基于资源复用的全同态加密神经网络推理加速方法及系统
本公开属于全同态加密应用,尤其涉及一种基于资源复用的全同态加密神经网络推理加速方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
2、使用全同态加密(fhe:fully homomorphic encryption)技术保护卷积神经网络(cnn)的数据是一个当前热门的方向,然而两者的结合在实际应用方面存在许多障碍,具体包括:一方面,全同态加密仅能支持加法和乘法运算等线性运算,而通常的cnn包含relu等非线性激活函数;另一方面,全同态加密后的数据计算开销巨大,一个密文的运算比原本的运算多出5到6个数量级,而且神经网络本身就要进行多个节点多轮的复杂运算,这导致全同态加密的卷积神经网络(fhe-cnn)需要对大量数据进行计算,同时也需要大量的存储空间来对产生的数据进行存储和调度,进一步导致fhe-cnn的运行速度很慢。例如,首次将fhe和cnn结合的工作cryptonets,推理一个加密的5层的神经网络需要205秒,这样的速度是无法满足实际应用中的性能要求的。
3、在上述背景下,存在很多对fhe-cnn进行优化和加速的工作,具体包括:
4、(1)基于cpu实现的工作,这些工作仅考虑如何改进算法来减少密文操作从而减少推理的时间,并未考虑硬件上的优化。
5、(2)基于更底层的硬件层面的优化,具体的,常用的硬件平台包括图形处理器(graphics processing unit,gpu)、现场可编程门阵列(field-programmable gatearray,fpga)和专用集成电路(application specific integrated circuit,asic)。发明人发现,此类工作存在以下问题:
6、1)部分方法仅对全同态操作进行了优化,未能在全同态操作结合具体应用这个层面进行优化;
7、2)缺乏对fhe-cnn存储方面性能瓶颈的考虑,且缺乏针对计算过程的优化。
技术实现思路
1、本公开为了解决上述问题,提供了一种基于资源复用的全同态加密神经网络推理加速方法及系统,所述方案基于全同态加密运算优化方法和片上缓冲区复用策略,有效提高了全同态加密神经网络推理加速效果。
2、根据本公开实施例的第一个方面,提供了一种基于资源复用的全同态加密神经网络推理加速方法,包括:
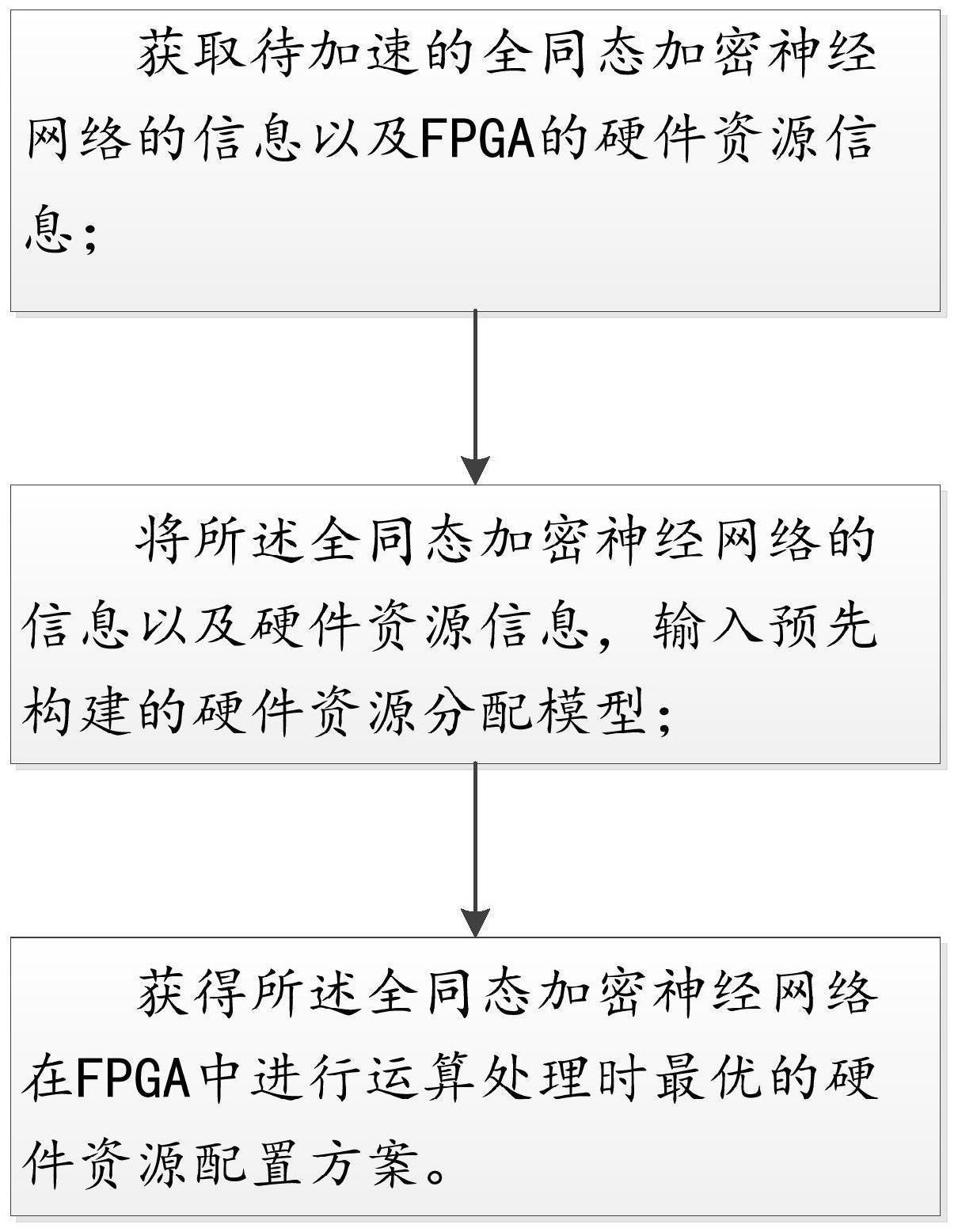
3、获取待加速的全同态加密神经网络的信息以及fpga的硬件资源信息;
4、将所述全同态加密神经网络的信息以及硬件资源信息,输入预先构建的硬件资源分配模型,获得所述全同态加密神经网络在fpga中进行运算处理时最优的硬件资源配置方案;
5、其中,所述硬件资源分配模型的处理策略为:针对全同态加密运算以及全同态加密神经网络的各网络层内进行并行及流水优化,并在各网络层之间采用同态基本操作模块的复用;同时,对于fpga的片上存储空间,基于所述全同态加密神经网络的运算划分,进行不同粒度下的片上缓冲区复用;最后,以最小化所述全同态加密神经网络推理加密数据的时间为目标,获得最优的资源配置方案,其中,所述全同态加密神经网络的运算按照不同粒度划分为同态基本操作、同态操作以及网络层运算三个等级的运算。
6、进一步的,所述硬件资源分配模型,具体表示如下:
7、
8、
9、
10、其中,latlr为lr层运行的时间,layer表示全同态加密神经网络包含的所有层,lr表示其中的一个层,op表示所有同态操作的集合,op表示其中的某一个同态操作,dspmax表示fpga开发板拥有的dsp数量,brammax表示fpga开发板拥有的bram的总数,dspop为该同态操作占用的dsp数量,bramlr为lr层使用的bram数量。
11、进一步的,每个网络层操作包括若干同态操作,每个同态操作包括若干同态基本操作,其中,所述全同态加密神经网络的运算采用流水线及并行处理的方式,并以所述同态基本操作为单位进行流水。
12、进一步的,所述针对全同态加密运算以及全同态加密神经网络的各网络层内进行并行及流水优化,并在各网络层之间采用同态基本操作模块的复用,具体为:按照同态基本操作、同态操作以及网络层运算的顺序,分别设置不同粒度运算内部的并行度,使不同粒度运算的并行效果叠加;
13、或,对于同态基本操作,根据rns多项式的系数遍历一轮还是多轮,将所述同态基本操作划分为两类,并通过对两类操作设置不同的并行度,使得两类操作运行时间相近;
14、或,对于网络层内实现跨同态操作的流水,对不同的同态操作设置同样的并行度,并基于rns多项式之间的数据依赖关系复杂度,将所述同态操作划分为两类;
15、或,对于不同的网络层运算,根据其是否包含keyswitch操作,将其划分为两类,并分别对不同类别进行流水线设计。
16、进一步的,所述对于fpga的片上存储空间,基于所述全同态加密神经网络的运算划分,进行不同粒度下的片上缓冲区复用,具体为:将片上缓冲区以存储一个rns多项式的空间作为存储单位,并根据同态基本操作的类别划分将片上缓冲区划分为两类;其中,所述缓冲区的复用包括同态操作内的复用、网络层内的复用以及网络层之间的复用。
17、进一步的,所述同态基本操作包括;模乘、模加、模减、取模运算、快速数论变换及其逆变换;
18、或,所述同态操作包括明密文加法、密文加法、密文乘法、重放缩、重线性以及旋转操作;
19、或,所述网络层包括同态卷积层、同态激活层以及同态全连接层。
20、根据本公开实施例的第二个方面,提供了一种基于资源复用的全同态加密神经网络推理加速系统,包括:
21、数据获取单元,其用于获取待加速的全同态加密神经网络的信息以及fpga的硬件资源信息;
22、资源配置单元,其用于将所述全同态加密神经网络的信息以及硬件资源信息,输入预先构建的硬件资源分配模型,获得所述全同态加密神经网络在fpga中进行运算处理时最优的硬件资源配置方案;
23、其中,所述硬件资源分配模型的处理策略为:针对全同态加密运算以及全同态加密神经网络的各网络层内进行并行及流水优化,并在各网络层之间采用同态基本操作模块的复用;同时,对于fpga的片上存储空间,基于所述全同态加密神经网络的运算划分,进行不同粒度下的片上缓冲区复用;最后,以最小化所述全同态加密神经网络推理加密数据的时间为目标,获得最优的资源配置方案,其中,所述全同态加密神经网络的运算按照不同粒度划分为同态基本操作、同态操作以及网络层运算三个等级的运算。
24、根据本公开实施例的第三个方面,提供了一种电子设备,包括存储器、处理器及存储在存储器上运行的计算机程序,所述处理器执行所述程序时实现所述的一种基于资源复用的全同态加密神经网络推理加速方法。
25、根据本公开实施例的第四个方面,提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的一种基于资源复用的全同态加密神经网络推理加速方法。
26、与现有技术相比,本公开的有益效果是:
27、(1)本公开提供了一种基于资源复用的全同态加密神经网络推理加速方法,所述方案支持从神经网络应用到全同态加密硬件优化实现的自动化部署,其采用的全同态加密技术有效且可靠地保护了神经网络推理过程中的数据安全,极大地便利了从神经网络到加密推理以及硬件部署的流程,以满足实际应用需求为目标进行了硬件加速优化,取得了良好的部署效果;
28、(2)所述方案针对fpga硬件部署的瓶颈,即计算资源利用效率低和片上存储空间不足,提出了全同态算子优化技术和片上缓冲区复用技术,有效地缓解了实际部署过程中的困难,发挥了fpga的硬件优势,对加密神经网络的推理速度以及能耗比都取得了良好的优化效果;
29、(3)所述方案采用的高层次综合技术具有编程灵活易实现、开发周期短、可移植性强等优势,便于对多种应用需求进行设计空间探索,具体体现在可以针对不同的神经网络和不同型号的fpga开发板进行硬件部署的评估,生成运行速度最优的硬件资源配置方案并生成用于部署的代码。此外该方法也可针对其他优化目标进行调整,具有可拓展性。
30、本公开附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本公开的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!