一种基于语义一致性的半监督短视频分类方法
本发明涉及短视频动作、事件分类领域,尤其涉及一种基于语义一致性的半监督短视频分类方法。
背景技术:
1、随着移动智能设备普及和网络技术的飞速发展,短视频逐渐取代传统图文成为人们日常生活中重要的信息载体。这些短视频本身相比传统视频,具有时长短、内容复杂多样、信息碎片化等特点。短视频动作分类作为视频内容理解的子任务之一,主要解决短视频中人物动作的理解与建模,是视频复杂事件理解的基础,相关表示学习也在视频分类推荐、版权保护、内容审查等下游应用中有重要作用。近年来,得益于计算设备性能不断提高,人工智能相关技术快速发展落地,深度学习在视频内容理解领域得到了广泛应用。一些深度算法逐渐代替了传统机器学习,能够学习到视频更加完备的深度表征,具体表现也更加出色。然而深度学习大多数方法的训练需要大量标签,而数量庞大的视频标注需要大量的人工成本,因此只需要少量标签就可以进行训练的半监督学习具有重要现实意义。
2、在视频分析上,深度方法主要分为三类,基于双流网络的方法、基于3d卷积神经网络的方法、基于2d卷积神经网络的方法。基于光流网络的方法主要通过提取视频光流特征学习时间维度信息。基于3d卷积网络的方法则直接在时间维度扩展卷积核,通过卷积同步学习时空信息。基于2d卷积网络的方法使用二维卷积学习视频帧空间特征,之后通过对视频帧进行时序建模,挖掘时间维度信息。前两类方法虽然取得了较好的效果,但光流的计算以及三维网络的计算和训练需要巨大的成本;基于二维卷积网络提取关键帧特征的方法则需要更多的考虑时间维度信息的交互与融合。
3、目前的半监督学习研究主要集中在图像领域,视频领域实际研究较少。主流的半监督学习算法主要分为两种,基于伪标签的方法和基于一致性正则化的方法。基于伪标签的方法致力于提高生成伪标签的置信度,而基于正则化的方法则通过扰动优化学习促使决策边界设定在低密度区域。图像上的半监督算法主要挖掘同一图片在不同样本增强扰动下模型预测的不变性,而视频本身由大量视频帧构成,视频帧之间具有高度的语义相关性和相互作用,挖掘视频内部监督信号是视频上的半监督学习发展方向。
4、尽管这些现有方法在视频分类上取得了不错的成效,但视频半监督学习仍处于发展阶段。因此提出一种基于半监督学习的短视频学习方法,深度挖掘利用视频内帧间语义一致性信息,同时在视频帧间进行充分的信息交互融合提取高阶语义信息进行分类是有意义的。
技术实现思路
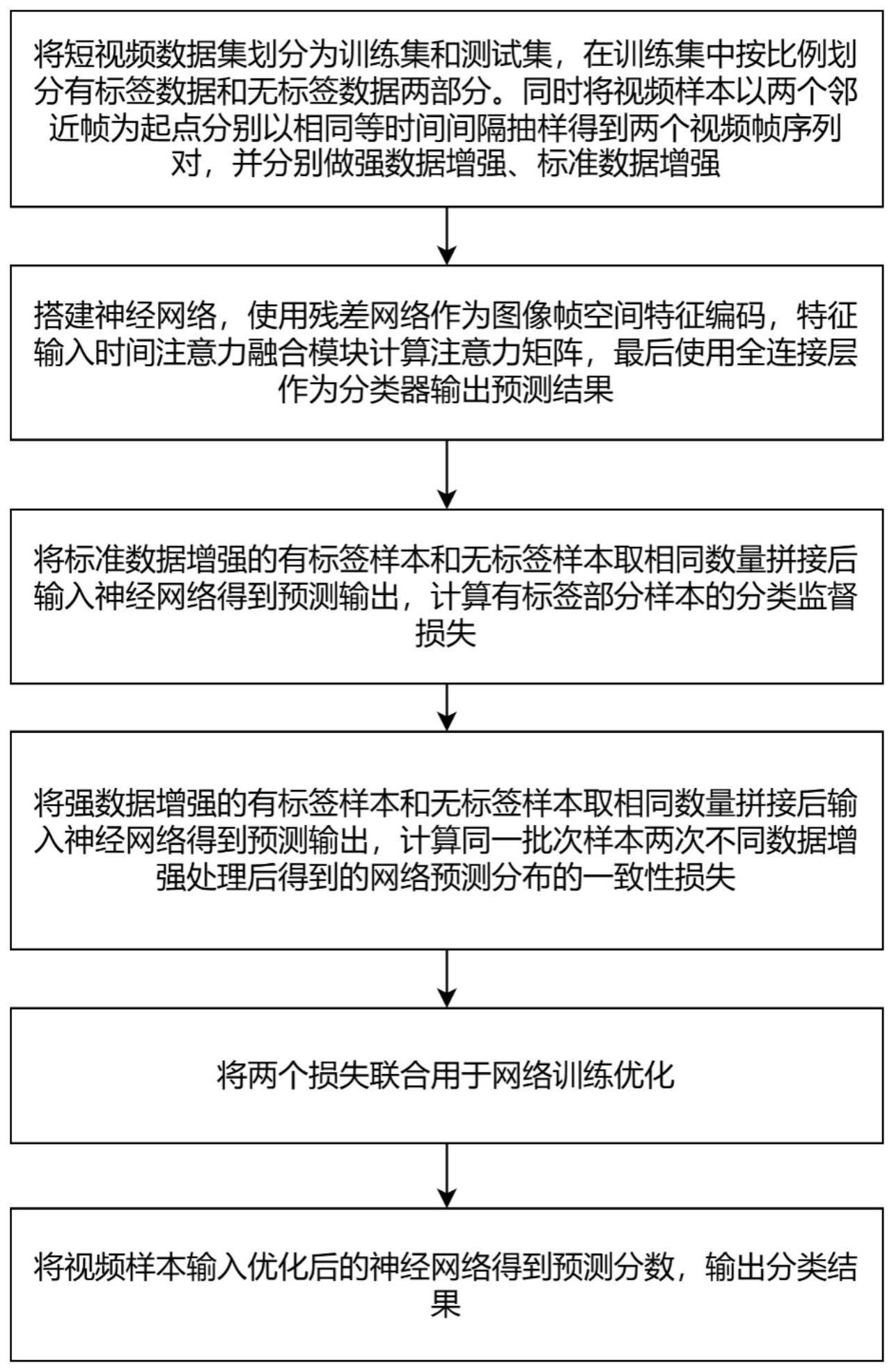
1、本发明提供了一种基于语义一致性的半监督短视频分类方法,本发明输入的视频通过二维残差网络学习视频帧空间特征,并利用注意力机制在时间维度学习每个视频帧对于该视频的重要程度,从而获得视频级高级语义信息;通过引入半监督学习,利用短视频邻近帧相似性特点,构造同一短视频两个关键帧序列对,在学习有标签样本的监督信号的同时对使用两种不同强度数据增强后的这两个帧序列的网络输出预测分布进行约束,使模型学习到更健壮的视频级语义,提高在只有少量有标签样本情况下的分类精度,详见下文描述:
2、一种基于语义一致性的半监督短视频分类方法,所述方法包括:
3、利用视频邻近帧相关性,将有标签数据和无标签数据分别以t0,t0+τ帧为起点按等时间间隔t抽取关键帧得到两个帧序列,并分别做强数据增强、标准数据增强;
4、搭建由空间特征学习模块、时间注意力融合模块、分类器模块组成的神经网络;
5、标准数据增强后的有标签样本和无标签样本取相同数量拼接后输入神经网络并计算有标签部分的分类损失;将强数据增强后的有标签样本和无标签样本取相同数量拼接后输入神经网络,对网络输出的预测分布计算一致性损失;
6、将分类损失和一致性损失联合用于神经网络的优化训练;将视频样本输入优化后的神经网络输出相应预测分数,得到最终视频分类结果。
7、其中,所述搭建由空间特征学习模块、时间注意力融合模块、分类器模块组成的神经网络为:
8、空间特征学习模块使用残差网络进行空间特征编码,将视频帧空间特征序列输入至时间注意力融合模块;
9、时间注意力融合模块在学习到的视频帧空间特征序列中拼接位置信息编码用于每个关键帧时间关系的学习,同时加入类别信息编码用于对整个序列的时间上的语义信息融合;
10、学习序列内关键帧之间的相关性程度,计算序列内每个视频帧对该序列所有视频帧的关联性矩阵,得到具有全局注意力信息的帧特征序列;
11、使用帧特征序列求均值融合视频帧信息,得到视频级语义表征,使用语义特征联合学习到的类别编码信息一同输入由全连接层组成的分类器模块,输出最终分类结果。
12、所述分别做强数据增强、标准数据增强为:
13、将所有视频样本以t0,t0+τ为起始,等时间间隔t抽取n帧,得到每个样本两个关键帧序列集合和
14、其中,fi为视频样本第i帧图像,对于xw中图像做相同的标准数据增强操作,对xs使用randaugment算法做多次强数据增强操作。
15、所述加入类别信息编码用于对整个序列的时间上的语义信息融合为:
16、将样本xm输入残差网络f(·)学习每一帧空间外观特征,得到视频特征矩阵n为帧数,d为网络f(·)输出特征维度;
17、在视频特征矩阵第一维度位置拼接一个随机初始化的类别信息编码位得到代表视频的特征矩阵再加上随机初始化的位置编码信息得到最终的特征矩阵。
18、所述分类损失为:
19、将标准数据增强后的有标签样本和无标签样本取相同数量拼接后输入神经网络,神经网络输出预测分布并得到结果,使用交叉熵计算有标签部分预测结果与实际标签之间的误差损失lcls。
20、所述一致性损失为:使用js散度计算网络对同一样本在两次不同数据增强处理后的预测分布之间的一致性损失lcons;
21、
22、其中,kl表示kl散度,计算方式如下:
23、
24、最终两个损失联合用于网络的训练优化,总的损失如下:
25、l=lcls+λ·lcons
26、其中,λ为可调节参数。
27、本发明提供的技术方案的有益效果是:
28、1、区别于监督学习,引入半监督学习可以在只有少量数据有标记的情况下,利用数据自身特点挖掘深度特征,提高短视频分类精度;本方法利用同一视频内部帧之间相关性,构造关键帧序列对用于半监督一致性学习,相比图像本身做图像增强能更大程度挖掘视频内在语义信息,为视频领域半监督学习提供新思路;
29、2、本方法使用端到端的学习思路,使用视频表达语义最丰富的视觉模态学习分类,模型基于现有在大规模图片数据集上优化后的残差网络,在视频分类任务上进行微调,即可实现对短视频的特征学习;相比三维卷积神经网络,本方法模型在一定程度上避免了三维卷积网络训练需要大规模数据集且从头训练困难等问题;
30、3、区别于传统循环神经网络进行时间维度学习,本方法基于注意力机制融合策略,学习每一帧与视频中所有帧的关联相似程度,激励模型理解跨时间全局动作事件信息;通过额外的位置编码可以帮助模型学习视频内关键帧之间的时间信息,另一方面类别编码则可以帮助融合整个序列的语义信息;最后使用学习到的类别编码与特征均值联合用于分类,使判别结果更具有健壮性。
- 还没有人留言评论。精彩留言会获得点赞!