车辆检查视频合格检测方法、装置、设备及存储介质与流程
本发明涉及视频合格检测,尤其涉及一种车辆检查视频合格检测方法、装置、设备及存储介质。
背景技术:
1、在汽车启动前,有许多驾驶人员时常忘记绕车一周的交通规范,这样容易发生碾压或者碰撞事故。检查车辆外观,如轮胎是否有问题,车辆内部设施如喇叭、灯光、油、水、电、刹车等是否正常,避免行车过程出现问题。检车车辆能够及时掌握车队车辆技术状况,发现问题及时解决,为车队安全运营保驾护航。
2、车辆三检查指的是车主在出车前进行检查、行车途中进行检查、收车后进行检查,即驾驶前、驾驶时、驾驶后对车进行检查。目的是为了保证行车安全,防止因机件故障而造成意外事故。为了规范和监督驾驶员的行为,要求驾驶员将车辆三检视频上传专门审核系统,然后由后台工作人员进行审核三检是否合格。现有检测方法需要工作人员一个一个的去审核视频是否合格,其工作量较大,工作效率较低。
3、因此,现有技术还有待于改进和发展。
技术实现思路
1、本发明的主要目的在于解决现有技术需要工作人员去审核车辆检查视频是否合格,其工作量较大,工作效率较低的问题。
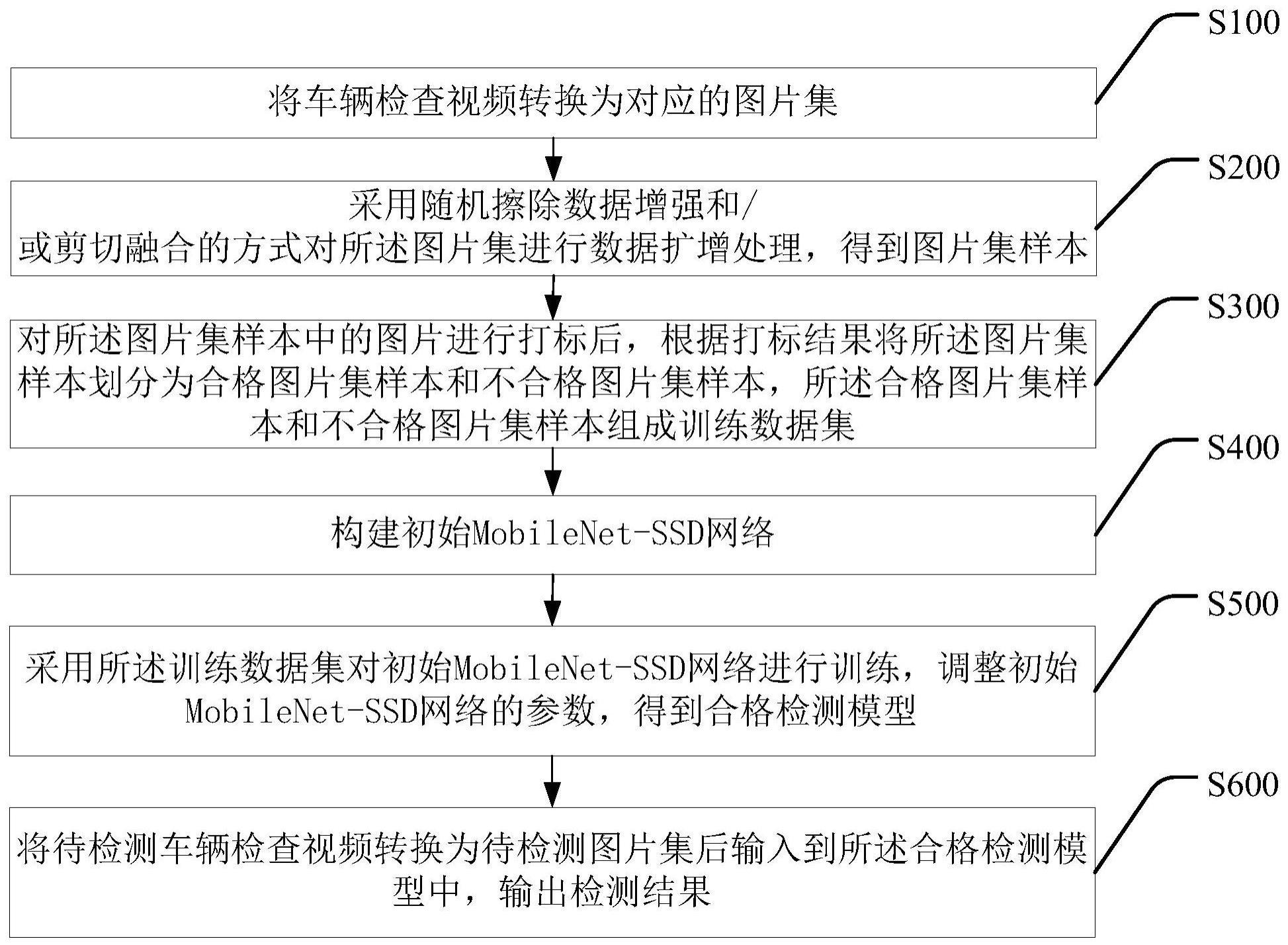
2、本发明第一方面提供了一种车辆检查视频的合格检测方法,包括:将车辆检查视频转换为对应的图片集;采用随机擦除数据增强和/或剪切融合的方式对所述图片集进行数据扩增处理,得到图片集样本;对所述图片集样本中的图片进行打标后,根据打标结果将所述图片集样本划分为合格图片集样本和不合格图片集样本,所述合格图片集样本和不合格图片集样本组成训练数据集;构建初始mobilenet-ssd网络;采用所述训练数据集对初始mobilenet-ssd网络进行训练,调整所述初始mobilenet-ssd网络的参数,得到合格检测模型;将待检测车辆检查视频转换为待检测图片集后输入到所述合格检测模型中,输出检测结果。
3、可选的,在本发明第一方面的第一种实现方式中,所述将车辆检查视频转换为对应的图片集,包括:获取车辆检查视频的参数,并读取所述车辆检查视频每一帧的数据;根据每一帧的数据,获取由亮度和色度空间表示的数字图像信号数据;将所述数字图像信号数据转换为图片,每个车辆检查视频转换的所有图片组成对应的图片集。
4、可选的,在本发明第一方面的第二种实现方式中,所述采用随机擦除数据增强的方式对所述图片集进行数据扩增处理,包括:将图片集中大小为s的图片i进行输入,s=w*h,w和h分别为图片i的宽度和高度,设置擦除面积比范围[sl,sh]和擦除纵横比范围[r1,r2],初始化擦除概率p为0-1;随机选择图片i中的矩形区域域ie,并用随机值擦除其像素,其中将矩形区域ie面积随机初始化为se,将擦除纵横比随机初始化为re,se/s在[sl,sh]范围内,re在[r1,r2]范围内,ie的面积大小通过如下公式进行计算:we与he是随机擦除的矩形区域ie的长与宽;随机初始化图片i中的一个点p=(xe,ye),xe与ye是随机初始化的点坐标;对擦除部分进行判断,如果xe+we≤w,ye+he≤h,则将区域(xe,ye,xe+we,ye+he)设置为选中的矩形区域ie;否则,重复上述过程,直到选择满足要求的矩形区域ie,对于选定的矩形区域ie,其中的每个像素分别被分配给[0,255]中的随机值。
5、可选的,在本发明第一方面的第三种实现方式中,所述采用剪切融合的方式对所述图片集进行数据扩增处理,包括:将图片集中的一张图片随机删除部分区域;从图片集中的另一张图片中截取相同大小的区域填充到上一张图片的删除部分区域,并进行全图软融合生成新的图片,实现数据扩增。
6、可选的,在本发明第一方面的第四种实现方式中,所述对所述图片集样本中的图片进行打标后,根据打标结果将所述图片集样本划分为合格图片集样本和不合格图片集样本,所述合格图片集样本和不合格图片集样本组成训练数据集,包括:采用打标软件对所述图片集样本中图片上的目标区域进行不同形状的框选,所述目标区域包括轮胎区域和车牌区域;若一个图片集样本同时包括两种不同形状的框选,则判定所述图片集样本为合格图片集样本;若一个图片集样本只包括一种形状的框选或不含框选,则判定所述图片集样本为不合格图片集样本;将所述合格图片集样本和不合格图片集样本组成训练数据集。
7、可选的,在本发明第一方面的第五种实现方式中,所述构建初始mobilenet-ssd网络,包括:以mobilenet v1模型为基础,保留mobilenet v1模型中conv0到conv13的配置,并去掉mobilenet v1模型中最后的全局平均池化、全连接层和softmax层,作为mobilenet-ssd网络的基础部分;将vgg16-ssd模型中的vgg16部分去除,将剩余的ssd部分与所述基础部分组合,构建初始mobilenet-ssd网络,所述初始mobilenet-ssd网络用于从六个不同尺度的特征图上提取特征并做识别。
8、可选的,在本发明第一方面的第六种实现方式中,所述采用所述训练数据集对初始mobilenet-ssd网络进行训练,调整所述初始mobilenet-ssd网络的参数,得到合格检测模型,包括:将所述训练数据集中的图片输入到位于前端的mobilenet网络,得到图片的基本特征和最终特征;用8个不同尺度的卷积层在不同尺度上做特征提取,抽取6个不同层级的特征图,并在图中不同伟指出选取大小不同、纵横比不同的默认框;计算每个所述默认框与实际位置坐标相比存在的位置偏移量,以及预测类别与实际目标类别相同的概率,及类别得分;根据默认框与实际位置坐标相比存在的位置偏移量计算最终边界框的位置损失函数,然后再根据类别得分计算默认框的分类损失函数,两者的加权和为最终的总体损失函数;将所述总体损失函数反向传播,调整mobilenet-ssd网络中各网络层的权值,得到合格检测模型。
9、本发明第二方面提供了一种车辆检查视频的合格检测装置,包括:转换模块,用于将车辆检查视频转换为对应的图片集;扩增模块,用于采用随机擦除数据增强和/或剪切融合的方式对所述图片集进行数据扩增处理,得到图片集样本;打标模块,用于对所述图片集样本中的图片进行打标后,根据打标结果将所述图片集样本划分为合格图片集样本和不合格图片集样本,所述合格图片集样本和不合格图片集样本组成训练数据集;构建模块,用于构建初始mobilenet-ssd网络;训练模块,用于采用所述训练数据集对初始mobilenet-ssd网络进行训练,调整所述初始mobilenet-ssd网络的参数,得到合格检测模型;输出模块,用于将待检测车辆检查视频转换为待检测图片集后输入到所述合格检测模型中,输出检测结果。
10、可选的,在本发明第二方面的第一种实现方式中,所述转换模块包括:读取单元,用于获取车辆检查视频的参数,并读取所述车辆检查视频每一帧的数据;获取单元,用于根据每一帧的数据,获取由亮度和色度空间表示的数字图像信号数据;转换单元,用于将所述数字图像信号数据转换为图片,每个车辆检查视频转换的所有图片组成对应的图片集。
11、可选的,在本发明第二方面的第二种实现方式中,所述扩增模块包括:随机擦除扩增单元,用于将图片集中大小为s的图片i进行输入,s=w*h,w和h分别为图片i的宽度和高度,设置擦除面积比范围[sl,sh]和擦除纵横比范围[r1,r2],初始化擦除概率p为0-1;随机选择图片i中的矩形区域域ie,并用随机值擦除其像素,其中将矩形区域ie面积随机初始化为se,将擦除纵横比随机初始化为re,se/s在[sl,sh]范围内,re在[r1,r2]范围内,ie的面积大小通过如下公式进行计算:we与he是随机擦除的矩形区域ie的长与宽;随机初始化图片i中的一个点p=(xe,ye),xe与ye是随机初始化的点坐标;对擦除部分进行判断,如果xe+we≤w,ye+he≤h,则将区域(xe,ye,xe+we,ye+he)设置为选中的矩形区域ie;否则,重复上述过程,直到选择满足要求的矩形区域ie,对于选定的矩形区域ie,其中的每个像素分别被分配给[0,255]中的随机值;剪切融合扩增单元,用于将图片集中的一张图片随机删除部分区域;从图片集中的另一张图片中截取相同大小的区域填充到上一张图片的删除部分区域,并进行全图软融合生成新的图片,实现数据扩增。
12、可选的,在本发明第二方面的第三种实现方式中,所述打标模块包括:框选单元,用于采用打标软件对所述图片集样本中图片上的目标区域进行不同形状的框选,所述目标区域包括轮胎区域和车牌区域;第一判定单元,用于若一个图片集样本同时包括两种不同形状的框选,则判定所述图片集样本为合格图片集样本;第二判定单元,用于若一个图片集样本只包括一种形状的框选或不含框选,则判定所述图片集样本为不合格图片集样本;组合单元,用于将所述合格图片集样本和不合格图片集样本组成训练数据集。
13、可选的,在本发明第二方面的第四种实现方式中,所述构建模块包括:第一构建单元,用于以mobilenet v1模型为基础,保留mobilenet v1模型中conv0到conv13的配置,并去掉mobilenet v1模型中最后的全局平均池化、全连接层和softmax层,作为mobilenet-ssd网络的基础部分;第二构建单元,用于将vgg16-ssd模型中的vgg16部分去除,将剩余的ssd部分与所述基础部分组合,构建初始mobilenet-ssd网络,所述初始mobilenet-ssd网络用于从六个不同尺度的特征图上提取特征并做识别。
14、可选的,在本发明第二方面的第五种实现方式中,所述训练模块包括,输入单元,用于将所述训练数据集中的图片输入到位于前端的mobilenet网络,得到图片的基本特征和最终特征;特征提取单元,用于用8个不同尺度的卷积层在不同尺度上做特征提取,抽取6个不同层级的特征图,并在图中不同伟指出选取大小不同、纵横比不同的默认框;第一计算单元,用于计算每个所述默认框与实际位置坐标相比存在的位置偏移量,以及预测类别与实际目标类别相同的概率,及类别得分;第二计算单元,用于根据默认框与实际位置坐标相比存在的位置偏移量计算最终边界框的位置损失函数,然后再根据类别得分计算默认框的分类损失函数,两者的加权和为最终的总体损失函数;调整单元,用于将所述总体损失函数反向传播,调整mobilenet-ssd网络中各网络层的权值,得到合格检测模型。
15、本发明第三方面提供了一种车辆检查视频的合格检测设备,其包括存储器和至少一个处理器,所述存储器中存储有计算机可读指令;所述至少一个处理器调用所述存储器中的所述计算机可读指令,以执行如上所述车辆检查视频的合格检测方法的各个步骤。
16、本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机可读指令,其特征在于,所述计算机可读指令被处理器执行时实现如上所述车辆检查视频的合格检测方法的各个步骤。
17、本发明的技术方案中,将车辆检查视频转换为对应的图片集;对图片集进行数据扩增处理,得到图片集样本;对图片集样本中的图片进行打标后,根据打标结果将图片集样本划分为合格图片集样本和不合格图片集样本,所述合格图片集样本和不合格图片集样本组成训练数据集;采用训练数据集对初始mobilenet-ssd网络进行训练,得到合格检测模型;将待检测车辆检查视频转换为待检测图片集后输入到合格检测模型中,输出检测结果。本发明采用视觉算法识别车辆检查视频是否合格,不用通过人工去审核视频是否合格,可有效提高工作效率,更及时的监督驾驶员的行为,减少事故的发生。
- 还没有人留言评论。精彩留言会获得点赞!