冗余数据表监测方法、装置、计算机设备及存储介质与流程
本技术涉及人工智能,尤其涉及一种冗余数据表监测方法、装置、计算机设备及存储介质。
背景技术:
1、随着大数据概念的普及以及大数据的相关技术进步,大型企业或多或少都部署了大数据的应用,以满足企业各种各样的需求。很多企业都开展了企业整体数据战略,以指导企业内部各个业务部门和业务线进行数据的提取、整合和管理,建立了数据使用的相关规范,包括统一的数据字典、数据分析工具等,这些都有利于后期的数据整合和利用。但是大量的数据导入到数据库中后,由于是多个团队和个人共建一个数据仓库,会产生很多表结构极为相似的冗余数据表。这些冗余数据表会占用大量的磁盘空间,既不便于数据仓库在数据加工生成过程中数据源定位,又会产生大量资源浪费。
2、在实现本技术的过程中,申请人发现现有技术存在如下问题:在对数据库中的冗余数据表进行监测时,主要通过比较表对应存储文件的哈希值来检测冗余数据表,仅限于文件的角度进行冗余数据表的分析和判断,无法保证冗余数据表监测的准确性。
3、因此,有必要提供一种冗余数据表监测方法,能够提高冗余数据表监测的准确性。
技术实现思路
1、鉴于以上内容,有必要提出一种冗余数据表监测方法、冗余数据表监测装置、计算机设备及存储介质,能够提高冗余数据表监测的准确性。
2、本技术实施例第一方面提供一种冗余数据表监测方法,所述冗余数据表监测方法包括:
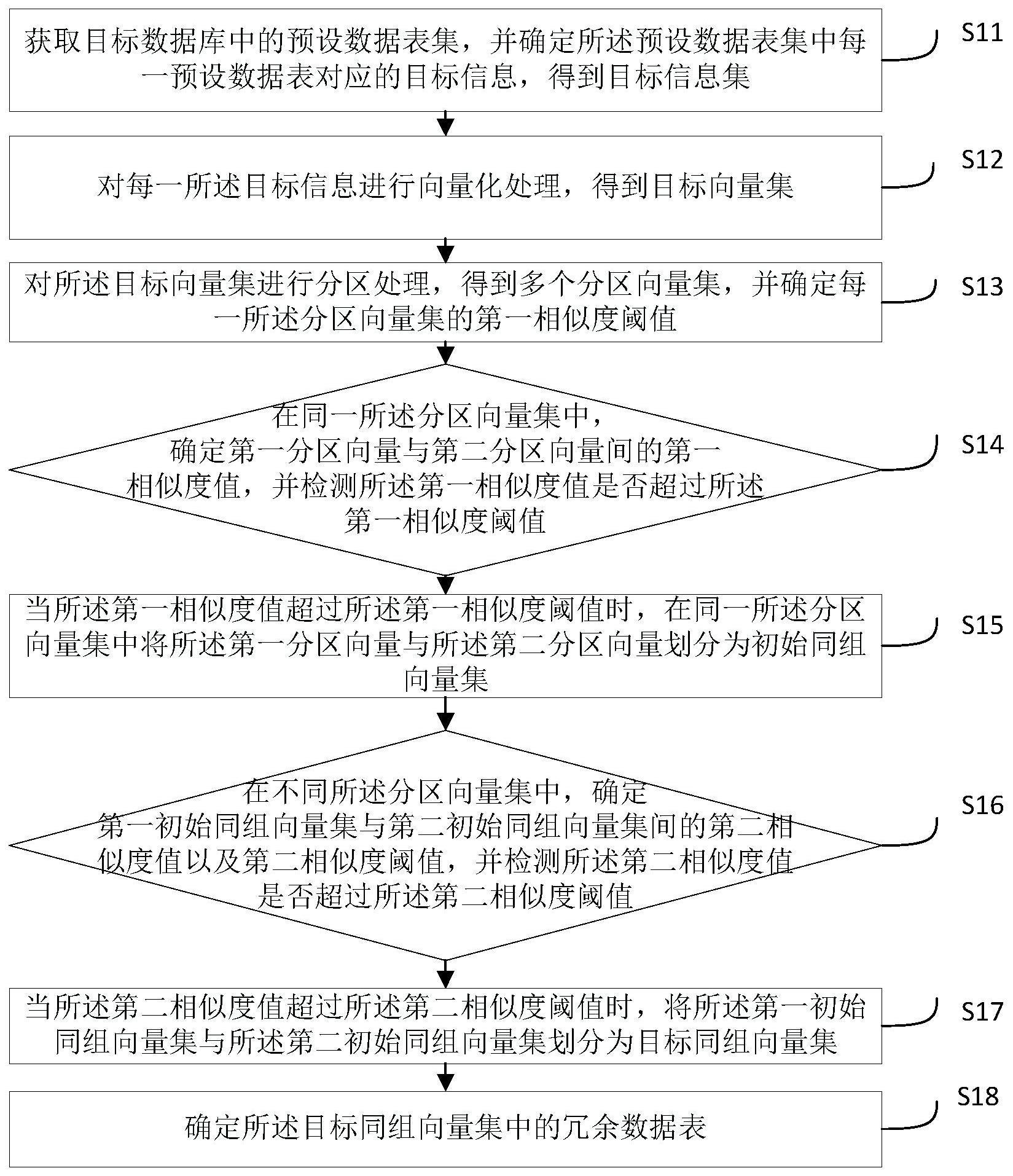
3、获取目标数据库中的预设数据表集,并确定所述预设数据表集中每一预设数据表对应的目标信息,得到目标信息集;
4、对每一所述目标信息进行向量化处理,得到目标向量集;
5、对所述目标向量集进行分区处理,得到多个分区向量集,并确定每一所述分区向量集的第一相似度阈值;
6、在同一所述分区向量集中,确定第一分区向量与第二分区向量间的第一相似度值,并检测所述第一相似度值是否超过所述第一相似度阈值;
7、当所述第一相似度值超过所述第一相似度阈值时,在同一所述分区向量集中将所述第一分区向量与所述第二分区向量划分为初始同组向量集;
8、在不同所述分区向量集中,确定第一初始同组向量集与第二初始同组向量集间的第二相似度值以及第二相似度阈值,并检测所述第二相似度值是否超过所述第二相似度阈值;
9、当所述第二相似度值超过所述第二相似度阈值时,将所述第一初始同组向量集与所述第二初始同组向量集划分为目标同组向量集;
10、确定所述目标同组向量集中的冗余数据表。
11、进一步地,在本技术实施例提供的上述冗余数据表监测方法中,所述确定所述预设数据表集中每一预设数据表对应的目标信息,得到目标信息集,包括:
12、获取所述预设数据表集中每一预设数据表的初始字段描述信息;
13、检测所述初始字段描述信息中是否存在预设描述关键词;
14、当所述初始字段描述信息中存在所述预设描述关键词时,将所述预设描述关键词替换为目标描述关键词,得到目标字段描述信息;
15、获取所述预设数据表对应的字段信息与名称信息,并按照预设格式组合所述字段信息、所述名称信息以及所述目标字段描述信息,得到目标信息;
16、组合所述目标信息,得到目标信息集。
17、进一步地,在本技术实施例提供的上述冗余数据表监测方法中,在所述对每一所述目标信息进行向量化处理,得到目标向量集之后,所述方法还包括:
18、确定所述目标向量对应的类内散度矩阵;
19、确定所述目标向量对应的类间散度矩阵;
20、将所述类内散度矩阵的逆矩阵与所述类间散度矩阵相乘,得到目标矩阵;
21、确定所述目标矩阵对应的多个特征值,并从所述特征值中获取数值排名位于预设排名阈值之前的特征值作为目标特征值集合;
22、根据所述目标特征值集合中每一特征值对应的特征向量,确定所述目标向量对应的投影矩阵;
23、将所述投影矩阵的转置矩阵乘以所述目标向量,得到降维后的所述目标向量。
24、进一步地,在本技术实施例提供的上述冗余数据表监测方法中,所述对所述目标向量集进行分区处理,得到多个分区向量集,包括:
25、获取所述目标向量集中每一目标向量对应的所述字段信息;
26、根据所述字段信息确定每一所述目标向量对应的字段数量;
27、将所述字段数量在预设范围内的所述目标向量划分为同一分区,得到多个分区向量集。
28、进一步地,在本技术实施例提供的上述冗余数据表监测方法中,所述确定每一所述分区向量集的第一相似度阈值,包括:
29、获取每一所述分区向量集的目标分区标识;
30、获取预先设置的分区标识与相似度阈值的映射关系;
31、根据所述目标分区标识遍历所述映射关系,得到每一所述分区向量集对应的第一相似度阈值。
32、进一步地,在本技术实施例提供的上述冗余数据表监测方法中,所述确定第一分区向量与第二分区向量间的第一相似度值,包括:
33、获取预设距离计算模型;
34、调用所述预设距离计算模型处理所述第一分区向量与所述第二分区向量,得到所述第一分区向量与所述第二分区向量间的向量距离作为第一相似度值。
35、进一步地,在本技术实施例提供的上述冗余数据表监测方法中,所述确定所述目标同组向量集中的冗余数据表,包括:
36、确定源数据表的目标特征;
37、确定所述目标同组向量集中每一目标同组向量对应的预设数据表以及所述预设数据表的数据特征;
38、检测所述数据特征是否满足所述目标特征;
39、当所述数据特征满足所述目标特征时,确定所述数据特征对应的预设数据表为源数据表;
40、当所述数据特征未满足所述目标特征时,确定所述数据特征对应的预设数据表为冗余数据表。
41、本技术实施例第二方面还提供一种冗余数据表监测装置,所述冗余数据表监测装置包括:
42、信息确定模块,用于获取目标数据库中的预设数据表集,并确定所述预设数据表集中每一预设数据表对应的目标信息,得到目标信息集;
43、向量处理模块,用于对每一所述目标信息进行向量化处理,得到目标向量集;
44、分区处理模块,用于对所述目标向量集进行分区处理,得到多个分区向量集,并确定每一所述分区向量集的第一相似度阈值;
45、第一相似确定模块,用于在同一所述分区向量集中,确定第一分区向量与第二分区向量间的第一相似度值,并检测所述第一相似度值是否超过所述第一相似度阈值;
46、第一向量分组模块,用于当所述第一相似度值超过所述第一相似度阈值时,在同一所述分区向量集中将所述第一分区向量与所述第二分区向量划分为初始同组向量集;
47、第二相似确定模块,用于在不同所述分区向量集中,确定第一初始同组向量集与第二初始同组向量集间的第二相似度值以及第二相似度阈值,并检测所述第二相似度值是否超过所述第二相似度阈值;
48、第二向量分组模块,用于当所述第二相似度值超过所述第二相似度阈值时,将所述第一初始同组向量集与所述初始第二分组向量集划分为目标同组向量集;
49、冗余确定模块,用于确定所述目标同组向量集中的冗余数据表。
50、本技术实施例第三方面还提供一种计算机设备,所述计算机设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如上述任意一项所述的冗余数据表监测方法。
51、本技术实施例第四方面还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述的冗余数据表监测方法。
52、本技术实施例提供的上述冗余数据表监测方法、冗余数据表监测装置、计算机设备以及计算机可读存储介质,本技术实施例对目标向量集进行分区处理,得到多个分区向量集,并确定每一分区向量集的第一相似度阈值,通过分区、分阈值的相似度确定方式,可以减少计算的数据量,提高计算的速率,还可以避免不同的字段个数对表相似度的定义不同的问题,提升相似度计算的准确度,继而提高冗余数据表确定的准确性;此外,本技术实施例还在不同分区向量集中进行相似度计算,能够避免相同的数据表被分到不同的类别及分类边缘数据漏分类的问题,提高冗余数据表确定的准确性。本技术可应用于智慧政务、智慧交通等智慧城市的各个功能模块中,比如智慧政务的冗余数据表监测模块等,能够促进智慧城市的快速发展。
- 还没有人留言评论。精彩留言会获得点赞!