本发明属于自杀危机预测领域,尤其涉及一种基于双层lstm模型的自杀危机预测系统。
背景技术:
1、近年来,抑郁症作为一种常见且严重的精神疾病引起了人们的广泛关注。与必须依靠药物治疗的疾病不同,抑郁症这类心理疾病可以通过与患者沟通缓解病情。最近一项研究表明,有自杀意念或抑郁心理的用户很可能会通过社交媒体向他人倾诉,社交媒体中的匿名交流有助于提高个人隐私信息披露的意愿,让患者更愿意分享一些隐私信息。及早识别有自杀危机的抑郁症患者,并由心理学家进行适当及时的干预,对预防抑郁症患者自杀至关重要。
2、目前已经有一些方法利用抑郁症患者在社交媒体上发布的文本对自杀危机进行预测,大多数相关研究采用传统的机器学习方法,即通过特征工程对数据进行分类。其中,支持向量机、贝叶斯、逻辑回归等是传统机器学习中常用的方法。例如,cheng等研究从中文文本数据中挖掘自杀危机或情绪困扰,并使用机器学习方法svm基于微博帖子识别自杀危机。近年来,随着深度学习热潮的到来,一些学者开始使用深度学习方法开展自杀危机预测的研究。与传统的机器学习方法不同,深度学习不需要基于文本提取特征构建特征工程,而是将文本编码为计算机可识别的语言,并直接输入到模型中进行预测。例如,tadesse等将深度学习方法lstm和cnn结合应用于检测reddit社交媒体中的自杀意念,利用lstm层捕获文本之间的长距离依赖关系,并使用卷积层提取特征。实验结果表明,无论是单个lstm或cnn,还是复合模型lstm-cnn,其效果都优于基于特征工程的传统机器学习方法。此外,以往预测自杀危机的研究的数据集大多是基于用户在社交媒体上单期的发帖文本内容,即只关注一条文本数据进行预测,忽略了用户历史的发帖信息对于预测自杀危机的作用。同时,当考虑用户复杂的历史动态在线社交文本信息进行自杀危机预测时,传统的机器学习和深度学习模型无法准确地捕捉历史序列信息的特征,进而无法准确预测。
3、综上,现有自杀危机预测的技术仍有以下不足:第一,当前基于社交媒体平台的自杀危机预测研究主要集中在仅考虑用户的单条在线社交文本,而忽略了用户历史动态的在线社交文本及相关信息。通常,有自杀危机的人不会突然从良好的心态转变为自杀想法,在有自杀念头之前,他们就已经处于情绪痛苦之中。单条在线社交文本内容表达是片面的,不能充分反映用户的情绪,因此难以准确地预测用户是否有自杀危机;第二,对于考虑用户复杂的历史动态在线社交文本信息的自杀危机预测模型,传统的机器学习和深度学习模型无法准确地捕捉历史序列信息的特征,使得预测模型存在进一步提升的空间。
技术实现思路
1、为解决上述问题,本发明提供一种基于双层lstm模型的自杀危机预测系统,充分考虑用户历史动态在线社交文本信息,能够更准确地识别社交媒体中具有自杀危机的用户。
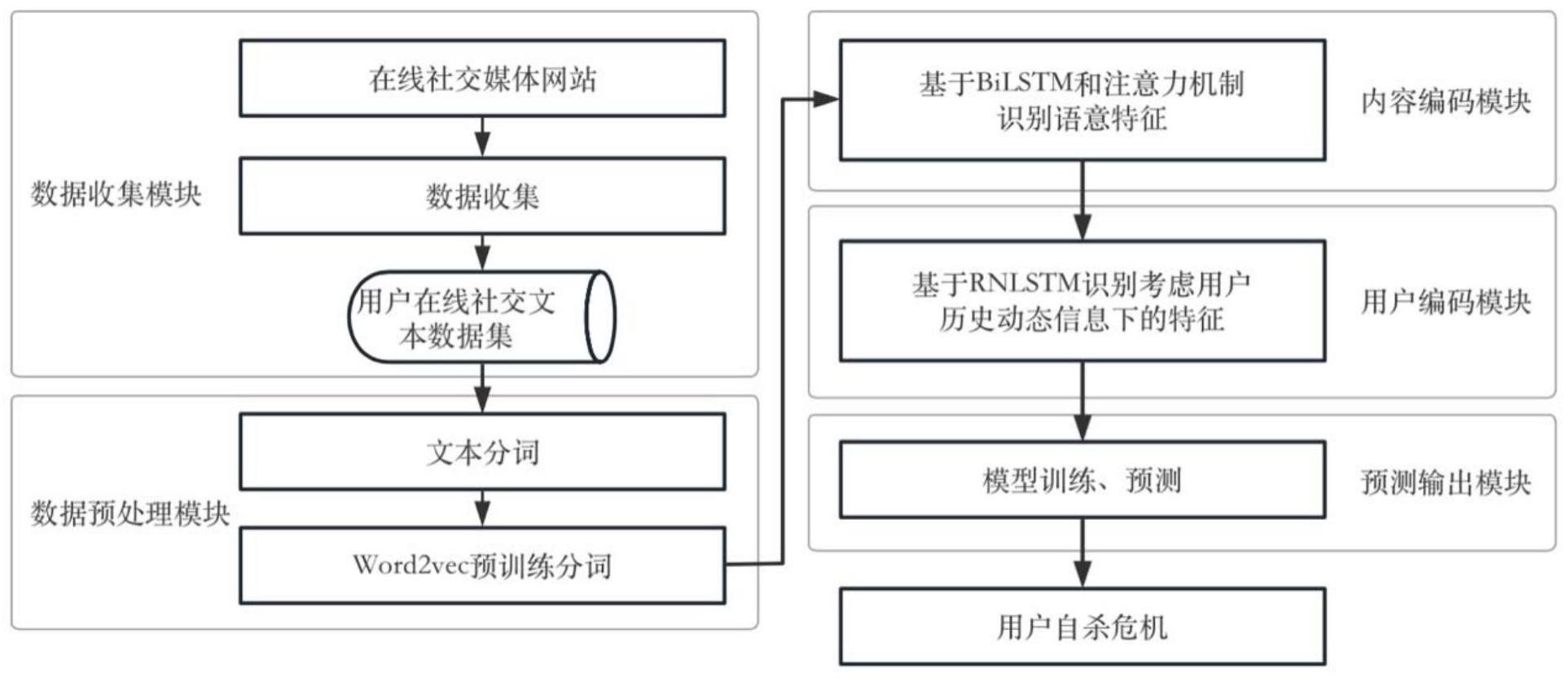
2、一种基于双层lstm模型的自杀危机预测系统,包括数据收集模块、数据预处理模块、内容编码模块、用户编码模块以及预测输出模块;
3、所述数据收集模块用于收集待评估用户的历史发帖内容;
4、所述数据预处理模块用于对历史发帖内容进行分词,得到历史发帖内容中所有分词的词向量;
5、所述内容编码模块基于bilstm逐一获取各词向量对应的隐藏状态向量,再基于注意力机制层剔除各隐藏状态向量中的冗余信息,得到各词向量的加权隐藏状态向量;
6、所述用户编码模块采用衰减函数e-n对各加权隐藏状态向量进行加权,得到信息特征向量,其中,n为待评估用户的历史发帖内容得到的回复数量;
7、所述预测输出模块用于根据信息特征向量获取待评估用户的自杀危机预测结果。
8、进一步地,所述自杀危机预测系统的训练方法为:
9、s1:所述数据收集模块用于收集不同用户的历史发帖内容作为初始数据集,其中,初始数据集中的历史发帖内容带有无自杀危机标签或者自杀危机标签;
10、s2:所述数据预处理模块用于对初始数据集中的历史发帖内容进行分词,得到历史发帖内容中所有分词的词向量,然后按照设定比率将词向量划分为训练集和测试集;
11、s3:所述内容编码模块基于bilstm逐一获取各词向量对应的隐藏状态向量,再基于注意力机制层剔除各隐藏状态向量中的冗余信息,得到各词向量对应的加权隐藏状态向量;
12、s4:分别将各用户对应的加权隐藏状态向量进行拼接得到各用户对应的特征向量后,所述用户编码模块采用衰减函数e-ni分别对各用户对应的特征向量进行加权,得到各用户对应的信息特征向量,其中,ni为初始数据集中第i个用户的历史发帖内容得到的回复数量,且i=1,2,3,…,m,m为初始数据集中的用户数;
13、s5:将训练集中各用户对应的信息特征向量作为初始预测输出模块的输入,训练集中各用户的历史发帖内容对应的标签作为初始预测输出模块的输出,以此训练预测输出模块;
14、s6:将测试集中各用户对应的信息特征向量作为训练得到的预测输出模块的输入,并将训练得到的预测输出模块输出的各用户的自杀危机预测结果与测试集中各用户的历史发帖内容对应的标签作对比,若正确率大于设定阈值,则此时的自杀危机预测系统为最终的自杀危机预测系统,若正确率不大于设定阈值,则重新获取初始数据集并重新执行步骤s1~s6,直到得到最终的自杀危机预测系统。
15、进一步地,所述数据预处理模块采用word2vec预训练对历史发帖内容进行分词。
16、进一步地,所述内容编码模块基于bilstm逐一获取各词向量对应的隐藏状态向量具体为:
17、将各词向量分别从正向和反向输入bilstm模型,分别得到表征分词上文特征的正向隐藏状态以及分词下文特征的后向隐藏状态然后拼接两个隐藏向量得到表示历史发帖内容的上下文特征的隐藏状态向量
18、所述基于注意力机制层剔除各隐藏状态向量中的冗余信息,得到各词向量的加权隐藏状态向量具体为:
19、构建注意力因子a如下:
20、a=softmax(wa×tanh(h))
21、其中,softmax为逻辑回归函数,wa为设定权值,tanh()为激活函数;
22、基于注意力因子a对隐藏状态向量h进行如下加权:
23、v=h×at
24、其中,v为加权隐藏状态向量,t为转置。
25、进一步地,信息特征向量的获取方法如下:
26、基于lstm构建输入门因子i(t)、遗忘门因子f(t)、输出门因子o(t)如下:
27、i(t)=σ(wxi v(t)+whi(h(t-1)×e-n)+bi)
28、f(t)=σ(wxf v(t)+whf(h(t-1)×e-n)+bf)
29、o(t)=σ(wxo v(t)+who(h(t-1)×e-n)+bo)
30、其中,σ(·)为第一激活函数,wxi为输入门中加权隐藏状态向量的权重,whi为输入门中隐藏状态向量的权重,wxf为遗忘门中加权隐藏状态向量的权重,whf为遗忘门中隐藏状态向量的权重,wxo为输出门中加权隐藏状态向量的权重,who为输出门中隐藏状态向量的权重,bi为输入门的偏置量,bf为遗忘门的偏置量,bo为输出门的偏置量,上标t和t-1表示第t时刻和第t-1时刻;
31、根据输入门因子i(t)、遗忘门因子f(t)、输出门因子o(t)构建记忆单元c(t)如下:
32、
33、其中,操作符表示元素相乘,tanh()为第二激活函数,wxc为记忆单元中加权隐藏状态向量的权重,whc为记忆单元中隐藏状态向量的权重,bu为记忆单元的偏置量;
34、根据输出门因子o(t)与记忆单元c(t)得到第t时刻的信息特征向量h(t)如下:
35、
36、判断当前的第t时刻是否为用户最后的发帖时间,若为是,则当前次迭代的信息特征向量h(t)为最终的信息特征向量,若为否,则进入下一次迭代,直到当前的第t时刻满足设定的条件。
37、有益效果:
38、1、本发明提供一种基于双层lstm模型的自杀危机预测系统,通过先采用bilstm和注意力机制逐一提取在线社交文本中的语意信息,再使用一种基于lstm改进的方法,将用户的历史发帖内容得到的回复数量考虑在内,从而将用户历史动态的在线社交文本信息整合,克服了当前自杀危机预测方法没有充分考虑用户历史动态在线社交文本信息的缺点,挖掘了历史在线社交文本信息中异质的特征,提升了预测能力,并取得了更好的自杀危机预测结果。
39、2、本发明提供一种基于双层lstm模型的自杀危机预测系统,在当前基于社交媒体平台的自杀危机预测研究主要集中在仅考虑用户的单条在线社交文本,而忽略了用户历史动态的在线社交文本及相关信息的缺陷下,全面考虑用户的历史动态在线社交文本信息,并根据用户当期的在线社交文本、用户历史在线社交文本及其被回复数量等信息构建了考虑历史动态信息的自杀危机预测模型,能够更准确地识别社交媒体中具有自杀危机的用户。
40、3、本发明提供一种基于双层lstm模型的自杀危机预测系统,在传统的机器学习和深度学习模型无法准确地捕捉用户历史社交文本序列信息的特征的缺陷下,基于心理学研究,对善于捕捉序列特征的lstm方法进行改进,设计了一个与历史发布问题的回复数量有关的rnlstm,以此捕捉动态复杂的历史特征,从而得到更好的自杀危机预测效果。