一种基于重建流场的压缩视频质量增强方法
本发明属于视频质量增强,具体涉及一种基于重建流场的压缩视频质量增强方法。
背景技术:
1、近年来为进一步降低视频的传输带宽和存储空间占用,h.264/avc和h.265/hevc等先进视频压缩标准被广泛用于视频压缩与传输中。为了达到更高的压缩率,这些有损压缩方法往往会造成视频质量的严重下降,引入各种噪声和伪影(如块效应、振铃效应、模糊等)。压缩导致的视频质量降低不仅会极大地影响观看效果,还会对下游的计算机视觉任务(如分类、识别、检测和跟踪等)带来不同程度的影响。因此,在面向网络传输和ai分析等应用环境中,对压缩视频质量的增强技术需求十分迫切。
2、受到视频编码器的压缩,视频帧间的质量往往会出现较大的波动。其中,常见的情况是压缩后的视频会周期性地出现高质量的视频帧,高质量帧中包含了更多可用于提升低质量帧重建效果的互补信息,如物体细节纹理等信息,如何利用这些互补信息就变得极为关键。
3、为了更好的利用到帧间的互补信息,现有的方法可以大致分为两类,一类是通过在视频帧上通过滑动窗口的方式,利用时域上局部范围内的互补信息辅助进行重建,质量提升效果相比于单帧重建方法更好。但是基于滑动窗口的方法受限于时域上局部感受野,并不能利用到整个序列上更加丰富的信息,而另一类方法采用循环传播结构的方法,借助循环神经网络的优势,可以在不增加太多参数量的情况下,利用到时域上全局的信息,从而实现重建效果的进一步提升。视频压缩的过程中会带来各种先验信息,其中比较重要的一些包括压缩过程中的量化参数、在帧间编码时用于运动补偿的运动矢量等。这些先验信息可以直接从编码时的码流信息中提取出来,其中包含了大量有利于重建任务的信息。在本发明的技术方案的实现过程中,发明人发现:视频压缩的过程中会带来各种先验信息,其中比较重要的一些包括压缩过程中的量化参数、在帧间编码时用于运动补偿的运动矢量等。这些先验信息可以直接从编码时的码流信息中提取出来,其中包含了大量有利于重建任务的信息。若在压缩视频质量增强处理能对这些先验信息充分利用,应该能提升压缩视频质量增强的增强效果。
技术实现思路
1、本发明提供了一种基于重建流场的压缩视频质量增强方法,通过充分利用视频压缩时产生的先验信息来进行质量增强重建,以显著提升了重建质量。
2、本发明采用的技术方案为:
3、一种基于重建流场的压缩视频质量增强方法,所述方法包括:
4、步骤1,构建模型训练数据集:
5、对无压缩视频序列构成的视频数据集中的每个视频进行压缩编解码,到得到每个视频序列所对应的不同压缩质量视频;在压缩编解码时提取码流中的先验信息,包括编码帧的量化参数qp和运动矢量mv;
6、视频数据集中的各视频帧定义为高质量视频帧,压缩编解码后视频帧为低质量视频帧,得到高-低质量视频对;
7、对高-低质量视频对进行图像预处理,基于指定长度的连续视频序列的高-低质量视频对,以及对应的先验信息得到一个样本数据,基于一定数量的样本数据得到模型训练数据集;
8、步骤2,构建及训练视频增强网络模型;
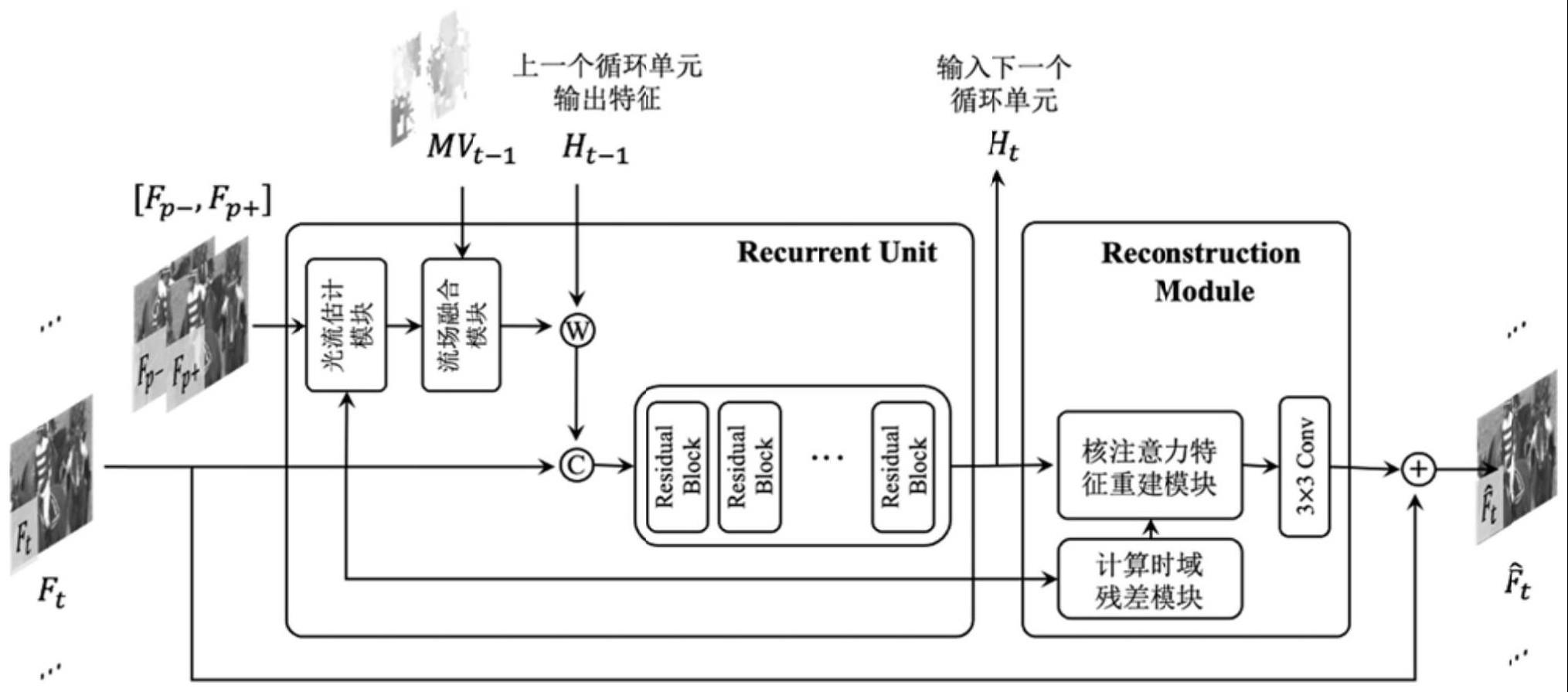
9、所述视频增强网络模型包括循环结构和重建模块;
10、循环结构包括多个循环单元,每个循环单元对应着输入的低质量视频帧序列中的一帧,每个循环单元的输入包括:当前视频帧ft和其相邻的两帧关键帧{fp-,fp+},以及上一个循环单元中输出的深度特征ht-1;其中,关键帧根据先验信息中的量化参数qp进行选择;每个循环单元用于提取当前视频帧ft的深度特征ht;
11、所述循环单元包括光流估计模块、流场融合模块和多层级连的残差卷积模块;
12、光流估计模块的输入为{fp-,ft,fp+},用于预测当前视频帧ft的光流场;
13、流场融合模块的输入包括当前视频帧ft的光流和上一视频帧的编码运动矢量场mvt-1,用于对编码运动矢量场和光流场进行融合,得到重建流场;
14、将重建流场与上一个循环单元输出的深度特征ht-1进行对齐操作,再与当前视频帧ft按通道维度进行拼接后输入多层级连的残差卷积模块,得到深度特征ht;
15、所述重建模块包括核注意力特征重建模块、时域残差计算模块和多层卷积层;
16、其中,时域残差计算模块用于计算当前视频帧ft与其前后相邻帧之间的时域残差,并将计算结果输入核注意力特征重建模块;
17、核注意力特征重建模块的输入包括时域残差计算模块计算得到的时域残差和深度特征ht,用于提取卷积核注意力图,并基于卷积核注意力图对特征ht进行卷积运算,得到当前视频帧ft的深度特征
18、通过多层卷积层对深度特征进行图像通道数恢复,得到当前视频帧ft的残差图像;
19、将当前视频帧ft与其残差图像求和得到当前视频帧ft的视频质量增强结果即重建的高质量视频帧;
20、基于预置的损失函数对视频增强网络模型进行网络参数训练,当达到预置的训练结束条件时(比如训练次数达到上限、训练精度达到指定条件等),得到用于目标视频的视频增强网络模型。
21、进一步的,所述流场融合模块包括流场权重计算单元和流场重建单元;
22、其中,权重计算单元依次包括:3×3卷积核的卷积层,激活函数(优选leakyrelu)、3×3卷积核的卷积层和softmax函数;
23、权重计算单元的输入为当前视频帧ft,softmax函数用于输出编码运动矢量场的每个像素的运动矢量权重ω,从而得到光流场中每个像素的运动矢量的权重1ω,基于加权融合方式对输入的编码运动矢量场和光流场进行加权融合,得到重建流场。
24、进一步的,所述核注意力特征重建模块提取卷积核注意力图具体为:首先对时域残差和深度特征ht进行通道拼接,再输入多层级连的卷积块,该多层级连的卷积块的输出再与时域残差和深度特征ht的通道拼接结果相加得到卷积核注意力图;其中,卷积块包括依次连接的卷积层和激活函数。
25、进一步的,视频增强网络模型在网络参数训练时采用的损失函数为:
26、
27、其中,表示前视频帧ft的高质量视频帧,即原始未经压缩的视频帧,ε为预置的取值小于1的常量。
28、本发明提供的技术方案至少带来如下有益效果:
29、(1)本发明提出的重建流场通过引入编码先验弥补了传统光流的缺陷,实现了更好的运动补偿。使用轻量化的流场融合模块融合视频编码过程中码流先验信息中的运动矢量和由编码后的低质量视频帧估算得到的光流,得到一个面向高质量压缩视频重建的“重建流场”,用于视频重建过程中帧间的运动补偿。
30、(2)本发明提出了核注意力重建模块,用于解决图像上空间分布不均匀退化的重建问题。从视频压缩带来的空间上分布不均匀的退化这一现状出发,具有空间分布变化性的核注意力模块通过逐像素的估计不同的卷积核,从而实现从特征中重建出高质量视频帧,缓解压缩视频帧在空间上质量波动的情况。
31、(3)本发明提出了基于循环神经网络(rnn)的架构来处理压缩视频,从而更好的利用视频时域上的帧间互补信息。相比于先前方法中采用滑动窗口的策略只能利用到局部的时域信息,rnn可以对全局的时域信息加以利用,从而利用丰富的帧间互补信息提高每一帧的重建效果。
- 还没有人留言评论。精彩留言会获得点赞!