一种基于数据分布差异的聚类联邦方法及装置
本发明涉及的是数据分布,尤其涉及一种基于数据分布差异的聚类联邦方法及装置。
背景技术:
1、联邦学习是一种机器学习框架,它能够在保护本地客户端数据隐私的情况下,允许本地客户端参与到对大规模分布式数据的联合统计模型的训练。联邦学习最常见的设置是使用一个中央实体(服务端)聚合来自许多客户端的本地学习模型,学习一个全局最优模型,希望全局模型性能向中心化训练模型性能靠拢。联邦学习已被证明在数据以独立同分布方式分布(iid)的情况下运行良好。最常用的联邦平均算法(fedavg)以单一客户端样本数量占所有客户端样本数量的比例作为权重,在服务端以模型参数加权平均的方式聚合全局模型。在实际场景中,数据大量分布在客户端之间,数据可能是非独立同分布(non-iid)的,这不利于训练出一个最优的全局模型。
2、现有工作中,研究人员从本地端模型更新、服务端模型聚合两个方向出发,提出方法来改善non-iid场景下的模型训练问题,分别取得了一定效果。但是,在non-iid场景下,不同客户端的数据集表现出较大的差异性,全局模型无法良好地适配到每一个客户端数据集的训练上。聚类联邦方法的提出有效地缓解了这一问题。客户端将本地训练模型上传到服务端,服务端计算本地训练模型间的差异性,进行客户端聚类,将差异较大模型对应的客户端归于不同的集群,达到提升聚类中心模型训练精度的目的。
3、现有聚类联邦算法多从模型层面出发,主要以模型参数的差异性作为客户端聚类依据。在non-iid场景下,客户端数据集存在着样本数量不足、部分样本特征缺失、两个样本间同一特征值差异过大等问题。这些问题将导致模型参数在训练过程中产生一定程度的偏差,对聚类过程造成不利影响。因此考虑到原始数据对聚类效果的影响是必要的。
技术实现思路
1、本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
2、鉴于上述存在的问题,提出了本发明。
3、因此,本发明解决的技术问题是:客户端数据集存在着样本数量不足、部分样本特征缺失、两个样本间同一特征值差异过大等问题。
4、为解决上述技术问题,本发明提供如下技术方案:
5、第一方面,本发明实施例提供了一种基于数据分布差异的聚类联邦方法,包括:
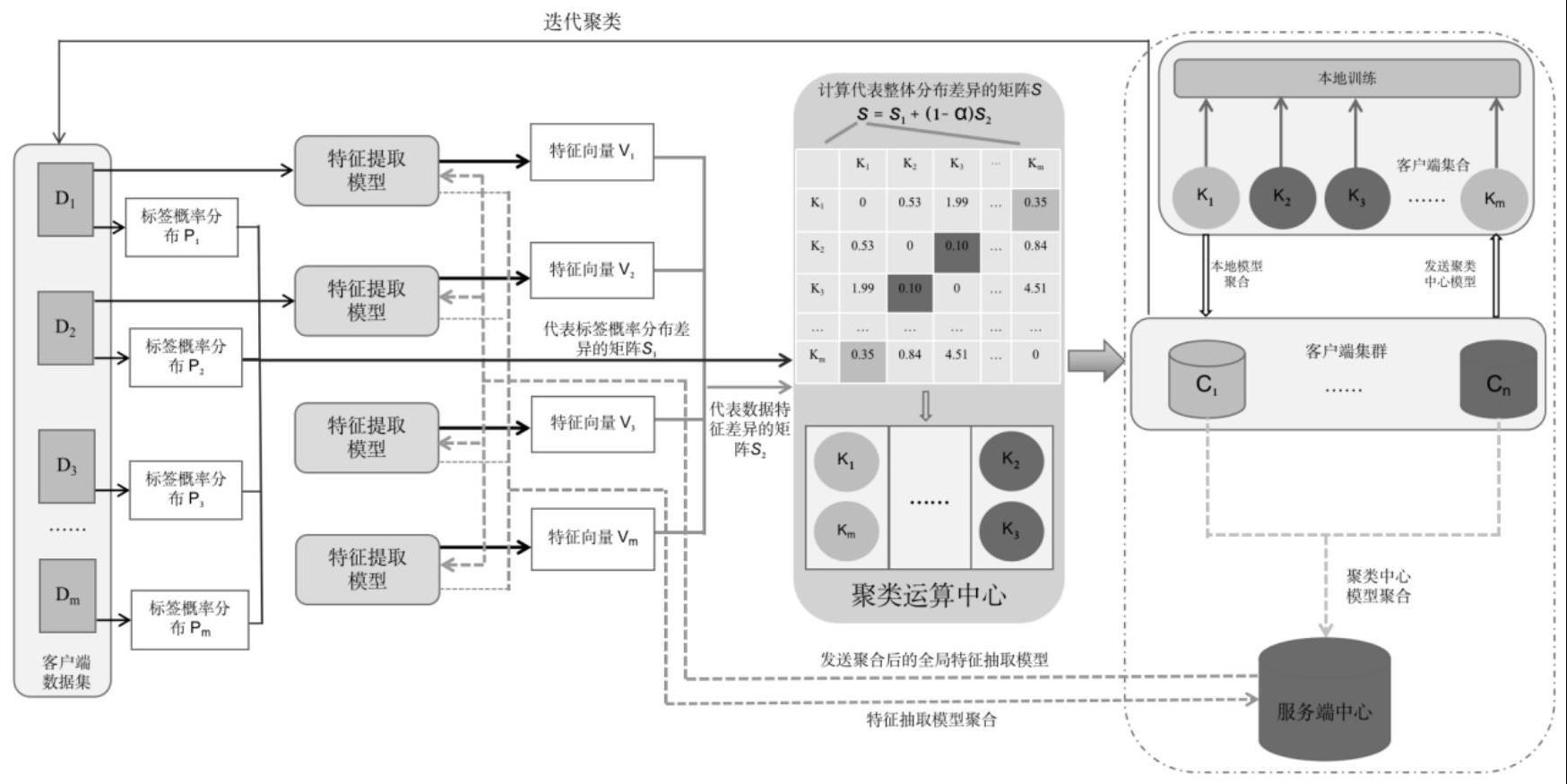
6、根据原始数据集的标签类别和标签对应的样本数量,计算原始数据集的标签概率分布及分布差异;
7、利用特征提取网络,提取与原始数据集相关的数据特征向量;
8、基于所述数据特征向量,计算客户端数据集间关于数据特征分布的差异情况;
9、基于所述数据集的标签概率分布和所述数据特征分布的差异情况,进行聚类运算,得到客户端集群,将所述客户端集群进行迭代聚类。
10、作为基于数据分布差异的聚类联邦方法的一种优选方案,其中:
11、所述计算原始数据集的标签概率分布包括:针对某一客户端p,统计数据集dp所包含的样本总数m和标签种类数目n;分别统计每一个标签类别所包含的样本数目mi(i=1,2,……,n),以比值mi/m作为第i类标签的概率分布值。
12、作为基于数据分布差异的聚类联邦方法的一种优选方案,其中:
13、所述计算原始数据集的标签概率分布差异包括:定义数据集dp、dq之间标签概率分布差异的计算方式为:
14、
15、其中p(i|dp)表示数据集dp中标签i对应样本数量占总样本数的比例,n表示数据集中标签的类别数量;s1是代表标签概率分布差异的矩阵s1的组成元素。
16、作为基于数据分布差异的聚类联邦方法的一种优选方案,其中:
17、所述提取与原始数据集相关的数据特征向量包括:选取特征提取网络,每个客户端p将原始数据集dp作为网络输入,进行网络训练;网络训练完成后,输出2048维的特征向量vi,完成特征提取。
18、作为基于数据分布差异的聚类联邦方法的一种优选方案,其中:
19、所述聚类运算包括:获得客户端(k1、k2……km)数据集的标签概率分布之后,根据相对熵公式计算不同客户端之间的标签概率分布差异;获得每个客户端数据集的数据特征分布之后,根据协方差矩阵公式计算不同客户端之间的数据特征分布差异;整合两部分差异,合成距离矩阵s,s是一个m*m的矩阵,其中sij代表客户端i和客户端j之间的数据分布差异,将s作为输入参数加入到聚类运算过程中,得到客户端集群(c1、c2……cn)。
20、作为基于数据分布差异的聚类联邦方法的一种优选方案,其中:
21、所述迭代聚类包括:在每一轮训练过程中,客户端抽取数据特征操作完成后,服务端对所有特征提取模型进行模型聚合,然后将聚合后的全局特征提取模型返还给客户端,用作下一轮的数据特征抽取操作。
22、作为基于数据分布差异的聚类联邦方法的一种优选方案,其中:
23、所述服务端对所有特征提取模型进行模型聚合包括:聚合方式采用基于训练准确率的加权平均方法,具体步骤包括:客户端集群将聚类中心模型下发到集群内的所有客户端,客户端进行本地训练,将每一轮训练结束得到的局部模型和训练准确率发送给集群;集群记录各个客户端每一轮的训练准确率,并将最后三轮的训练准确率平均值作为局部模型的聚合权重,加权平均生成新的聚类中心模型。
24、第二方面,本发明实施例提供了一种系统,其特征在于,包括:
25、标签概率分布差异计算模块,用于根据原始数据集的标签类别和标签对应的样本数量,计算原始数据集的标签概率分布及分布差异;
26、数据特征分布差异计算模块,用于利用特征提取网络,提取与原始数据集相关的数据特征向量;基于所述数据特征向量,计算客户端数据集间关于数据特征分布的差异情况;
27、聚类模块,用于基于所述数据集的标签概率分布和所述数据特征分布的差异情况,进行聚类运算,得到客户端集群,将所述客户端集群进行迭代聚类。
28、第三方面,本发明实施例提供了一种计算设备,包括:
29、存储器和处理器;
30、所述存储器用于存储计算机可执行指令,所述处理器用于执行所述计算机可执行指令,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本发明任一实施例所述的基于数据分布差异的聚类联邦方法。
31、第四方面,本发明实施例提供了一种计算机可读存储介质,其存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现所述的基于数据分布差异的聚类联邦方法。
32、本发明的有益效果:本发明主要考虑在联邦学习中数据分布间的差异性对客户端聚类结果的影响,提供一种基于数据分布差异的聚类联邦方法,从数据集标签概率分布与数据内部特征分布两个方向出发,引入不同客户端数据分布间差异性的计算,结合现有聚类方法,生成较为准确的客户端集群,获得了较好的训练结果。
- 还没有人留言评论。精彩留言会获得点赞!