一种面向医学图像分割的单一域泛化方法
本发明属于医学图像分析领域,具体涉及一种面向医学图像分割的单一域泛化方法。
背景技术:
1、在计算机辅助临床诊断系统中,人体组织、器官及病灶等分割算法是其中一个重要环节。目前,深度学习系统在医学图像分割问题上已得到广泛应用,并取得较高精度。然而由于不同设备、不同病人群体和不同成像参数等因素,深度学习模型在处理新的数据域的图像时常常面临性能的大幅度下降。为达到临床可用水平,提高深度学习模型的跨中心、跨模态的适应与泛化能力是亟待解决的问题。
2、总体来说,现有的提升深度学习网络域泛化(domain generalization,dg)能力的方法可以分为:基于数据操纵的方法和基于对齐的方法。前者旨在通过数据增强或数据生成来模拟未知的目标域数据,以提升模型的泛化能力。如中国专利cn114694150,公开日为2022年7月1日,公开了一种提升数字图像分类模型泛化能力的方法及系统,采用基于混合样本的数据增强方法,利用分类网络的梯度信息进行数据增强以提升模型泛化能力。其缺点在于:一方面,数据增强是对输入图像进行简单的扩充、变换或者随机化,难以较为准确地模拟目标域数据,导致训练的模型泛化能力有限;另一方面,鉴于医学图像包含丰富的组织或器官细节,数据生成模型难以准确的生成符合实际的医学图像;而后者旨在对齐多个源域的数据分布以学习域不变表征,进而提升模型在未见过的目标域上的泛化能力。如中国专利cn115018874a,公开日为2022年9月6日,公开了一种基于频域分析的眼底血管分割域泛化方法,采用基于频域分析的特征归一化算法,通过在多个源域间学习一个更统一的语义频率分布空间,进而增强模型的表达能力和泛化能力。其缺点在于:一方面,在医学图像领域,数据存在隐私问题,在采取包括伦理批准和病人同意的复杂程序之前,数据禁止共享,聚合多个域的数据难以实现。另一方面,在医学图像分割任务中,数据标注难度大、代价高、耗时长,需要相关领域专家进行标注,搜集多个域的标注数据较为困难。
技术实现思路
1、本发明的目的在于针对现有技术存在的不足,提供一种面向医学图像分割单一域泛化方法。
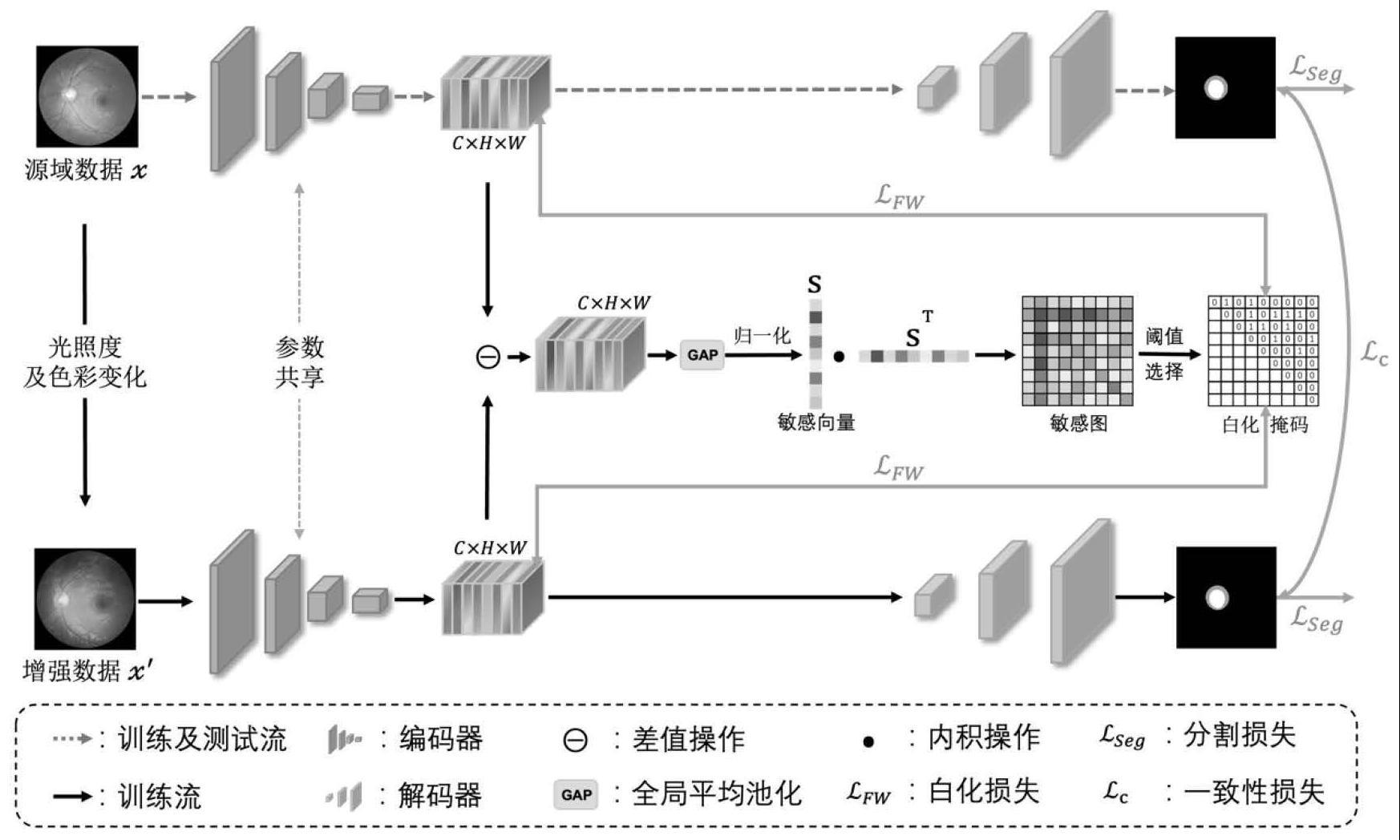
2、本发明首先采用单一域泛化策略,避免了跨中心的数据隐私以及高昂的数据标注代价问题;基于医学图像分割问题,本发明针对医学图像特性,创新地采用数据弱增强模拟域偏移,并提出双分支一致性网络以学习域不变表征,提升模型跨中心泛化能力;同时提出特征指导白化方法,进一步指导模型关注语义信息而忽略风格信息,以提升模型表达能力和分割精度。
3、一种面向医学图像分割单一域泛化方法,包括:
4、(1)统一训练域的有标注的输入实例图像x尺寸,并进行数据增强操作获得增强数据x′,以模拟域偏移。
5、(2)利用两个共享参数的编码器encoder分别对原始图像x和增强图像x′进行特征抽取,获得两个维度为c×h×w的特征图m和m′,并进行实例归一化;
6、(3)将特征m和m′分别输入至两个共享参数的解码器decoder以获得预测概率图f(x)和f(x′)。两个预测概率图一方面分别与真实标签y计算分割损失以提升模型性能;另一方面两个预测图之间计算一致性损失以学习域不变表征,提升模型泛化能力;
7、(4)将特征图m和m′进行差值操作得到高度敏感的风格信息特征图ms,并通过全局平均池化及归一化进行降维,得到敏感向量s。敏感向量与其转置st进行内积获得敏感图sm,并通过阈值选择得到白化掩码wm,最后对特征图m和m′的协方差矩阵∑m和∑′m进行指导白化并计算特征白化损失
8、(5)最小化整体损失。训练上述分割网络时,在总损失函数未达到预设收敛条件时,迭代更新上述分割网络的参数,直至总损失函数达到预设收敛条件。
9、(6)目标图像分割。对于给定目标域图像,分割模型输出目标图像每个像素点所属类别概率,并设定阈值将该像素点标记为分割目标或背景。
10、上述步骤(1)中的图像处理增强方法为:
11、(i)统一图像的尺寸,使用双线性插值算法将所有图像x都缩放成固定尺寸,并使用最近邻差值将对应标签y缩放成相同尺寸。使得输入图像符合分割网络的输入规格;
12、(ii)图像弱增强操作,鉴于医学图像的域偏移主要来自于图像的明亮度及色彩等变化。因此对统一尺寸后的图像x采用如光照及色彩等变化的弱增强操作,获得增强数据x′,以模拟域偏移。
13、所述的步骤(2)的特征抽取及归一化方法为:
14、(i)利用两个共享参数的编码器对原始图像x和增强图像x′进行特征抽取,如公式所示。
15、
16、其中编码器encoder可采用各种类型的分割网络特征提取器,如unet、3dunet、deeplab等。
17、(ii)采用实例归一化方法对提取的特征进行归一化。
18、
19、其中h和w表示特征图m和m′的尺寸,c代表通道索引,j,k,l,m表示位置索引,∈→0防止分母为0。
20、所述的步骤(3)的域不变表征学习方法为:
21、(i)将特征m和m′分别输入至两个共享参数的解码器(decoder)以获得预测概率图f(x)和f(x′);
22、f(x)=decoder(m)
23、f(x′)=decoder(m′)
24、(ii)将预测概率图f(x)和f(x′)与真实标签y计算分割损失以提升模型性能。分割损失用来衡量预测输出与真实标签之间的差异,并采用像素级的交叉熵损失作为损失函数;
25、
26、其中h和w表示输入图像尺寸,i表示像素的索引,c代表分割中像素预测的类别,c是类别的索引,yic∈{0,1}是真实标签的one-hot编码,pic是预测的类别概率。最小化分割损失能够优化模型性能,提升模型分割精度。
27、(iii)将预测概率图f(x)和f(x′)相互计算一致性损失以学习域不变表征,提升模型泛化能力。一致性损失用来衡量原始图像和增强图像的预测概率图之间的差异,并采用平方差损失作为损失函数;
28、
29、其中f(·)代表由编码器和解码器构成的分割网络,f(x)和f(x′)表示网络输出的维度为c×h×w的预测概率图。最小化一致性损失能够对齐网络对于原始图像和增强图像的预测分布,使得网络关注域共享的语义信息而忽略域特定的风格信息,进而学习域不变表征,提升网络的域外泛化能力。
30、所述的步骤(4)的特征指导白化方法为:
31、(i)鉴于增强图像和原始图像具有相同的语义信息但有不同的风格信息,其特征图做差值操作,得到仅包含风格信息的维度为c×h×w的风格信息特征图ms;
32、ms=m-m′
33、通过差值操作能够对语义信息和风格信息进行解耦,便于消除风格信息带来的影响而保持语义信息不发生改变。
34、(ii)对风格信息特征图ms进行全局平均池化操作获得敏感向量s,以降低维度减少计算量,同时抑制过拟合;并通过归一化操作对敏感向量s进行归一化,以提升模型收敛速度;
35、
36、
37、其中h和w表示风格信息特征图ms的尺寸,c为通道数索引,i,j代表位置索引,max(·)和min(·)用于计算通道维度的最大和最小值。
38、(iii)将敏感向量s与其转置st进行内积获得敏感图sm,并对敏感图进行阈值选择获得白化掩码wm,用于消除特征图中的风格信息,近一步指导编码器关注语义信息而忽略风格信息,提升泛化能力;
39、sm=(s)(s)t∈rc×c
40、
41、其中i,j代表位置索引,top(·)函数表示返回敏感图sm中top元素的值,ε为固定选择白化范围阈值,设置为0.1~0.9,进一步优选,设置为0.4。
42、(vi)计算特征图m和m′相应的协方差矩阵∑m和∑′m,以匹配所获取的白化掩码wm的维度;
43、
44、
45、其中h和w表示特征图m和m′的尺寸。
46、(v)并利用白化掩码对协方差矩阵∑m和∑′m进行风格特征白化,指导模型关注语义信息而忽略风格信息,以提升模型表达能力和分割精度,白化损失为:
47、
48、其中表示算术平均值操作,⊙表示对应元素相乘。
49、所述的步骤(5)的最小化总损失方法为:
50、(i)计算的总损失为分割损失一致性损失以及特征白化损失的线性组合;
51、
52、其中,λ1和λ2为超参数,λ1和λ2参数的范围为(0~1],用于平衡两种损失对总损失的影响,进一步优选,λ1和λ2分别设置为0.3和0.6。
53、(ii)迭代更新上述分割网络的参数,直至总损失函数达到预设收敛条件;
54、所述的步骤(6)的目标图像分割方法为:
55、(i)将目标图像xt输入至分割模型获得预测概率图f(xt);
56、(ii)设置0.5~0.9作为阈值对预测图进行标记,预测概率大于阈值则标记为分割目标,小于阈值则标记为背景,以获得最终的分割掩码。
57、进一步优选,设置0.5作为阈值对预测图进行标记,预测概率大于0.5则标记为分割目标,小于0.5则标记为背景,以获得最终的分割掩码;
58、与现有技术相比,本发明的有益效果:
59、(1)本发明域不变表征学习的单一域泛化策略。通过对源域数据进行弱增强以模拟域偏移,以双分支一致性损失来学习域不变表征,提升模型泛化能力和鲁棒性;
60、(2)通过特征差值操作对特征进行解耦,以获得高度敏感的风格特征,并用风格特征来近一步对特征进行风格白化,以指导模型关注语义信息而忽略风格信息,提升模型表达能力和分割精度
- 还没有人留言评论。精彩留言会获得点赞!