一种面向社交媒体的事实核查方法及系统
本发明涉及网页核查,尤其涉及一种面向社交媒体的事实核查方法及系统。
背景技术:
1、自万维网诞生以来,互联网一直在不断高速发展,为世界带来日新月异的变化,将人类飞速带入了信息时代。无疑互联网拉进了世界的距离,人与人之间的交流真正实现了天涯若比邻。但是其所造成的影响却需要辩证看待,互联网在促进正面信息传播的同时,谣言与恶意信息也在以前所未有的速度、深度、广度在传播着。如今互联网上每天都生产着海量的信息,尤其是在社交媒体领域中,网络直接联系着每个具体的人,这些人既是信息的接收者,又是信息的生产者,可以说社交媒体上的信息传播有着爆发性快,对现实世界直接影响大的特点。
2、虽然一些明显比较离谱的,罔顾事实的内容很容易识别为错误消息,但某些陈述性的事实表达内容却不是那么容易去辨别真伪。这时就需要我们通过一些辅助手段,比如在搜索引擎中搜索相关词条,人为根据搜索结果进行判断是否准确。但面对社交媒体中海量的信息,人工核查往往有心无力,耗费大量资源。
技术实现思路
1、鉴于此,本发明的实施例提供了一种面向社交媒体的事实核查方法,以消除或改善现有技术中存在的一个或更多个缺陷。
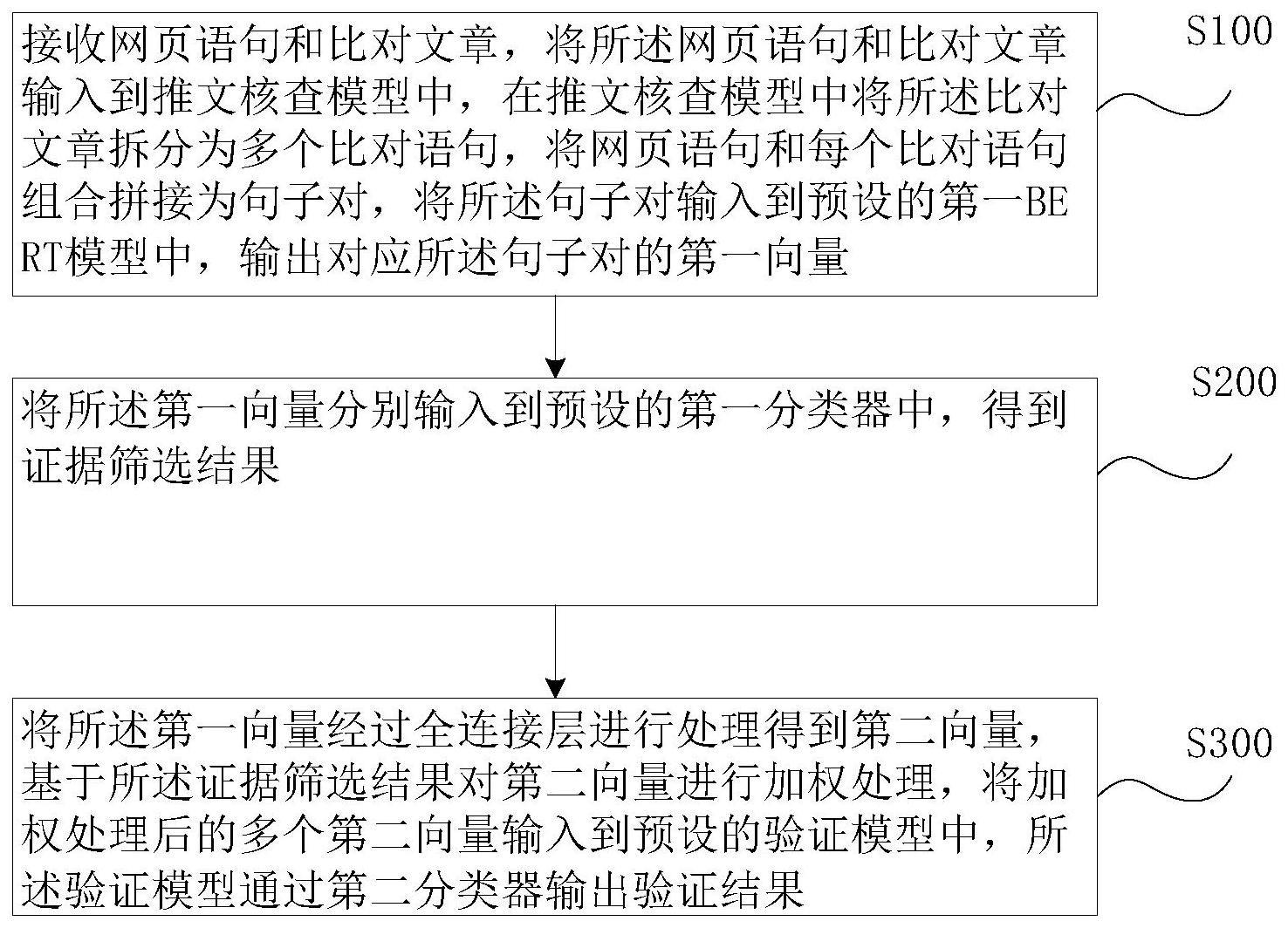
2、本发明的一个方面提供了一种面向社交媒体的事实核查方法,所述方法的步骤包括:
3、接收网页语句和比对文章,将所述网页语句和比对文章输入到推文核查模型中,在推文核查模型中将所述比对文章拆分为多个比对语句,将网页语句和每个比对语句组合拼接为句子对,将所述句子对输入到预设的第一bert模型中,输出对应所述句子对的第一向量;
4、将所述第一向量分别输入到预设的第一分类器中,得到证据筛选结果;
5、将所述第一向量经过全连接层进行处理得到第二向量,基于所述证据筛选结果对第二向量进行加权处理,将加权处理后的多个第二向量输入到预设的验证模型中,所述验证模型通过第二分类器输出验证结果。
6、采用上述方案,本方案中输出的验证结果包括网页语句真实、虚假或不能判断三种,本方案通过一个比对文章即可对网页语句的真实性进行验证,不需要人为进行处理,且本方案利用验证模型进行验证,在节约大量人力资源的前提下提高了验证精确度;另一方面,本方案通过将多个所述第一向量分别输入到预设的第一分类器,用于确定每个比对语句作为网络语句的证据筛选结果时的权重,能够基于证据筛选结果对第二向量序列进行加权处理,提高验证模型的输入数据的精准度,进而提高所述验证结果的精准度。
7、在本发明的一些实施方式中,所述验证模型包括双向长短期记忆网络和第二分类器,在将筛选后的多个第二向量输入到预设的验证模型中,所述验证模型通过第二分类器输出验证结果的步骤中,所述第二向量输入到所述双向长短期记忆网络进行处理,再输入到第二分类器中。
8、在本发明的一些实施方式中,在推文核查模型中将所述比对文章拆分为多个比对语句的步骤之前,所述方法的步骤包括,将所述网页语句输入到预设的推文筛选模型中,基于所述推文筛选模型输出的预分类结果确定所述网页语句是否需要核查。
9、在本发明的一些实施方式中,所述推文筛选模型包括第二bert模型和深度金字塔卷积神经网络,所述网页语句顺序经过第二bert模型和深度金字塔卷积神经网络进行处理,由深度金字塔卷积神经网络输出所述网页语句是否需要核查的结果。
10、在本发明的一些实施方式中,所述推文核查模型包括第一bert模型、第一分类器、全连接层和验证模型,所述方法的步骤包括对推文核查模型进行训练,所述对推文核查模型进行训练的步骤包括,获取训练数据集,基于训练数据集中的数据和证据筛选结果计算第一损失函数,基于训练数据集中的数据和所述第二分类器输出验证结果计算第二损失函数,基于第一损失函数和第二损失函数计算总损失函数,基于总损失函数对推文核查模型进行训练。
11、在本发明的一些实施方式中,在基于第一损失函数和第二损失函数计算总损失函数的步骤中,基于如下公式计算总损失函数值:
12、loss=(losse/n+lossc)/2;
13、其中,loss表示总损失函数值,losse表示第一损失函数值,lossc表示第二损失函数值,n表示所述比对文章拆分出的比对语句的数量。
14、本发明的第二方面还提供一种面向社交媒体的事实核查系统,所述系统包括:
15、向量转化模块,用于接收网页语句和比对文章,将所述网页语句和比对文章输入到推文核查模型中,在推文核查模型中将所述比对文章拆分为多个比对语句,将网页语句和每个比对语句组合拼接为句子对,将所述句子对输入到预设的第一bert模型中,输出对应所述句子对的第一向量;
16、证据筛选模块,用于将所述第一向量分别输入到预设的第一分类器中,得到证据筛选结果;
17、结果验证模块,用于将所述第一向量经过全连接层进行处理得到第二向量,基于所述证据筛选结果对第二向量进行加权处理,将加权处理后的多个第二向量输入到预设的验证模型中,所述验证模型通过第二分类器输出验证结果。
18、在本发明的一些实施方式中,所述验证模型包括双向长短期记忆网络和第二分类器,在将筛选后的多个第二向量输入到预设的验证模型中,所述验证模型通过第二分类器输出验证结果的步骤中,所述第二向量输入到所述双向长短期记忆网络进行处理,再输入到第二分类器中。
19、在本发明的一些实施方式中,在推文核查模型中将所述比对文章拆分为多个比对语句的步骤之前,所述系统还包括推文筛选模块,用于将所述网页语句输入到预设的推文筛选模型中,基于所述推文筛选模型输出的预分类结果确定所述网页语句是否需要核查。
20、在本发明的一些实施方式中,所述推文筛选模型包括第二bert模型和深度金字塔卷积神经网络,所述网页语句顺序经过第二bert模型和深度金字塔卷积神经网络进行处理,由深度金字塔卷积神经网络输出所述网页语句是否需要核查的结果。
21、在本发明的一些实施方式中,所述推文核查模型包括第一bert模型、第一分类器、全连接层和验证模型,所述系统包括对推文核查模型进行训练的步骤,所述对推文核查模型进行训练的步骤包括,获取训练数据集,基于训练数据集中的数据和证据筛选结果计算第一损失函数,基于训练数据集中的数据和所述第二分类器输出验证结果计算第二损失函数,基于第一损失函数和第二损失函数计算总损失函数,基于总损失函数对推文核查模型进行训练。
22、在本发明的一些实施方式中,在基于第一损失函数和第二损失函数计算总损失函数的步骤中,基于如下公式计算总损失函数值:
23、loss=(losse/n+lossc)/2;
24、其中,loss表示总损失函数值,losse表示第一损失函数值,lossc表示第二损失函数值,n表示所述比对文章拆分出的比对语句的数量。
25、本发明的第三方面还提供一种面向社交媒体的事实核查装置,该装置包括计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该装置实现如前所述方法所实现的步骤。
26、本发明的第四方面还提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时以实现前述面向社交媒体的事实核查方法所实现的步骤。
27、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出并获得。
28、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
- 还没有人留言评论。精彩留言会获得点赞!