一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法
本发明涉及深度学习领域,具体涉及一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法。
背景技术:
1、传统医学影像降噪算法主要分为迭代重建算法、投影域算法和图像后处理算法三类。此类去噪方法虽能一定程度上降低图像噪声,但受限于设备算力和投影数据等因素,并不能达到令人满意的效果。
2、近年来,随着深度学习飞速发展,许多学者开始将其应用到医学影像去噪任务中。文献“chen h,zhang y,zhang w h.low-dose ct via convolutional neural network[j].biomedical optics express,2017,8(2):679-694.”将卷积神经网络以逐块的方式对低剂量ct影像进行训练,相比于传统算法,该方法在各项评价指标上有了很大提升;文献“kang e,min j,ye j c.adeep convolutional neural network using directionalwavelets for low-dose x-ray ct reconstruction[j].medical physics,2017,44(10):360-375.”利用深度卷积神经网络对低剂量ct图像进行小波变换来提取伪影的方向分量,以此抑制ct图像特有的噪声;文献“苏宁,叶晗鸣,王逍遥.基于adam优化的多传感器对接位姿融合算法研究[j].现代制造技术与装备,2022,58(2):35-37.”;文献“keisuke u,koichio,masami g,et al.quantitative evaluation of deep convolutional neuralnetwork-based image denoising for low-dose computed tomography[j].visualcomputing for industry,biomedicine,and art,2021,4(1):21-26.”采用去噪卷积神经网络对ct图像降噪,同时保持了图像清晰度,并通过裁剪cnn模型的方式防止了图像过度平滑;目前,基于深度学习的降噪算法主要关注的是mri或ct影像,有关spect骨显像降噪方法的研究极少。
技术实现思路
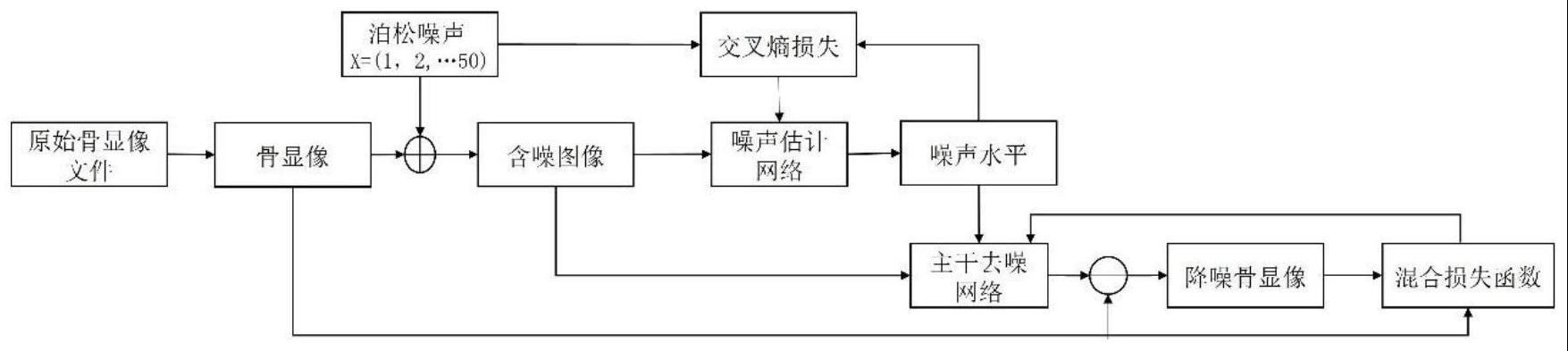
1、本发明公开了一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法,包括以下步骤:(1)划分训练集与测试集;(2)将密集连接、残差连接和协调注意力机制进行结合,提出了密集残差注意力卷积块;(3)以密集残差注意力卷积块为基本单位,构提出了基于u-net的两阶段spect降噪网络;(4)利用融合感知损失的混合损失函数优化主干降噪网络的降噪效果;(5)训练网络模型,并保存训练完成后模型的参数;(6)利用保存的最终模型去除骨显像噪声,输出降噪后的骨显像。本发明公开的骨显像降噪方法,在保留spect骨显像病灶细节特征的同时,可以有效降低骨显像图像中噪声。
2、本发明所提供的技术方案为:一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法,其特征在于包括如下步骤:
3、为达到以上技术目的,本发明采用以下技术方案:
4、一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法,其特征在于所述计算方法包括以下步骤:
5、步骤1:将预处理后的骨显像和对应加噪后骨显像作为训练集和测试集,并划分为训练集与测试集,具体步骤如下:
6、(1)通过归一化的方式转化为灰度图,每例包含人体正面、背部两张图片;
7、(2)提高骨显像信噪比,通过裁剪的方式得到骨显像肩部至盆骨区域,并将图像调为n×n像素大小,n为正整数;
8、(3)将原图和加噪后的骨显像作为一组数据,以预处理后的灰度数据作为标签,划分为训练集与测试集;
9、步骤2:构建密集残差注意力卷积块,整个密集残差注意力卷积块由1×1、3×3卷积、relu激活函数和协调注意力机制构成,卷积块的计算结构如下:
10、x1=σ(conv3×3(xin))
11、x2=σ(conv1×1(concat(x1,xin))
12、x3=σ(conv3×3(x2))
13、xout=ca(xin+x3+x2)
14、式中:xin表示输入卷积块的骨显像,xout表示经过密集残差注意力卷积块计算后的骨显像,即的骨显像特征图;σ()表示进行bn批量归一化和relu非线性变换;conv3×3()、conv1×1()分别表示3×3卷积与1×1卷积运算;concat表示特征拼接,设x1为c1×h×w、xin为c2×h×w,concat(x1,xin)的计算结果为(c1+c2)×h×w;ca代表协调注意力机制,设两个输入特征的大小均为c×h×w,其计算流程如下:
15、
16、
17、式中:c表示通道数;h表示高度;w表示宽度;xc(h,i)表示通道为c、高为h时,第i个像素点;xc(j,w)表示通道为c、宽为w时,第j个像素点;表示在通道c中,对高度h的第w行特征信息求和并取平均;计算方法同理;
18、
19、式中:f1(·)表示特征拼接后,进行1×1卷积运算;δ(·)表示非线性变换,即批量归一化和prelu激活函数的组合;
20、
21、
22、式中:fh、fw分别表示f沿h、w方向降维后的向量;μ(·)表示sigmoid激活函数运算;
23、
24、式中:xc(i,j)表示输入协调注意力机制的骨显像;x'c(i,j)表示经过协调注意力机制计算后的骨显像,即骨显像特征图;
25、步骤3:降噪网络主要由步骤2提出的密集残差注意力卷积块构成,共有2*(n+m)个卷积块,n与m均为大于0的正整数,n为噪声估计网络中u-net的层数,m为主干降噪网络中u-net的层数,整体降噪模型设计为噪声估计网络与主干降噪网络的两阶段式架构,噪声估计网络输出骨显像噪声水平,主干降噪网络输出最终的降噪骨显像;
26、步骤4:使用交叉熵损失和融合感知损失的混合损失函数分别计算噪声估计网络、主干降噪网络的输出损失,使用adam优化器最小化损失函数;
27、交叉熵损失函数计算公式为:
28、
29、式中:ck代表第k张骨显像,p(ck)代表真实噪声水平,q(ck)代表模型预测噪声水平;
30、其中融合感知损失的混合损失函数采用了感知损失函数与均方误差结合的方式:
31、均方误差计算公式为:
32、
33、式中:w、h表示骨显像的宽、高;yi、xi分别代表降噪骨显像与原图;
34、感知损失计算公式为:
35、
36、式中:表示深度学习模型提取到的图像特征;表示深度学习模型提取到的原骨显像特征;表示深度学习模型提取到的降噪骨显像特征;h表示高度;w表示宽度;
37、lh=(1-λ)lmse+λlprec,0≤λ≤1
38、式中:λ为常数,用于平衡两项损失函数;lmse表示均方误差损失函数,用于指导模型进行逐像素级降噪;lprec表示感知损失函数,用于对lmse进行约束、保留骨显像的细节特征;
39、步骤5:将步骤1预处理后的测试集数据,送入步骤3搭建的网络模型中,利用步骤4中设计的融合感知损失的混合损失函数计算损失值,并通过峰值信噪比对模型的降噪效果进行评估,根据最优参数保存最终的网络模型,记为emanet模型;
40、峰值信噪比公式为:
41、
42、式中:w×h表示骨显像大小;maxi表示骨显像中最大像素值;
43、步骤6:利用保存的emanet模型输出最后的降噪骨显像。
44、本发明所提供的一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法,以密集残差注意力卷积块为基本卷积单位,提出了结合密集残差注意力卷积块的两阶段式骨显像降噪网络,首先通过噪声估计网络估计骨显像的噪声水平,然后采用设计的主干降噪网络得到降噪后的骨显像,最后利用融合感知损失混合损失函数优化骨显像降噪效果,本发明公开的骨显像去噪方法,在有效降低骨显像噪声的同时,也能够保留骨显像的病灶细节特征。
45、有益效果:
46、与目前主流的医学影响去噪方法相比,本发明具有以下有益效果:
47、(1)一种融合感知损失和密集残差注意力卷积块的两阶段式骨显像降噪方法能够有效降低骨显像噪声,并且保留病灶细节特征;
48、(2)与常规的医学去噪方法相比,由于使用密集残差注意力卷积块进行特征提取、基于u-net两阶段的降噪架构以及融合感知损失的混合损失函数,模型对噪声特征学习能力更强,在降噪能力上具有更明显的优势;
- 还没有人留言评论。精彩留言会获得点赞!