一种基于多目标优化的视频摘要方法
本发明属于视频摘要,具体涉及一种基于多目标优化的视频摘要方法。
背景技术:
1、视频摘要技术通过计算机分析并理解视频的主要内容,从原始视频中提取给定视频序列的关键子集,如关键帧或关键图像作为摘要内容,使得摘要后的视频时长缩短,保留用户认为重要的部分,可以让观看者快速浏览视频的主要内容,按照生成的摘要形式可以分为静态视频和动态视频摘要。静态视频摘要就是关键帧选择,会提取一系列帧组合成摘要,使用户通过少数视频帧对视频建立基本认知。而动态视频摘要是关键镜头选择,会选择一系列具有代表性的镜头组成一个简短的视频,这些镜头由较短时间内的连续帧组成,镜头按照时间顺序显示。
2、海量视频数据对视频网站和用户都提出了挑战,对网站来说,仅仅依靠视频上传者提供的标题与标签,对视频进行归类、存储和检索,需要大量的存储设备与计算资源;对于用户而言,准确找到所需视频花费的时间大大增加。因此,从海量视频数据中快速理解并提取视频摘要能够大大降低网站或本地的视频存储要求,对视频内容的理解与检索效率也大为提升。视频摘要技术已经广泛应用于视频存储,视频预览,视频监控等领域中。
3、现有视频摘要方法大致分为以下几类:①聚类算法:这类算法利用一些相似性度量对具有相似内容的视频帧或镜头进行聚类,然后提取聚类中心处的视频帧或镜头组成视频摘要;②字典学习算法:通常需要代表在线性重建的意义上近似数据矩阵,为保证稀疏性需要l1正则化构造损失函数,并交替迭代求解;③神经网络类算法:此类算法通常将用户生成的摘要结果作为正例,使用双向长短期记忆网络估计视频帧的重要性分数,或将视频摘要表示为序列到序列的学习过程,注意力机制也被引入该方法。
4、但是对于上述几类视频摘要方法,在进行视频摘要提取过程中,聚类算法的聚类速度较慢导致无法快速实现视频摘要的提取,而且聚类中心个数无法准确确定导致提取的视频摘要不能全面的反映视频内容;字典学习算法所得解空间信息有限,容易陷入局部最优,也会导致提取的视频摘要不能全面的反映视频内容;神经网络类算法常需要根据人工创建的摘要学习,而不同用户生成的摘要有所不同,依赖于高质量的人工摘要,且模型训练时间较长,导致无法快速实现视频摘要的提取。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于多目标优化的视频摘要方法。本发明要解决的技术问题通过以下技术方案实现:
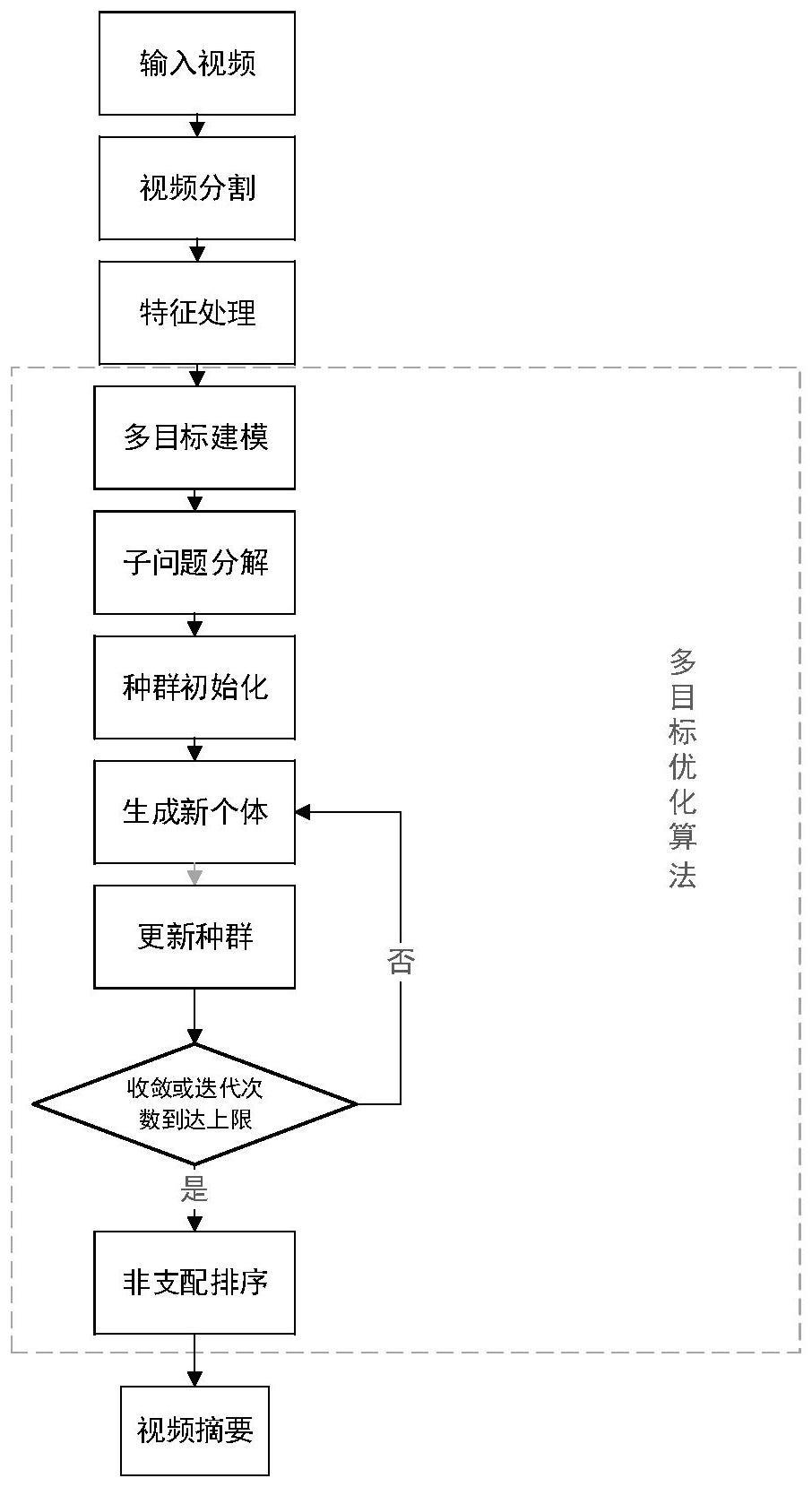
2、本发明提供了一种基于多目标优化的视频摘要方法,包括:
3、步骤1:获取待生成摘要的原视频;
4、步骤2:利用核时域分割对所述原视频进行视频镜头分割,得到多个不相交的子镜头;
5、步骤3:对所述原视频进行采样抽帧,得到第一采样帧集合,提取所述第一采样帧集合中所有采样帧对应的特征向量,构建特征词典;
6、步骤4:根据所述特征词典,构建视频摘要生成的多目标优化模型,其中,所述多目标优化模型表示为:
7、min:f(i)=(f1(i),f2(i))t;
8、
9、其中,min表示多目标优化模型的优化方向,f(i)表示多目标优化模型,i表示选择向量,x表示特征词典,b表示选择子集,f1表示选择子集对原视频的重构误差,f2表示选择子集的稀疏性,t表示矩阵转置,ii表示第i个子镜头的选中结果,li表示第i个子镜头的长度,length表示原视频中包含图像帧的数量,s表示子镜头的个数,表示f范数运算;
10、步骤5:利用基于分解的多目标优化算法,得到所述多目标优化模型的非支配解集合;
11、步骤6:确定所述非支配解集合中的最优解,根据所述最优解得到视频摘要结果。
12、在本发明的一个实施例中,所述步骤2包括:
13、步骤2.1:对所述原视频进行采样抽帧,得到第二采样帧集合,提取所述第二采样帧集合中所有采样帧的sift特征,根据所述sift特征计算得到对应的fisher vector特征作为所述第二采样帧集合中所有采样帧的特征描述符,计算每一对特征描述符的相似度,得到相似度矩阵g;
14、步骤2.2:将所述第二采样帧集合中所有采样帧分别作为分段的起始帧对所述第二采样帧集合进行分段,并按照下式计算对应的分段方差,
15、
16、其中,v表示分段方差,a表示起始帧为第二采样帧集合中的第a帧,a=0,1,…n-1,b表示分段中包含的帧数量,b=1,2,…,n-a,n表示第二采样帧集合中包含采样帧的数量,gx,y表示相似度矩阵g中第x行第y列的元素;
17、步骤2.3:构建目标函数并对其进行优化,以降低整体段内方差以及避免过多分段,其中,所述目标函数为:
18、
19、
20、其中,min表示目标函数的优化方向,jm,n表示目标函数,m表示分段数量,n表示结束帧为第二采样帧集合中的第n帧,lm,n表示前n帧分为m段的整体段内方差,p(m,n)表示前n帧分为m段的惩罚项;
21、步骤2.4:利用动态规划算法最小化段内方差之和,迭代地计算前n帧分为m段的整体段内方差为:
22、lm,n=mint=m,m+1,...,n-1(lm-1,t+vt,n),l0,n=v0,n;
23、其中,t表示第m个分段的起始帧下标,n=1,2,…,n,m=1,2,…,n,当无分段时,整体段内方差l0,n为v0,n;
24、通过最小化所述目标函数,得到最佳视频分段数量m*,
25、m*=argminm=1,2,...,njm,n;
26、式中,argmin表示求取目标函数jm,n最小时对应的m值;
27、步骤2.5:根据所述最佳视频分段数量m*,利用回溯法逐个确定变点位置,根据所述变点位置对所述原视频进行视频镜头分割,得到多个不相交的子镜头,其中,从后向前逐个确定的变点位置为:
28、
29、
30、其中,ti-1表示第i-1个变点位置,得到的子镜头的起始帧的下标为
31、在本发明的一个实施例中,所述步骤3包括:
32、步骤3.1:对所述原视频进行采样抽帧,得到第一采样帧集合;
33、步骤3.2:利用深度学习神经网络googlenet对所述第一采样帧集合中所有采样帧进行特征提取,得到对应的特征向量,将所有特征向量组成得到所述特征词典。
34、在本发明的一个实施例中,所述步骤5包括:
35、步骤5.1:设定子问题数目pop,构造多个单目标子问题为:
36、
37、其中,gte(i|λ,z*)表示权重向量λ与参考点z*所对应的单目标子问题,表示权重向量,表示参考点,代表优化方向,其中为种群中所有个体对应的目标函数f1的最小值,为种群中所有个体对应的目标函数f2的最小值;
38、步骤5.2:设定邻域子问题数目t,根据权重向量间的距离,为每一个单目标子问题subpi寻找与其权重向量最接近的t个权重向量所对应的子问题,作为最近的邻域子问题,将所述邻域子问题的索引记为该单目标子问题的邻域集合c{i};
39、步骤5.3:初始化种群计算所述初始化种群中每一个个体ii对应的目标向量f(ii),并将目标向量的集合记为
40、步骤5.4:根据所述邻域集合c{i},对种群中的每一个个体ii进行重组和反转变异,得到新的种群以及对应的新的目标向量集合;
41、步骤5.5:重复步骤5.4对种群进行迭代更新,直至满足迭代终止条件得到最终的种群以及对应的最终的目标向量集合;
42、步骤5.6:将非支配解及非支配解对应的目标向量分别从最终的种群和最终的目标向量集合中移除,得到所述多目标优化模型的非支配解集合以及对应的非支配解的目标向量集合。
43、在本发明的一个实施例中,所述步骤5.4包括:
44、步骤5.4.1:对种群中的每一个个体ii,从对应的所述邻域集合c{i}中任选两个邻域子问题索引j,k,采用多点交叉策略对邻域子问题ij和ik进行重组,得到新个体其中,新个体中第d个元素为:
45、
46、其中,r表示随机向量,rd表示随机向量中的第d个元素,其取值在[0,1]区间内,cr=0.5,ijd表示ij的第d个元素,ikd表示ik第d个元素;
47、步骤5.4.2:对每一个新个体中的每个元素进行反转变异得到更新后的新个体新个体中第d个元素为:
48、
49、其中,表示随机向量,表示随机向量中的第d个元素,其取值在[0,1]区间内,m为控制变异概率的参数;
50、步骤5.4.3:对每个新个体的所有邻域子问题l∈c{i},如果则令更新种群和目标向量集合,得到新的种群以及对应的新的目标向量集合。
51、在本发明的一个实施例中,所述步骤5.6包括:
52、步骤5.6.1:初始化非支配解集合及其对应的非支配解的目标向量集合
53、步骤5.6.2:对于最终的种群ps中任意的个体ii,若存在使得ii<i,则令ps=ps/ii;若不存在使得ii<i,则令ps=ps/ii,且
54、同时,若存在使得i'<ii,则令其中,i'<ii,当且仅当
55、
56、步骤5.6.3:重复步骤5.6.2,直到最终的种群得到非支配解集合及其对应的非支配解的目标向量集合
57、在本发明的一个实施例中,所述步骤6包括:
58、步骤6.1:确定所述非支配解集合中的最优解,其中,
59、当所述非支配解集合中的非支配解个数超过2个,则对非支配解集合中的每个非支配解,在其帕累托前沿的左右邻域分别寻找两组最近的点,在两组点中分别任取一个点,与该非支配解的点构成一个角,得到对应的四个角,计算四个角的平均角度;比较所有非支配解的平均角度,将平均角度最小的非支配解确定为帕累托前沿的膝点,该非支配解作为非支配解集合中的最优解;
60、当所述非支配解集合中有2个非支配解,则选择对原视频的重构误差较小的非支配解作为最优解;
61、当所述非支配解集合中有1个非支配解,则将该非支配解作为最优解;
62、步骤6.2:根据所述最优解对所述原视频进摘要提取,得到视频摘要结果。
63、与现有技术相比,本发明的有益效果在于:
64、1.本发明的基于多目标优化的视频摘要方法,采用基于分解的多目标优化算法对视频摘要任务进行稀疏建模,为了种群更快的收敛,给每一个个体分配一个权向量,利用多个渐变的不同权向量将该多目标优化问题分解为多个单目标优化问题来同时求解,同时进一步,使用一种邻近权向量的替换策略,提高演化算法的搜索效率,可以快速实现视频摘要的提取,提高视频摘要提取的准确性使得视频摘要能全面的反映视频内容。
65、2.本发明的基于多目标优化的视频摘要方法,通过在视频摘要领域引入多目标优化算法,参考基于字典学习的视频摘要方法设置目标函数,可以在每一代种群迭代过程中,引导个体向提高对原视频概况能力与简洁方向搜索,无须人工摘要结果与超参数的先验知识,具有建模灵活、以及多目标优化算法解空间信息丰富的优点。
66、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!