一种基于Transformer的光场极线几何图像视差估计方法
本发明是关于计算机视觉领域中的光场成像与计算应用方向,特别涉及基于transformer深度学习网络的光场极线几何图像视差估计方法。
背景技术:
1、光场成像与计算是计算机视觉领域中的一个新兴的应用方向。它通过在相机主镜头和图像传感器间增加微透镜阵列,从而能够记录下汇聚在图像传感器平面上的光线角度与辐射,形成4d光场图像(二维空间信息和二维角度信息)。由于4d光场图像能够提供丰富的场景光线信息和深度线索,利用光场图像进行场景深度估计已获得了越来越多学者的关注,光场极线几何图像(epi)是4d光场图像的二维切片,它由一组光场极线(epipolarlines)组成,通过计算极线斜率,可获得当前像素的视差值。计算出所有像素的视差值后,即可得到光场视差图。虽然已提出了许多epi视差估计方法,但现有方法仍存在诸多挑战,如光场几何特征的学习和提取、遮挡和无纹理区域的检测和视差估计、噪声干扰等。
2、深度学习是近二十年来人工智能领域中最受关注的研究方向之一,已在计算机视觉、自然语言处理、数据挖掘,多媒体学习等方向取得了巨大成功。它利用卷积神经网络强大的特征提取和表示能力,旨在从训练样本中学习到数据的内在规律和表示。将深度学习引入到光场视差估计任务中,有助于解决光场视差估计中存在的各类挑战,并有效提升估计性能。目前已提出了多种基于卷积神经网络的epi视差估计方法,但这些方法都是基于卷积神经网络,难以实现epi中全局几何特征的提取。此外,由于epi只能提供单行或单列像素的视差线索,因此现有方法在视差估计过程中难以保证光场空间-角度一致性约束,从而导致估计性能退化。
3、随着2017年transformer技术的提出,transformer已成为当前深度学习的一种新范式。越来越多的研究尝试将transformer的强大建模能力应用到各类计算机视觉任务中,并取得了令人瞩目的优异性能。因此,本发明设计了一种具有空间一致性信息保持的transformer网络结构来实现epi视差估计。
技术实现思路
1、本发明的目的是针对现有技术的不足,提供了一种基于transformer的光场极线几何图像视差估计方法。该方法设计了一种具有空间一致性信息保持的transformer深度学习网络(epiformer)。它从0°、45°、90°、135°四个方向提取epi图像块,并且每个方向提取三个相邻的epi图像块,共12个epi图像块作为epiformer的输入,输出为中心像素的视差值,通过把光场中心子光圈所有像素估计的视差值拼接起来,能够得到对应的光场视差图。
2、本发明解决其技术问题采取的技术方案包括如下步骤:
3、步骤1.准备光场数据集,制作训练集和测试集;
4、步骤2.设计并搭建epiformer的网络结构;
5、步骤3.使用训练集训练epiformer模型;
6、步骤4.使用训练好的epiformer模型,在测试集上进行测试;
7、步骤1具体包括下述步骤:
8、步骤1-1:使用海德堡图像处理实验室提供的4d光场数据集作为实验数据集(k.honauer,o.johannsen,d.kondermann and b.goldluecke,“a dataset andevaluation methodology for depth estimation on 4dlight fields,”in asianconference on computer vision,2016.),该数据集包含了28张光场图像,提供了高精度的视差图和性能评估指标。每张光场图像包含了9行9列共81张大小为512×512的子光圈图像,其中位于第5行第5列的子光圈图像为中心子光圈图像。在28张光场图像中,16张为训练光场图像,其余12张为测试光场图像。
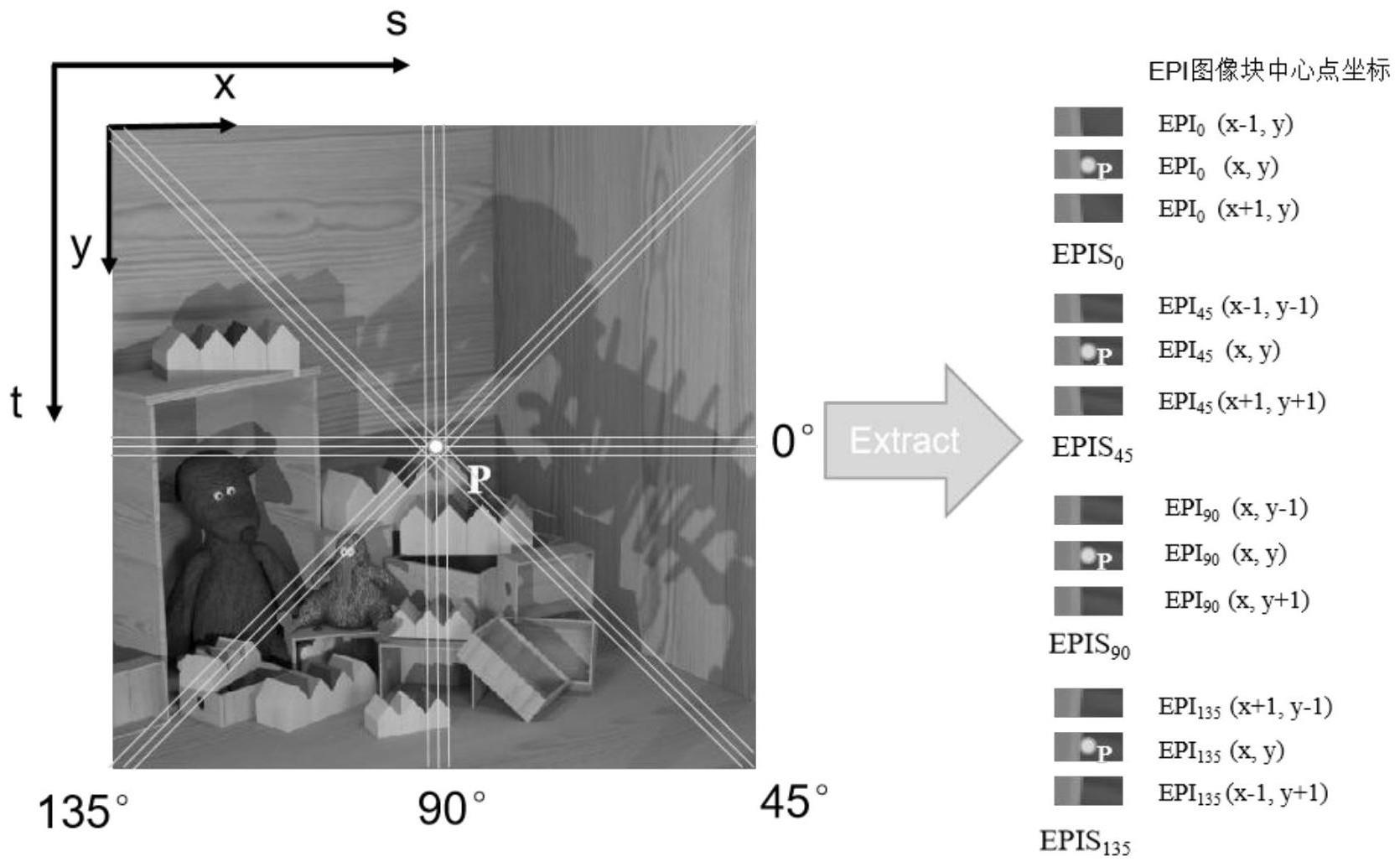
9、步骤1-2:采用soa-epn方法(w.zhou,l.liang,h.zhang,a.lumsdaine andl.lin,"scale and orientation aware epi-patch learning for light field depthestimation,"24th international conference on pattern recognition(icpr),beijing,china,2018)中的epi图像块提取方法,提取中心子光圈图像中每个像素在0°、45°、90°、135°四个方向,大小为9×21的epi图像块。
10、光场图像定义为lf(s,t,x,y),其中(x,y)为光场图像的空间坐标,(s,t)为光场图像的角度坐标。对于中心子光圈图像上的像素点p(x,y),将像素点p在0°、45°、90°、135°四个方向的epi图像块分别记作epi0(x,y)、epi45(x,y)、epi90(x,y)、epi135(x,y)。
11、步骤1-3:将中心子光圈图像中每个像素的epi图像块与其邻域像素的epi图像块组成一个epis样本。所有来自训练光场图像的epis样本构成训练集,所有来自测试光场图像的epis样本构成测试集。
12、对于光场图像lf(s,t,x,y)中心子光圈图像上的像素点p(x,y),将epi0(x,y)、epi0(x,y+1)和epi0(x,y-1)三个epi图像块组成像素点p(x,y)的水平样本epis0(x,y)={epi0(x,y),epi0(x,y+1),epi0(x,y-1)};将epi90(x,y)、epi90(x+1,y)和epi90(x-1,y)组成像素点p(x,y)的垂直样本epis90(x,y)={epi90(x,y),epi90(x+1,y),epi90(x-1,y)};将epi45(x,y)、epi45(x+1,y+1)和epi45(x-1,y-1)组成像素点p(x,y)的45度样本epis45(x,y)={epi45(x,y),epi45(x+1,y+1),epi45(x-1,y-1)};将epi135(x,y)、epi135(x+1,y-1)和epi135(x-1,y+1)组成像素点p(x,y)的135度样本epis135(x,y)={epi135(x,y),epi135(x+1,y-1),epi135(x-1,y+1)},由{epis0(x,y),epis45(x,y),epis90(x,y),epis135(x,y)}构成了像素点p(x,y)的epis样本。
13、所述步骤2具体实现如下:
14、步骤2-1:搭建epiformer的网络结构。
15、所述的epiformer网络结构由4个空间匹配模块(spatial matching module简称:smm)和1个多通道视差合并模块构成,4个空间匹配模块分别是0°空间匹配模块、45°空间匹配模块、90°空间匹配模块和135°空间匹配模块。对于像素点p(x,y)的epis样本,0°空间匹配模块的输入为epis0(x,y),输出视差预测向量logit0;90°空间匹配模块的输入为epis90(x,y),输出视差预测向量logit1;45°空间匹配模块的输入为epis45(x,y),输出为视差预测向量logit2;135°空间匹配模块的输入为epis135(x,y),输出为视差预测向量logit3,四个方向输出的视差预测向量的维度都为1×229(由于数据集的视差范围是-4到4(单位:像素),我们将视差预测定义为一个分类任务,预测精度是0.035个像素,一共分为229类)。
16、多通道视差向量合并模块,将4个空间匹配模块的输出logit0,logit1,logit2,logit3堆叠在通道上形成1×916的特征向量,再经过一个具有229个神经元的全连接层将预测的视差向量融合从而得到最终的视差向量logit4。
17、所述空间匹配模块由深度特征表征模块、空间特征融合模块、视差预测模块和多通道视差合并模块构成,具体如下:
18、(1)深度特征表征模块
19、深度特征表征模块包含了8个卷积层,分别是卷积层1到卷积层8,使用8个卷积核为2×2、步长为1×1的卷积层对输入的epi图像块进行深度特征提取,对每个卷积层的输出进行批归一化,然后使用relu激活函数对批归一化的输出进行激活;所述的8个卷积层中每个卷积层的输出特征图通道依次是(16,32,64,128,256,384,512,512),最后一层卷积层输出的张量大小为3×512×1×13(epis特征×特征通道×高×宽),即空间中相邻的3个epi深度特征,每个由512个大小为1×13的特征图构成。
20、(2)空间特征融合模块
21、空间特征融合模块的结构如图1所示,空间特征融合模块将深度特征表征模块的输出经过编码,拉平之后传入transformer模块中,将像素作为图像块做编码(相当于做一个1×1的卷积),得到的特征为n×3×1×13,n为编码后的特征通道,默认设置为768,3为相邻的epi特征数量,1×13为卷积后的特征分辨率。和传统的transformer做法一样,设置一个类令牌作为最后需要预测的epi图像中心的像素深度,先把特征重构到n×39,然后加上类令牌得到n×40特征维度,再加上位置编码(可学习的随机初始化的编码信息)得到transformer的输入,类令牌对应的特征部分([n,0])记作q,类令牌后的特征部分([n,1:])记作k。由于要计算epi图像块中像素与像素之间的相似程度,特征首先要经过自注意力模块和交叉注意力模块,公式如下:
22、
23、
24、其中为q和k特征向量维度的开根。
25、前馈模块有两个全连接构成,激活函数为gelu激活函数,公式如下:
26、ffn(z)=gelu(gelu(zw1+b1)w2+b2)
27、图3中的灰色框为一个子模块,包括自注意力模块、正则化、交叉注意力模块、正则化、前馈模块和正则化,整个空间特征融合模块则是由若干个子模块构成。默认采用8个子模块。
28、(3)视差分类模块
29、使用soa-epn中的视差分类方法(w.zhou,l.liang,h.zhang,a.lumsdaine andl.lin,"scale and orientation aware epi-patch learning for light field depthestimation,"201824thinternational conference on pattern recognition(icpr),beijing,china,2018)对空间匹配模块的输出做视差分类,得到4个方向的空间匹配模块对应的视差估计结果。
30、(4)多通道视差合并模块
31、多通道视差合并模块的输入为视差分类模块的输出,即4个空间匹配模块的输出logit0,logit1,logit2,logit3,维度都为1×229,将他们在通道维度上堆叠在一起,形成维度为1×916的融合特征,在经过一个具有229个神经元的全连接层将预测的特征向量融合得到最后的视差估计向量logit4。
32、与现有技术相比,本发明主要贡献是:
33、(1)光场极线几何图像块共享权重网络。它在空间匹配模块中共享参数,实现多方位特征融合。
34、(2)空间特征融合模块,基于transformer的方法,可以有效的建模epi图像块中像素与像素之间的关联,同时添加了空间信息,一定程度上缓解了遮挡带来的影响,同时也能得到更精确的像素匹配。
35、(3)一种用于深度估计的光场极线几何图像学习模型。为了达到方向和空间感知,它包含上述两种网络结构,并以光场极线几何图像块作为输入。
- 还没有人留言评论。精彩留言会获得点赞!