领域数据增强与多粒度语义理解的多轮对话方法及系统
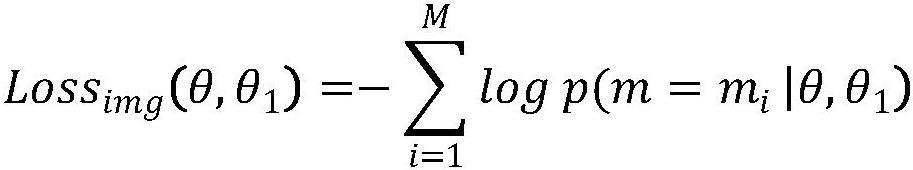
本发明涉及自然语言处理,具体涉及一种领域数据增强与多粒度语义理解的多轮对话方法及系统。
背景技术:
1、对话系统可以直观的模拟人类智能对话,对于人工智能的发展有着重要的研究意义。现有的构建对话系统的工作包括两种,一种是生成式对话,另一种是检索式对话。生成式对话主要通过一个自然语言生成模型进行合成回复,它的优点是可以生成多种多样的回复,缺点是生成的回复准确率不高,往往不能正确回答用户的问题,同时,还容易陷入安全回复的陷阱中。检索式对话是通过算法模型根据对话历史和当前用户的问题,在语料库中进行检索,在大量候选的回复中选择最贴切于用户问题的回复返回给用户,与生成式对话相比,检索式对话的准确率更高,返回的内容更接近用户的问题,因此检索式对话也有着更高的实用性。
2、检索式对话分为单轮对话和多轮对话两种,单轮对话主要用于短文本的问答,不能处理对话历史信息,对长文本的理解能力不足。在日常生活中,用户往往会通过多条话语表达自己的意图,因此单轮对话在实际的应用场景中价值不高。检索式多轮对话根据对话历史和当前用户的问题在大量的候选回复中进行选择,而对话上下文中的长距离依赖关系,蕴含的时序语义信息以及话题的转换使得选择合适的回复十分困难。在本篇文章中,本文重点关注于检索式对话中的多轮回复选择问题。给出一段对话中的上下文,该上下文中有多句话语构成。这项任务的目的是从大量的候选回复中选择出最匹配当前上下文的回复。
3、在深度学习兴起之前,基于传统机器学习的方法将lda(latent dirichletallocation),lsa(latent semantic analysis)等主题分析算法与余弦相似度等短文本匹配算法相结合来解决单轮回复选择问题。但是,上述模型需要人工进行复杂的特征选择和特征提取工作,工作量大,并且效率较低。由于对话内容具有时序性的特点,早期使用深度学习的算法利用循环神经网络(recurrent neural networks)来处理上下文中蕴含的时序依赖。随着深度学习的不断发展,研究人员将各类深度神经网络应用于多轮对话研究中。对于多轮对话回复选择任务,最初的工作都是使用单一的网络结构或者将多个单一网络结构进行聚合来对上下文进建模。
4、2017年,vaswani等人提出了基于注意力机制的transformer模型。。transformer模型有着强大的语义理解能力,模型通过多头自注意力机制将所有的单词联系在一起,有效保证了远距离依赖信息的提取。zhou等人提出了一种深度注意力机制模型dam(deepattention matching network),dam使用了transformer中的attention结构来进行了句子表征,同时还设计了cross-attention来进行句子交互。在最后使用了三维卷积进行聚合。yuan等人提出msn (multi-hop selector network)模型,该模型结合dua模型和dam模型各自的优势,msn通过多跳选择器选择出与问题更相关的上下文。以上模型都是基于transformer强大的语义理解能力,大幅提升了回复选择模型的性能,但是这些模型依然存在无法从全局角度理解对话内容的问题,同时这些模型主要使用word2vec来生成静态词向量,这就造成了无法解决一词多义的问题。
5、近年来,随着预训练模型的提出,越来越多的使用成熟的预训练模型的方法也应用到多轮对话领域中。比如bert,roberta,albert和electra。预训练模型可以很好的和下游任务相结合,bert-vft首次将bert用于多轮回复选择任务,它将原来的匹配任务转换为一个分类任务,通过将历史对话和回复拼接在一起,通过添加特殊的[cls]token表示全局语义信息进行分类,实验结果体现出其优越的性能。随后越来越多的将预训练模型结合下游任务的方法被提出。gu等人提出了sa-bert模型,由于一段对话中往往有多个参与者,于是在数据输入过程中添加了对话人信息,通过预训练模型学习到对话人嵌入表征,加强模型对于不同对话参与者的语言风格的理解能力。li等人提出了dcm(deep contextmodeling)模型,在通过bert编码后,对上下文和回复进行深度的语义匹配学习,可以有效的提取上下文和回复中的语义相关性特征。这些模型通过大规模数据集的预训练,能够有效的学习到上下文和回复中的相关语义特征,进一步提升了模型多轮回复选择的能力,但是对于对话中蕴含的隐藏特征,比如时序信息,对话结构信息等,仍然缺乏充分的挖掘。
6、近年来,在预训练语言模型基础上通过添加辅助任务进行联合训练的方法获得了广泛关注。whang等人提出了三种不同的辅助任务以优化预训练模型使其更好的适应领域数据集,通过提出话语删除、话语插入、话语搜索三个辅助任务来学习对话中的潜在结构特征,从而进一步根据语义结构信息在多个候选回复中选取最优的结果。在此基础上,研究人员通过让预训练语言模型在微调前先学习领域数据的后训练策略来加强预训练语言模型在对话任务上的适配能力。此外,一些研究工作则提取预训练语言模型的输出做进一步精细匹配来过滤与回复不相关的噪音,这些研究工作在预训练语言模型的基础上加入新的数据或模块,或者在添加说话者嵌入的基础上再加入话题嵌入等方式来优化预训练语言模型,这些方法均取得了不错的效果。但是,多轮对话的上下文中存在许多的话题转换、跳跃的场景,不同轮次的对话中各自包含的信息也有多有少,这些复杂的场景都需要模型去更加细致的学习到多轮对话内部潜在的信息。
技术实现思路
1、本发明的目的在于提供一种领域数据增强与多粒度语义理解的多轮对话方法及系统,该方法及系统可以有效提高回复选择的准确性。
2、为实现上述目的,本发明采用的技术方案是:一种领域数据增强与多粒度语义理解的多轮对话方法,包括以下步骤:
3、步骤a:提取用户对话、用户对话涉及的回复,并标注用户对话中涉及的相关回复话语的标签,正样本为对话中正确的回复,负样本为不正确的回复,构建训练集u;
4、步骤b:使用训练集u,训练领域数据增强与多粒度语义理解的深度学习网络模型g,用于学习用户对话中和用户对话涉及的回复中的时序语义关系;
5、步骤c:将完整用户对话和用户对话涉及的回复输入到训练后的深度学习网络模型g中,得到关于完整用户对话的正确回复。
6、进一步地,所述步骤b具体包括以下步骤:
7、步骤b1:对训练集u中的每个训练样本进行编码,得到上下文的初始表征向量候选回复的初始表征向量以及标签y;
8、步骤b2:对训练集u中的每个训练正样本,截取最靠近回复的i句话语和正确的回复进行编码,得到上下文的初始表征向量正确回复的初始表征向量
9、步骤b3:对训练集u中的每个训练样本,随机选择上下文中的一句话,并将其中的词级顺序打乱后进行编码,得到初始表征向量对剩下的上下文中,在每句话的前面和最后一句话的后面添加新词[sti],并对这段上下文进行编码,得到初始表征向量
10、步骤b4:将表征向量和输入到k层双向gru网络中,学习并提取局部语义信息,得到用户对话的表征向量
11、步骤b5:将输入到sigmoid层,根据目标损失函数lossmain,利用反向传播方法计算深度学习网络模型g中的各参数的梯度,并利用随机梯度下降方法更新参数;
12、步骤b6:将上下文初始表征向量和正确回复的初始表征向量进行拼接,对于上下文和回复中的每个词以一定的概率进行掩码,得到掩码后的上下文回复向量输入到预训练语言模型中得到将输入到线性层,根据目标损失函数lossimg,利用反向传播方法计算深度学习网络模型g中的各参数的梯度,并利用随机梯度下降方法更新参数;
13、步骤b7:将上下文初始表征向量和话语表征向量拼接后输入到预训练与语言模型中得到将输入到sigmoid层,根据目标损失函数losssti,利用反向传播方法计算深度学习网络模型g中的各参数的梯度,并利用随机梯度下降方法更新参数;
14、步骤b8:根据目标损失函数loss,利用反向传播方法计算深度学习网络模型g中的各参数的梯度,并利用随机梯度下降方法更新参数;当深度学习网络模型g产生的损失值迭代变化小于设定阈值不再降低或者达到最大迭代次数,终止深度学习网络模型g的训练。
15、进一步地,所述步骤b1具体包括以下步骤:
16、步骤b11:遍历训练集u,u中的每个训练样本表示为d=(c,r,y),对训练样本d中的c和r进行分词处理,去除停用词和添加新词;
17、其中c为对话中的上下文,r为对应这段上下文中的回复,y为这个回复的标签,标签包括{0,1},0表示r不是对应c的回复,1表示r是对应c的回复;
18、上下文c经过分词及去除停用词后,在每句话语最后添加新词[eot],表示为:
19、
20、其中,为上下文c经过分词、去除停用词和添加新词后剩余词语中的第i个词,i=1,2,...,n,n为上下文c经过分词、去除停用词和添加新词后剩余的词语数量;
21、回复r经过分词及去除停用词后,在最后添加新词[eot],表示为:
22、
23、其中,表示回复r中经过分词、去除停用词和添加新词后剩余词语中的第i个词,i=1,2,...,m,m为回复r经过分词、去除停用词和添加新词后剩余的词语数量;
24、对于在上下文和回复中添加的新词[eot],用一个张量数组来记录将c和r拼接后其中[eot]的位置:
25、eot={eot1,eot2,...,eotq}
26、其中,eoti表示上下文和回复中的第i个eot,i=1,2,...,q;
27、步骤b12:对步骤b11得到的经过分词、去除停用词和添加新词后的上下文进行编码,得到上下文c的初始表征向量
28、其中,表示为:
29、
30、其中,为第i个词所对应的词向量,通过在预训练的词向量矩阵中查找得到,其中d表示词向量的维度,|v|是词典v中的词语数;
31、步骤b13:对步骤b11得到的经过分词、去除停用词和添加新词后的回复进行编码,得到回复r的初始表征向量
32、
33、其中,表示第i个词所对应的词向量,通过在预训练的词向量矩阵中查找得到,其中d表示词向量的维度,|v|是词典v中的词语数。
34、进一步地,所述步骤b2具体包括以下步骤:
35、步骤b21:将步骤b11中的上下文和b11中的回复按照话语级别进行拼接,得到c1={u1,u2,...,un,r},其中n表示上下文中含有的话语数量;截取上下文中最靠近回复r的i句话得到区间上下文回复c1={un-i,un-i+1,...,un,r},其中n表示上下文中的话语数量,i∈[3,5];
36、步骤b22:对步骤b21得到的区间上下文回复c1={un-i,un-i+1,...,un,r}在词粒度级别上进行编码,得到区间上下文的初始表征向量
37、
38、其中,表示中第i个词所对应的词向量,i=1,2,..,p,p是中词向量的个数通过在预训练的词向量矩阵中查找得到,其中d表示词向量的维度,|v|是词典v中的词语数。
39、进一步地,所述步骤b3具体包括以下步骤:
40、步骤b31:将步骤b11中的上下文按照话语级别进行合并,得到c2={u1,u2,...,un},其中n表示上下文中含有的话语数量;随机选择上下文c2中的一句话语ut并将其从c2中剥离出去:
41、
42、其中,表示话语ut中的第i个词,i=1,2,...q,q为话语ut中的词语数量;
43、在c2={u1,u2,...,un}中每句话的前面和最后一句话的后面添加新词[sti]得到:
44、
45、其中,表示添加新词后的c2中的第i个词,i=1,2,...n,n为c2中的词语数量;
46、对于c2中添加的新词[sti],用一个张量数组来记录每个[sti]的位置:
47、sti=[sti1,sti2,...,stin-1]
48、其中stii表示c2中第i个[sti]的位置,i=1,2,...,n-1;
49、步骤b32:对步骤b31中得到的去除目标话语ut的上下文c2进行编码,得到c2的初始表征向量
50、
51、其中,表示c2中所对应的词向量,i=1,2,...,n,n是中词向量的个数通过在预训练的词向量矩阵中查找得到,其中d表示词向量的维度,|v|是词典v中的词语数;
52、对步骤b31中得到的目标话语中的词进行随机打乱并编码,得到ut的初始表征向量
53、
54、其中,表示ut中所对应的词向量,i,j=1,2,...,m;i≠j,n是中词向量的个数通过在预训练的词向量矩阵中查找得到,其中d表示词向量的维度,|v|是词典v中的词语数。
55、进一步地,所述步骤b4具体包括以下步骤:
56、步骤b41:将表征向量和表征向量输入到预训练语言模型bert中,输出h1,结合张量数组eot得到每个[eot]词向量所在的位置,并将这些[eot]词向量拼接起来得到heot;
57、其中,h1,heot分别表示为:
58、
59、
60、其中,是预训练语言模型bert第i个词向量的输出,的计算公式如下:
61、
62、其中,x是上下文表征向量和回复表征向量中的每个词向量;
63、步骤b42:将输入到2层的双向gru中,得到局部语义信息的融合表征向量
64、
65、其中是双向gru第i个词向量的输出,的计算公式为:
66、
67、其中是heot中的每个词向量。
68、进一步地,所述步骤b5具体包括以下步骤:
69、步骤b51:将步骤b42得到的输入到一个全连接层中进行降维,并通过sigmoid激活函数进行计算概率分布,计算过程如下:
70、
71、其中w是可训练参数,b是偏置,σ(·)是sigmoid激活函数;
72、步骤b52:将步骤b51得到的概率分布g(c,r)输入到损失函数中计算损失并进行迭代更新,在回复选择主任务的微调过程中使用交叉熵作为损失函数:
73、
74、使用梯度累加策略,在累计5个批次后更新梯度;模型使用adamw算法作为梯度下降的优化器。
75、进一步地,所述步骤b6具体包括以下步骤:
76、步骤b61:将步骤b22得到的区间上下文表征向量中的每一个词向量以概率q进行掩码操作,得到被掩码后的区间上下文表征向量:
77、
78、其中,是每个词向量被掩码后的向量,i=1×q,2×q,...,p×q;
79、步骤b62:将得到掩码后的上下文回复向量输入到预训练语言模型中得到将输入到线性层,根据目标损失函数lossimg,利用反向传播方法计算深度学习网络模型g中的各参数的梯度,并利用随机梯度下降方法更新参数;
80、
81、
82、其中w1是可训练参数,b1是偏置,σ(·)是sigmoid激活函数;用交叉熵作为损失函数计算损失值,通过梯度优化算法adam进行学习率更新,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型;
83、其中,最小化损失函数loss的计算公式如下:
84、
85、其中,θ是bert中编码器部分的参数,θ1是区间掩码生成任务中在编码器上所接的输出层中的参数;
86、进一步地,所述步骤b7具体包括以下步骤:
87、步骤b71:将步骤b32得到的上下文表征向量和步骤b33得到的目标话语表征向量进行拼接得到其中表示一种级联的操作;
88、将输入到预训练模型中得到然后通过全连接层计算出sti张量数组中的位置的得分;
89、
90、
91、其中w2是可训练参数,b2是偏置,σ(·)是sigmoid激活函数;
92、步骤b72:用交叉熵作为损失函数计算损失值,通过梯度优化算法adam进行学习率更新,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型;
93、其中,最小化损失函数loss的计算公式如下:
94、
95、其中,labels={0,0,..1,0...0}来表示sti数组中[sti]i位置的标签,其中1表示是该插入的地方,0则相反。
96、进一步地,所述步骤b8中,在微调的同时,多轮对话模型使用多任务联合训练框架,将预训练模型的参数导出,在两个辅助任务优化的过程中学习不同粒度的时序语义信息并且更加适应当前领域数据集;在微调的过程中同时优化两个辅助任务与一个主任务,因此,模型的完整损失函数如下:
97、loss=lossmain+αlossimg+βlosssti
98、其中α,β是两个超参数,分别用于控制两个辅助任务对多轮对话模型的影响力。
99、本发明还提供了一种采用上述方法的多轮对话系统,包括:
100、数据收集模块,用于提取用户对话、用户对话涉及的回复,并标注对话中相关回复话语的标签,构建训练集;
101、预处理模块,用于对训练集中的训练样本进行预处理,包括分词处理、去除停用词和添加新词;
102、编码模块,用于在预训练的词向量矩阵中查找经过预处理的对话上下文中的词向量,得到上下文的初始表征向量和回复的初始表征向量;
103、网络训练模块,用于将不同数据处理得到的上下文的初始表征向量和回复的初始表征向量输入到深度学习网络中,深度学习网络中的预训练语言模型共享参数,得到上下文和回复的多粒度表征向量并以此训练深度学习网络,利用该表征向量属于某一类别的概率以及训练集中的标注作为损失,以最小化损失为目标来对整个深度学习网络进行训练,得到领域数据增强和多粒度语义理解的深度学习网络模型;
104、回复选择模块,利用训练好的领域数据增强和多粒度语义理解的深度学习网络模型对输入的对话上下文和候选回复进行分析处理,输出候选回复中最匹配当前上下文内容的回复。
105、与现有技术相比,本发明具有以下有益效果:提供了一种领域数据增强与多粒度语义理解的多轮对话方法及系统,该方法及系统使用多任务学习框架,利用区间掩码生成任务,通过对上下文和回复中的固定大小的区间,并对区间内的词进行随机掩码生成,来帮助模型更好的适应当前领域数据集;利用token乱序插入的方法,训练bert多粒度的学习到上下文之间的语义关系;通过这项任务,模型可以从多粒度的角度学习到蕴含在上下文之间的语义关系;最后利用双向特征融合机制融合不同的局部语义信息以增强回复选择的能力,能够有效提高回复选择的准确性。
- 还没有人留言评论。精彩留言会获得点赞!