一种在分布式数据库中实现高可用序列的方法与流程
本发明属于分布式数据库领域,具体涉及一种在分布式数据库中实现高可用序列的方法。
背景技术:
1、随着计算机技术的快速发展和应用的业务领域不断增多,越来越多的数据被产生并被记录在数据库之中。随着时间的累计,数据库中单表的数据量越来越庞大,读写性能开始显著降低。同时传统关系型数据库单点单机部署模式没有解决高可用性的问题,已经不能满足业务应用对数据库高性能、高可用性、高并发的要求。所以,近些年越来越多的企业开始转型使用分布式数据库。分布式数据库为处理单表数据庞大,读写性能下降的问题,会将原本单机关系型数据库中的一张表以记录为维度拆分在多台单机关系型数据库之中。分布式数据库为提供更强大的读写性能,支持更高的并发量,通常会在一个分布式数据库中部署多个计算节点,以用于解析sql、执行sql、组装sql执行结果。对于使用者,可通过分布式数据库客户端任意链接其中一个计算节点执行相关操作。在单机关系型数据库中,一张单表可以使用主键序列生成一个在单表内唯一的值来标识一条记录。在分布式数据库中,当单表被拆分到不同的单机关系型数据库中时,便面临着需要一种功能能够提供在多张单表中均保持唯一的序列值。
2、传统的唯一序列值方案都是在分布式数据库之外独立部署一套系统。使用者需要首先链接该系统获取到独立序列值,再组装sql,再发送给分布式数据库,比如在redis中存储一个key不断自增,它们的优点是方案成熟可靠,确实可以提供唯一序列值。但是独立部署系统,意味着需要额外的软硬件,额外的开发运维人员,同时对于使用者来说需要同时保持和两套系统的链接,此举无疑加大了应用系统的开发和运维人员的工作复杂度。
3、传统的唯一序列值实现方式为了保证更高的并发度,往往选择通过内存方式实现,比如雪花算法,通过使用计算机的时钟作为种子用特定的算法生成一个永不重复的值来作为序列值,它们的优点是实现简单、性能高,但同时可用性低,且无法有效解决机器时钟回拨问题,易出现序列值重复的问题。因而通常基于内存的方式多用于对唯一性要求不是那么苛刻的场合。
技术实现思路
1、本发明旨在解决现有技术的缺陷和问题,在分布式数据库中,序列值需要同时考虑到高可用性,高性能以及严苛的不可重复性,从而让分布式数据库更高效、可靠、安全的提供序列值;本发明由分布式数据库中的多个计算节点直接提供序列值,并自动更新序列缓存;使用两个序列库同时提供序列服务,以保证了序列服务的高可用性;通过自定义的算法规则实现不同序列库之间的序列的唯一性,以保证序列值在整个分布式系统中的唯一性。应用程序开发人员不用再关注序列的获取,序列值的重复等非业务问题,从而可以将工作的重心放在自身业务上。
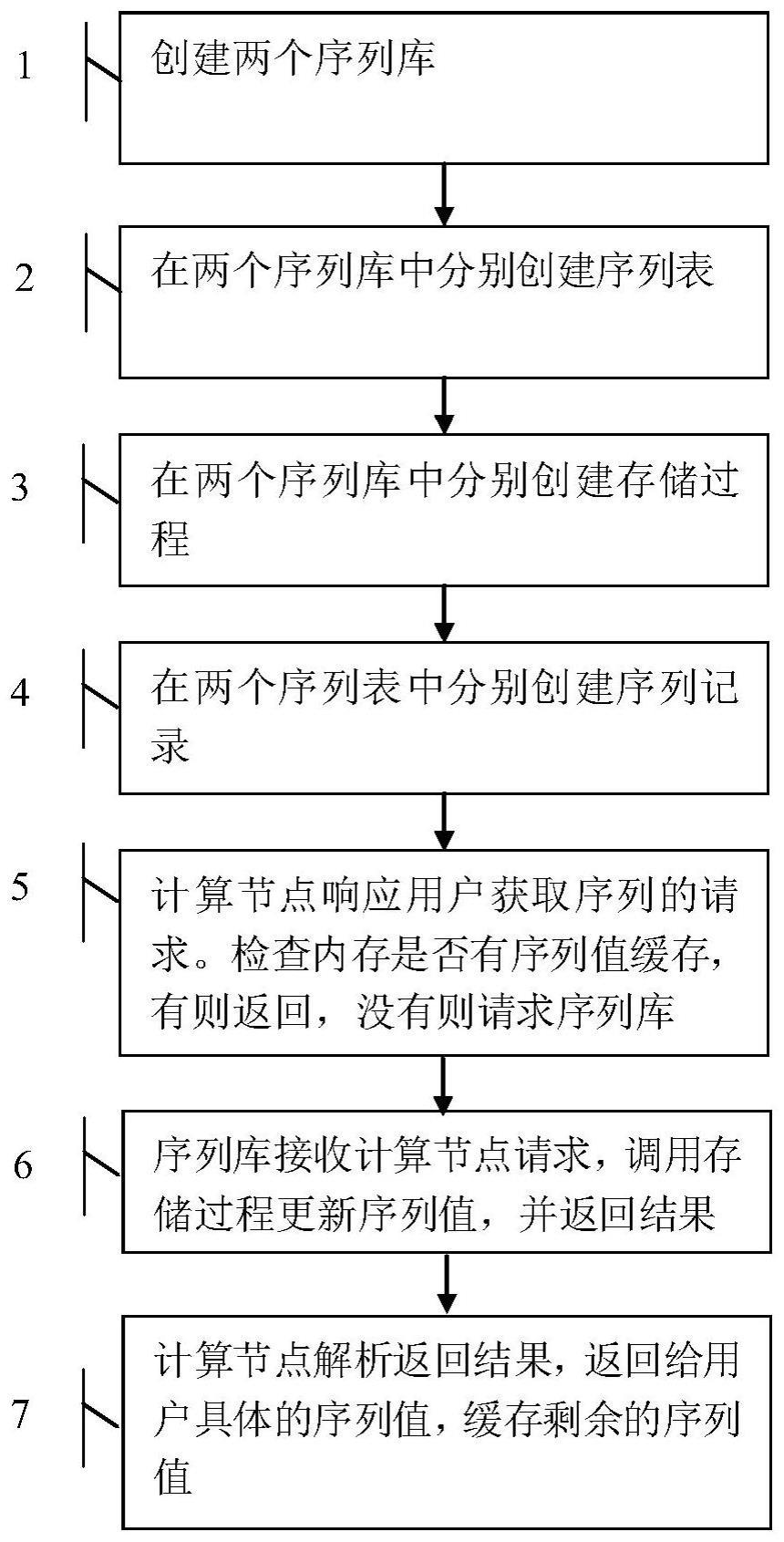
2、为解决上述技术问题,本发明提供一种在分布式数据库中实现高可用序列的方法,具体包括:
3、步骤1:在两个互不相关的数据库中分别各创建一个序列库;为保证序列库的稳定性,应当限定一个序列库同一时间允许的最大连接数,若当前计算节点同一时间的请求数量大于序列库设定的最大连接数,则序列库应当拒绝接收新的请求;
4、步骤2:在步骤1创建的两个序列库中各创建一张序列表,所述序列表的字段信息包括:表主键、序列名称、序列起始值、序列步长和单个计算节点应当缓存的序列值个数;所述序列名称用于区分不同的序列;所述序列起始值是计算序列时的初始值,每一个新生成的序列都在序列表中更新;所述序列步长是序列值的增长速度,记为每两个连续序列的差值;
5、步骤3:在步骤1创建的两个序列库中各创建一个存储过程;所述存储过程是用于处理特定复杂逻辑的程序片段,所述存储过程接收序列名称作为输入参数,输出一个字符串作为输出参数;所述存储过程将接收到的序列名称转换为大写,根据序列名称找到序列表中对应的序列记录,依照预设算法更新其序列起始值,更新成功则返回指定格式的字符串,更新失败则返回预设的字符串;
6、步骤4:待步骤3完成后,在两个序列表中分别创建序列记录;具体为:在两个序列表中各创建一条序列名称完全相同的序列记录,两条同名的序列记录的序列步长相同且均为10的倍数,序列起始值的个位数数字相同,但十位数一个为奇数,一个为偶数;
7、步骤5:计算节点接收到用户提取序列的请求,根据序列名称从本地缓存中查找是否有可用序列,若有可用序列,则消耗一个序列值返回给用户,若没有可用序列,则将序列名称发送给序列库以获取序列;具体为:计算节点通过心跳检测确认序列库是否正常;若其中一个序列库异常则在另一个序列库中生成序列,若两个序列库均正常则随机选择其中一个用于生成序列;若失败则重新选择另一个库生成序列;若两个序列库均心跳检测结果异常,计算节点会持续等待直至序列库恢复正常;计算节点调用选中的序列库上的存储过程获取返回值;
8、步骤6:序列库接收到计算节点的请求后,返回指定格式的字符串给计算节点;
9、步骤7:计算节点获取到序列库返回的指定格式的字符串后,计算序列值,并返回给用户。
10、所述步骤1中,所述单点数据库在独立部署的mysql上创建;序列由两个序列库中任意一个生成。
11、在所述步骤2中,表主键名称为id,类型为bigint型,长度为20,使用单机数据库的主键自增长属性;字段seq_name用于存储序列名称,类型为varchar,长度为255;字段curr_val存放序列的起始值,类型为bigint,长度为20;字段step_val用于保存序列的步长,类型为int,长度为11;字段cache_nums用于保存计算节点的缓存数量,类型为int,长度为11;在字段seq_name上创建唯一索引。
12、在所述步骤3中,所述两个序列库中的存储过程相同,均使用sql编写,部署在具体的mysql上,存储过程名为focus_sequence_func,类型为function,上述存储过程定义了一个接收参数,类型为vachar,长度为255,名称为v_seq_name,返回类型为varchar,长度为64,所述指定格式的的字符串是由序列起始值、字符串链接符号、序列起始值需要增加的数值、字符串链接符号和序列步长组成的一个字符串;所述预设的字符串包括-1和-2;所述预设算法为:新的序列起始值=当前的序列起始值+计算节点应当缓存的序列个数×序列步长。
13、所述步骤3中具体步骤包含:
14、步骤3-1:预定义四个变量,分别为long类型的v_curr_val,int类型的v_step_val,int类型的v_increment和int类型的v_updaterowcount;所述四个变量分别用于保存序列起始值、序列步长、序列起始值需要增加的数值和变更的序列记录数量;
15、步骤3-2:将传入的v_seq_name转为大写字母,表中的seq_name转为大写,查询出两个值相同的序列记录;计算v_increment值,计算公式为:v_increment=cache_nums*step_val;判断v_cur_val值是否为空,如果为空则返回字符串-2,不为空则继续步骤3-3;
16、步骤3-3:计算新的序列起始值,计算公式为:新v_curr_val=v_curr_val+v_increment,使用新v_curr_val值更新步骤3-2中查询出的序列记录;判断更新的序列记录的数量,如果为0行,则返回字符串-1;否则返回指定格式字符串,字符串格式为:v_curr_val值,英文逗号,v_increment值,英文逗号,v_step_val值。
17、在所述步骤5中,当计算节点启动后,根据地址、账号和密码和两个序列库分别建立心跳检测;计算节点初始化一个map数据结构,使用分布式数据库的schema名称拼接##符号再拼接序列名作为key,使用一个序列值队列作为value;使用者向计算节点请求指定名称的序列值,计算节点执行如下步骤:
18、步骤5-1:计算节点使用该key查询map数据结构,若获取的值不为空则执行步骤5-2,若获取的值为空则构造新的空的序列值队列,并保存在map数据结构中,继续执行步骤5-2;
19、步骤5-2:检查步骤5-1获取到的序列值队列,若不为空,则从中提取出一个具体的序列值返回给请求者,若序列值队列为空,则执行步骤5-4;检查序列值队列的长度,若上一次序列值队列的长度大于100,当前序列值队列长度小于上一次的一半,则执行步骤5-4;若上一次序列值队列的长度小于100,当前序列值队列的长度小于50,则执行步骤5-4;序列值队列长度不符合前述两个条件,则执行步骤5-3;
20、步骤5-3:计算节点完成本次返回序列值操作,进入等待下一次请求;
21、步骤5-4:计算节点请求序列库生成新一批的序列值;检查两个序列库是否正常,若正常则随机调用其中一个的存储过程,获得返回结果字符串;若字符串为-1或-2,则向另一个序列库重复执行步骤5-4;否则解析返回的字符串,执行步骤7。
22、所述步骤7中,计算节点收到指定格式的字符串后解析提取出序列起始值、序列增长值和序列步长,计算节点计算出序列值,并返回其中一个序列值给用户,其余的序列值缓存在本地内存中留待下次使用。
23、所述步骤7中,计算节点计算出序列值包括:第一步,计算序列最大值,计算公式为:序列最大值=序列起始值+序列增长值;第二步,逐一计算具体的序列值,计算公式为:序列值=序列起始值+序列步长;第三步,判断第二步序列值是否大于第一步序列最大值,若大于则生成序列的步骤结束,若小于则重复第二步。
24、在所述步骤7还包括,以计算出的序列值更新本地的序列缓存;依照步骤3-3中的规则,从序列库的返回值中,依次提取出v_curr_val、v_increment和v_step_val;以返回的v_curr_val为基础,逐次增加值v_step_val;每加一次值后,若新的v_curr_val大于等于返回的v_curr_val与v_increment之和,则结束操作,若新的v_curr_val小于返回的v_curr_val与v_increment之和,则放入步骤5-2获取的序列值队列之中。
25、本发明所达到的有益效果:
26、(1)本发明通过使用单机关系型数据库来持久化保存序列信息,解决了传统序列使用内存保存序列无法实现可靠持久性的问题;
27、(2)本发明通过使用多个,至少两个,序列库保证了序列生成的高可靠;
28、(3)本发明设计了新的序列生成算法,保证了序列值的永不重复,避免了传统的基于时间的雪花算法面临的时间回退,序列值长度过长等问题;
29、(4)本发明通过多计算节点缓存序列值,由计算节点为用户提供序列服务的方式,提高了序列生成功能的并发性,增强了性能。
- 还没有人留言评论。精彩留言会获得点赞!