库中,此时第二数据库是基准数据库,第一数据库是目标数据库,实现双向数据订阅;数据订阅模块中的数据订阅组件基于开源数据订阅组件otter实现,数据订阅任务的执行依赖于数据订阅组件,用户界面化操作数据订阅组件,添加数据订阅任务的参数;数据订阅模块支持用户配置定时数据订阅任务;数据订阅模块将数据订阅组件安装流程封装在helm脚本中,用户直接通过helm脚本在本地部署数据订阅模块;
10、所述监控模块,监控数据同步模块、数据迁移模块、数据备份模块、数据对比模块和数据订阅模块的操作,将操作记录保存在监控模块的日志文件中;并且,监控模块使用linux内置mpstat、iostat、free系统命令监控服务器中的cpu、i/o和内存资源使用情况,监控信息存放在监控文件中。
11、其中,数据同步模块,所述使用控制台或者文件接收用户数据同步任务的参数配置,生成数据同步组件执行数据同步任务所需的json配置文件,执行最终的数据同步任务,具体包括:
12、python多进程读取异构数据库数据同步任务所需的配置参数,配置参数包括基准数据库地址、待同步数据表、待同步数据字段、目标数据库地址和数据同步速率;
13、执行数据同步任务时,数据同步任务执行进度显示在用户控制台上,任务执行日志存储在所述监控模块的日志文件中。
14、数据备份模块,所述对数据备份任务所需的json配置文件进行参数审核,若审核通过,则其按照构建后的数据备份任务json文件进行数据备份任务;否则,用户重新提交数据备份任务参数。
15、所述数据备份模块支持用户自定义数据备份周期以及选择备份存储介质,包括:
16、用户自定义待备份数据库的数据备份周期,以及备份任务的触发时间;
17、用户自定义数据备份的存储介质以及存储位置;
18、用户周期性备份操作被记录在所述的监控模块的日志文件中。
19、所述数据对比模块基于python多进程和多协程并发执行任务的数据并行方法进行数据库之间多级别的数据对比,避免所述数据对比模块中基准数据库与目标数据库直接进行全量数据对比所带来的开销,包括:
20、对于异构数据库之间多级别数据对比任务,数据对比方法顺序进行不同级别的数据对比;
21、使用python多进程针对不同数据表进行数据表比较,其中使用python多协程进行数据表中分组数据记录项的对比;
22、基于checksum数据表值对数据表所有数据进行比较;
23、基于每张数据表中分组数据的md5值进行数据记录级别的比较。
24、所述数据对比流程是将基准数据库与目标数据库中所有数据表中的数据进行对比,在进行多级别数据对比时,如果较高级别数据存在差异,即基准数据库与目标数据库之间的数据表结构出现差异,则不再进行后续级别的数据记录差异比较;否则,继续进行数据表的数据总量以及每张数据表中数据记录项的对比。
25、所述数据对比任务在多python协程中执行,如果任务超时或者任务执行失败,数据同步平台返回任务超时、执行失败的信息,任务执行失败信息被记录在监控模块的日志文件中。
26、所述数据订阅模块监测基准数据库,具体为:对基准数据库与目标数据库之间的增量数据进行数据同步,当检测到基准数据库的数据库数据发生变化时,自动触发增量数据订阅流程。
27、所述数据订阅模块支持用户配置定时数据订阅任务,具体为:用户预设增量数据同步时间,当到达预设时间时,数据订阅模块获取基准数据库中发生变化的数据,将此部分发生变化的数据作为增量数据,并将此部分增量数据与待订阅历史数据进行合并,作为同步增量数据,用作单向增量数据订阅以及双向增量数据订阅所需的变化数据。
28、所述数据订阅模块将数据订阅组件安装流程封装在helm脚本中,用户直接通过helm脚本在本地部署数据订阅模块,具体为:用户使用helm脚本一键安装数据订阅模块以及启动canal、zookeeper、node组件,通过宿主机ip和端口将组件地址暴露出来。
29、本发明构建了一种基于python协程和datax的数据同步平台,包括:数据同步模块、数据迁移模块、数据备份模块、数据对比模块、数据订阅模块,以及监控模块。与现有技术相比,本发明具有一定优点:此发明中的数据同步模块支持多数据库之间的离线数据数据同步,支持多种类型数据源;数据订阅模块支持多数据库之间的数据准实时同步,界面化操作降低了使用成本;相比传统的数据同步方法——快照法、触发器法,此发明中的数据同步模块基于数据同步开源组件构建数据同步组件,在无额外代码侵入基准数据库和目标数据库的情况下,实现了用户可自定义、可自行扩展的数据库同步组件;此发明中的数据同步模块、数据迁移模块、数据备份模块、数据对比模块都使用了python多进程和多协程并行执行任务的数据操作方法,提升了数据同步、数据迁移、数据备份、数据对比任务的执行效率;数据备份模块中用户自定义使用不同存储介质,访问频率较低的数据存储在较低成本的存储介质中,降低了数据备份成本;数据对比模块中进行基准数据库与目标数据库之间的多级别数据对比,避免基准数据库与目标数据库直接进行全量数据对比所带来的开销,提升了数据对比的效率;此发明具有使用简单、可扩展性强、执行效率高的特点。
30、应当明确,以上的一般描述和后文的具体实例描述仅仅是示例性和解释性的,不能限制此发明。
- 还没有人留言评论。精彩留言会获得点赞!