一种基于云理论的高土石坝静力参数快速反演识别方法
本发明属于水利工程,具体涉及一种基于云理论的高土石坝静力参数快速反演识别方法。
背景技术:
1、高土石坝在建设及运行的过程中,不可避免的会出现变形等严重威胁大坝安全的问题,特别是由于其建设高度的增加,变形会显著增大,影响会显著增强,在极端条件下还可能会造成大坝发生溃坝等事故,其损失严重程度不可估量。高土石坝的变形研究已经成为保证高土石坝施工及运行安全性的重要评价指标,而本构模型参数的选择对精确的分析高土石坝变形起着十分重要的作用。因此,反演方法由于其精确的参数识别性能成为本构模型参数确定的有效方法。
2、但是在实际地高土石坝反演分析过程中,采用传统机器学习方法作为代理模型代替直接有限元方法的反演方法虽相比直接有限元极大的提升了效率,但仍然耗时较久,在大型搜索中针对一组本构参数的搜索时长就高达数小时,且若搜索代数较少或搜索空间不足容易导致搜索结果不佳,使得高土石坝的变形分析很难做到与实测数据相结合进行及时反馈,更无法进行有效的工程评价。为此,我们提出了一种基于云理论的高土石坝静力参数快速反演识别方法。
技术实现思路
1、本发明是为了解决上述问题而进行的,目的在于提出一种新的高土石坝静力参数快速反演识别方法,在保证参数识别精确的条件下,以提升整个反演分析体系的运行速度,从而实现本构参数的及时识别。
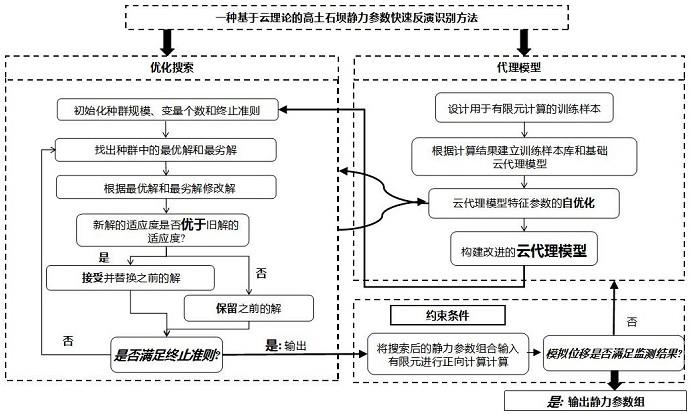
2、本发明为了实现上述目的,采用了以下方案:一种新的高土石坝静力参数快速反演识别方法,包括以下步骤:
3、(1)建立高土石坝有限元模型,确定反演参考点并选择本构模型;
4、(2)确认本构模型参数范围,生成有效模型参数组;
5、(3)基于本构模型参数组,采用有限元进行正分析;
6、(4)通过本构模型参数组以及有限元正分析变形结果建立基础云代理模型;
7、(5)采用jaya优化算法调整云代理模型内部控制参数,得到最终使用的云代理模型;
8、(6)将修正后的云代理模型嵌套入jaya优化算法中,随后依据实测变形反演模型参数。
9、进一步的,所述步骤(1)包括:
10、步骤(1-1):有限元建模
11、根据高土石坝的图纸及实测资料,运用专业有限元软件(如abaqus,ansys,geodyna等常用有限元软件均可)建立有限元模型并合理划分网格,网格划分依据计算精度需求进行即可,无特别要求。
12、步骤(1-2):反演参考点选择
13、依据高土石坝施工时监测设备在坝体截面的分布,从坝体截面上设置监测设备且与有限元网格对应的点中选择本构参数反演搜索的参考点。进一步的,可以选择监测结果准确且与有限元网格划分对应的点作为后续进行本构参数反演搜索的参考点(如坝顶点等)。每次反演仅选择一个参考点进行。
14、步骤(1-3):本构模型选择
15、选择合适的本构模型(如邓肯张e-b模型,广义塑性模型等常用本构模型均可)作为后续进行有限元耦合正分析的基础。
16、进一步的,所述步骤(2)包括:
17、步骤(2-1):确定本构模型参数以及波动范围
18、基于前人研究中对所选本构模型的参数值和本领域对相关坝体的研究情况选择确定本方法中的波动中心,如采用“xu b,zou d,liu h.three-dimensional simulationof the construction process of the zipingpu concrete face rockfill dam basedon a generalized plasticity model[j].computers&geotechnics,2012,43(jun.):143-154.”文章确定的一组广义塑性模型参数值作为波动中心进行后续紫坪铺大坝的静力反演。参数值的波动幅度一般设置为±30%,也可依据具体算例细节控制波动幅度。
19、步骤(2-2):生成有效模型参数组
20、引入超拉丁立方抽样法,在合理波动范围(步骤2-1确定的波动范围)内进行随机取样和组合,从而得到后续训练中所需的多组本构模型参数组。
21、进一步的,所述步骤(3)包括:
22、将上一步骤中得到的所有本构模型参数组分别带入有限元计算过程中,从而得到多组变形计算结果。
23、进一步的,所述步骤(4)包括:
24、步骤(4-1):整理步骤(3)中所有的输入、输出数据。
25、步骤(4-2):“执行特征值计算”:分别计算输入、输出端口的云滴期望xi为步骤(4-1)中整理的某一类数据集中的全部数据点值,n为数据点的个数。分别将输入、输出端口的所有云滴按照预设的终止条件(终止条件定义为循环次数,一般设置为略大于数据点个数)进行随机分组并循环组合,得到每组随机分组间“方差和ex的均值”定义为y,最终共有q个y组成集合:{y1,y2,y3...yq}。最后得到剩余的两个特征:he2=ey-en2,其中ex为期望值,en为熵,d为方差,he为超熵。
26、步骤(4-3):根据步骤(4-2)按需生成所有输入、输出云集的特征。
27、步骤(4-4):“确定性的确定”。这里,代表每个云滴在一个云团中位置的确定度μ的确定方法如下:其中,ex为通过步骤4-2生成的期望,x为某云滴点的值,其中en’为基于步骤4-2中生成的熵和超熵重新生成的本步骤所使用的新熵,采用(en,he^2)组合生成一个正态随机数;
28、步骤(4-5):“传递与组合”过程。通过确定度μ建立在输入及输出端口之间的传递通道。当只有一个输入变量时,传递一个μ的确定性值。当存在多个输入段时,利用表达式确定每个μ值,ω其中为各分量的权重,m为输入参数的阶数,m=1.....m,得到最终的确定性值。
29、步骤(4-6):将传递到输出端的最终确定值μ输入输出云。输出的云滴按照如下规则输出,其中b代表输出端口,ex表示该类点总的期望,en表示该类点的熵:
30、若在上升沿
31、若在下降沿
32、其中,en’b为遵循步骤4-2过程生成的输出端口新熵。
33、进一步的,所述步骤(5)包括:
34、步骤(5-1):基于终止需求构建目标函数并以此对解的取舍进行判断:fitness=|(dgen,i-dreal,i)/dreal,i|,其中适应度表示目标函数的判断标准,dgen,i为本研究采用的反演方法预测的相对位移,dreal,i为目标点的真实实测位移。目标函数用于度量模拟值和实际值的接近程度,将每个粒子的位置信息输入目标函数即可得到评价位置优良程度的的适应度值,其值越小表明模拟效果越好,通过搜索得到的参数组对应的变形值越接近真实值。
35、步骤(5-2):通过基础设置确定粒子的个数、迭代次数及在搜索空间内的初始位置,并通过以下公式计算粒子在每次迭代过程中位置的改变:
36、
37、其中p,j,k分别表示迭代变量、个体解变量和种群中的解。进一步,a(p,j,k)是第p次迭代过程中第k个个体的第j个变量,a(p+1,j,k)代表a(p,j,k)这个个体在下一个迭代过程中的变量,a(p,j,b)为一次迭代中的最优解,a(p,j,w)为一次迭代中的最差解,r表示[0,1]范围内随机选取的控制指标。
38、步骤(5-3):根据步骤(5-2)中的位置更新公式不断生成新的解。在下一次迭代过程中基于目标函数进行解的新旧优异度比较,若新解更优,则替换原解进入下一轮迭代,否则依旧保留原解位置。
39、步骤(5-4):将步骤(4)中得到的基础云代理模型引入步骤(5-1)-步骤(5-4)中提出的jaya优化算法中,通过研究所需设置终止目标,通过寻优搜索修正系数对云代理模型中的三特征值(ex,en,he)进行调整,从而得到模拟结果拟合程度更高的提升云代理模型。
40、进一步的,所述步骤(6)包括:
41、将优化后的云代理模型嵌套进jaya优化算法,设置满足研究需求的优化算法基础参数(如参考“kang f,liu x,li j,et al.multi-parameter inverse analysis ofconcrete dams using kernel extreme learning machines-based response surfacemodel[j].engineering structures,2022,256:113999-.”对jaya优化算法中的各控制参数进行设置,在此基础上若未能搜索到合适值可适当增大jaya优化算法中各控制参数),并将需要进行反演的实测值输入作为目标比较值进行反演搜索。最后一代jaya粒子群内对应最小适应度的位置称为全局最优位置,其值即为全局最优解,将值输出则为通过反演得到的所需本构模型参数组值。
42、与现技术相比,本发明提供的技术方案带来的有益效果包括:本发明提供了一种基于云理论的高土石坝静力参数快速反演方法,从高土石坝坝料之间的模糊关联入手,通过云理论建立了高土石坝变形与本构模型参数之间的非线性映射,并且引入jaya优化算法对构建的基础云代理模型内部控制参数进行了修正,最终利用工程实测的高土石坝变形数据反演了本构模型的参数。通过反演搜索识别出的本构参数具有极高精度,并且整个反演过程的运行时间较传统机器学习方法减小98%以上,相比直接采用有限元进行反演减小99.9%以上。本发明思路清晰新颖,能够有效建立运行时间短、映射精确的的非线性关联,可为大多数水利、土木工程的及时状态评价以及安全分析提供更实用有效的算法,使变形模拟的实时反馈成为可能,因此具有广阔的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!