一种双手三维姿态估计方法、装置、电子设备及存储介质与流程
本公开涉及互联网,尤其涉及一种双手三维姿态估计方法、装置、电子设备及存储介质。
背景技术:
1、在姿态估计的研究中,基于手部的姿态估计研究备受青睐。在人所有的姿态中,手势占据了90%,是最主要的人机交互姿态。未来的生活场景朝着越来越智能化的方向发展,智能家居、自动驾驶、智慧医疗及第一视角沉浸式交互等应用场景,都离不开手势交互的身影。
2、相关技术中,手部姿态估计主要都是针对单手场景而设计的,在应用于预测双手三维姿态时,只能将两只手分别从图像中裁剪出来当作两只单手进行处理,利用单手三维姿态估计的方法去预测每只手的姿态,最后再将两只手的预测结果组合到一起作为最终双手姿态估计的结果,而这种处理方式下,无法准确的预测双手三维姿态。
技术实现思路
1、本公开提供一种双手三维姿态估计方法、装置、电子设备及存储介质,本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种双手三维姿态估计方法,包括:
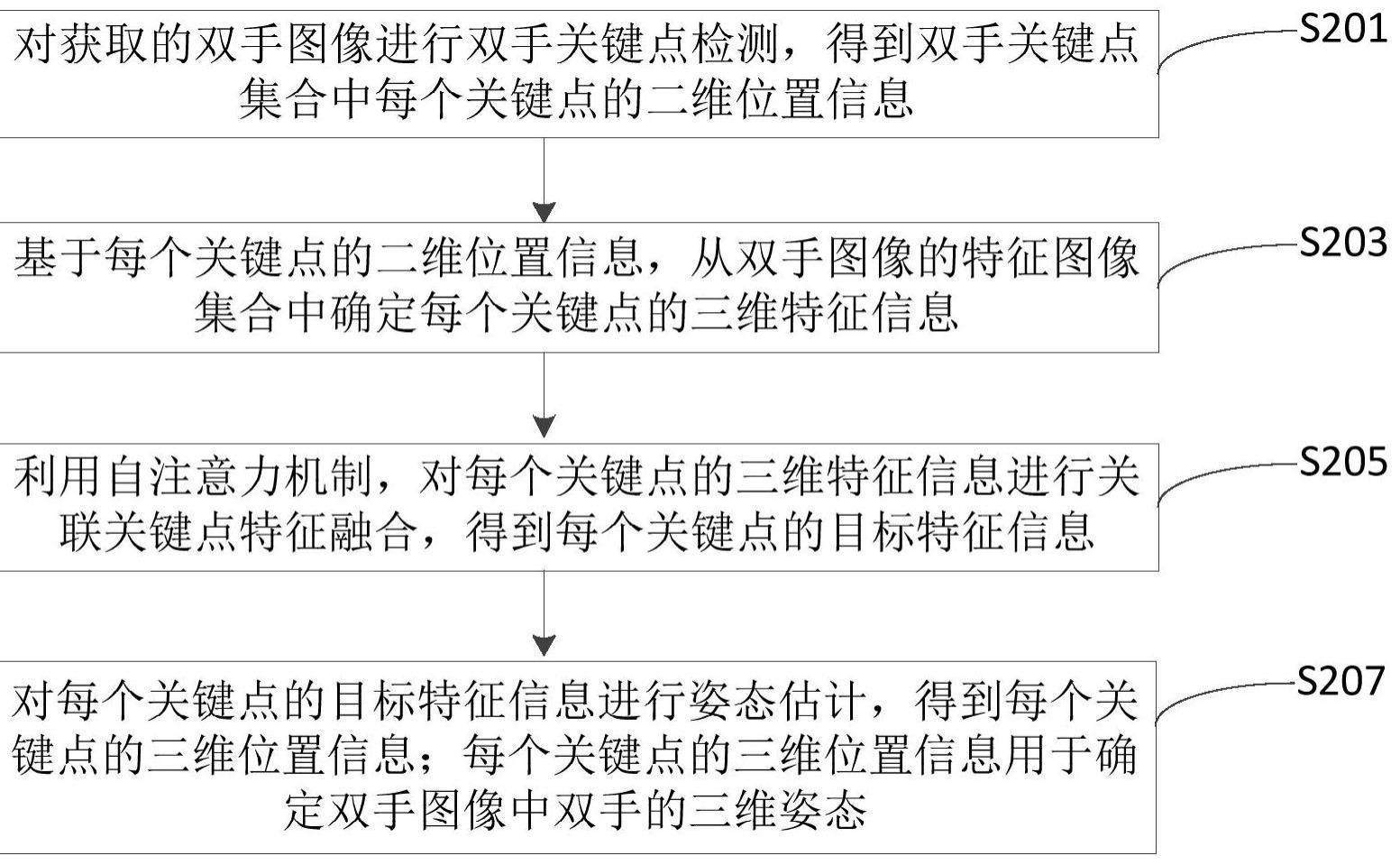
3、对获取的双手图像进行双手关键点检测,得到双手关键点集合中每个关键点的二维位置信息;
4、基于每个关键点的二维位置信息,从双手图像的特征图像集合中确定每个关键点的三维特征信息;
5、利用注意力机制,对每个关键点的三维特征信息进行关联关键点特征融合,得到每个关键点的目标特征信息;
6、对每个关键点的目标特征信息进行姿态估计,得到每个关键点的三维位置信息;每个关键点的三维位置信息用于确定双手图像中双手的三维姿态。
7、在一些可能的实施例中,对获取的双手图像进行双手关键点检测,得到双手关键点集合中每个关键点的二维位置信息,包括:
8、对双手图像进行多尺度特征提取,得到特征图像集合;特征图像集合包括不同尺度的多个特征图像;
9、从不同尺度的多个特征图像中确定目标特征图像;目标特征图像的尺度与双手图像的尺度相同;
10、对目标特征图像进行双手关键点检测,得到每个关键点的二维位置信息。
11、在一些可能的实施例中,对目标特征图像进行双手关键点检测,得到每个关键点的二维位置信息,包括:
12、对目标特征图像进行关键点热力分析,得到每个关键点对应的热力图;热力图的尺度与目标特征图像的尺度相同;
13、根据每个关键点对应的热力图,确定每个关键点位于目标特征图像中每个像素位置的置信度;
14、针对每个关键点,将目标特征图像中置信度最大的像素位置,作为每个关键点的像素位置;
15、根据每个关键点的像素位置,得到每个关键点的二维位置信息。
16、在一些可能的实施例中,基于每个关键点的二维位置信息,从双手图像的特征图像集合中确定每个关键点的三维特征信息,包括:
17、在多个特征图像中的每个特征图像中,确定每个关键点的二维位置信息对应的关键像素位置;
18、将每个特征图像中,每个关键点对应的关键像素位置处的特征信息进行融合,得到每个关键点的三维特征信息。
19、在一些可能的实施例中,利用注意力机制,对每个关键点的三维特征信息进行关联关键点特征融合,得到每个关键点的目标特征信息,包括:
20、将双手关键点集合中每个关键点的三维特征信息输入注意力模块,输出双手关键点集合中任意两个关键点之间的注意力值;任意两个关键点之间的注意力值表征任意两个关键点之间的相关性;
21、基于任意两个关键点之间的注意力值,对每个关键点的三维特征信息进行关联关键点特征融合,得到每个关键点的目标特征信息。
22、在一些可能的实施例中,方法还包括:
23、获取初始图像;
24、对初始图像进行双手检测,得到初始图像中双手区域的位置信息;
25、根据双手区域的位置信息,对初始图像进行裁剪,得到双手图像。
26、在一些可能的实施例中,方法还包括:
27、获取训练双手图像;训练双手图像携带有标注信息;标注信息包括双手关键点集合中每个关键点的实际三维位置信息和每个关键点的实际二维位置信息;
28、通过预设机器学习模型,对训练双手图像进行双手关键点检测,得到每个关键点的预测二维位置信息;基于每个关键点的预测二维位置信息,从训练双手图像的特征图像集合中确定每个关键点的预测三维特征信息;通过注意力机制,对每个关键点的预测三维特征信息进行关联关键点特征融合,得到每个关键点的预测目标特征信息;对每个关键点的预测目标特征信息进行姿态估计,得到每个关键点的预测三维位置信息;
29、基于每个关键点的预测三维位置信息和关键点的实际三维位置信息之间的第一损失值,以及每个关键点的预测二维位置信息和每个关键点的实际二维位置信息之间的第二损失值,对预设机器学习模型进行训练,直至满足预设结束条件时,得到双手三维姿态估计模型;
30、双手三维姿态估计模型用于对获取的双手图像进行双手关键点检测,直至得到每个关键点的三维位置信息。
31、根据本公开实施例的第二方面,提供一种双手三维姿态估计装置,包括:
32、检测模块,被配置为执行对获取的双手图像进行双手关键点检测,得到双手关键点集合中每个关键点的二维位置信息;
33、确定模块,被配置为执行基于每个关键点的二维位置信息,从双手图像的特征图像集合中确定每个关键点的三维特征信息;
34、融合模块,被配置为执行利用注意力机制,对每个关键点的三维特征信息进行关联关键点特征融合,得到每个关键点的目标特征信息;
35、估计模块,被配置为执行对每个关键点的目标特征信息进行姿态估计,得到每个关键点的三维位置信息;每个关键点的三维位置信息用于确定双手图像中双手的三维姿态。
36、根据本公开实施例的第三方面,提供一种电子设备,包括:
37、处理器;
38、用于存储处理器可执行指令的存储器;
39、其中,处理器被配置为执行指令,以实现本公开实施例第一方面的双手三维姿态估计方法。
40、根据本公开实施例的第四方面,提供一种计算机可读存储介质,当计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行本公开实施例第一方面的双手三维姿态估计方法。
41、本公开的实施例提供的技术方案至少带来以下有益效果:
42、本公开实施例的双手三维姿态估计方法,可以直接将双手作为一个整体,同时预测两只手的三维姿态,相比现有基于单手三维姿态估计的双手预测方案更简洁方便,不再需要利用手部检测模块对两只手分别定位和裁剪。同时,利用注意力机制,对每个关键点的三维特征信息进行关联关键点特征融合,可以增强相关性强的关键点的影响,减弱相关性弱的关键点的影响,进而减少两只手的相互干扰,使得相比现有方法能够更准确的预测双手的三维姿态,在面对像双手抱拳这样交互面积大的双手手势预测时,效果有明显提升。
43、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!