一种翻译模型训练方法、语音翻译方法及相关设备与流程
本发明涉及语音翻译,尤其涉及一种翻译模型训练方法、语音翻译方法及相关设备。
背景技术:
1、大数据和大算力使得基于深度学习的应用比如语音识别、机器翻译等效果取得显著的提升。比如中英的语音识别准确率达到95%以上,中英文机器翻译的准确率达到90%以上。而基于上述技术的一些应用也逐渐走进人们的生活,比如语音助手、网页翻译、文档翻译等。近些年,短视频逐渐取代文字和图片,成为互联网上最受欢迎的媒介,跨语言的需求在视频领域依然存在,因此,语音翻译的需求也越来越迫切。
2、目前的语音翻译系统多为基于多系统级联的语音翻译系统,具体的,语音翻译系统包括依次级联的语音识别模型、标点模型和翻译模型,基于多系统级联的语音翻译系统实现语音翻译的过程为,先将完整的音频切分成固定时长或者拥有完整语义的音频片段,然后基于语音识别模型对音频片段进行语音识别,由于语音识别结果的标点效果不好,因此,接下来基于标点模型对语音识别结果重打标点,最后基于翻译模型对重打标点后的识别结果进行翻译。
3、语音翻译的每个环节都可能出现问题,比如,语音识别模型可能存在识别错误,语音翻译系统中的标点模型可能存在标点错误,进而,语音翻译系统中的翻译模型的输入可能为存在若干问题的文本,再加之翻译模型本身存在直译、错译等问题,最终导致语音翻译效果较差。
技术实现思路
1、有鉴于此,本发明提供了一种翻译模型训练方法、语音翻译方法及相关设备,用以解决现有的语音翻译系统的语音翻译效果较差的问题,其技术方案如下:
2、一种翻译模型训练方法,包括:
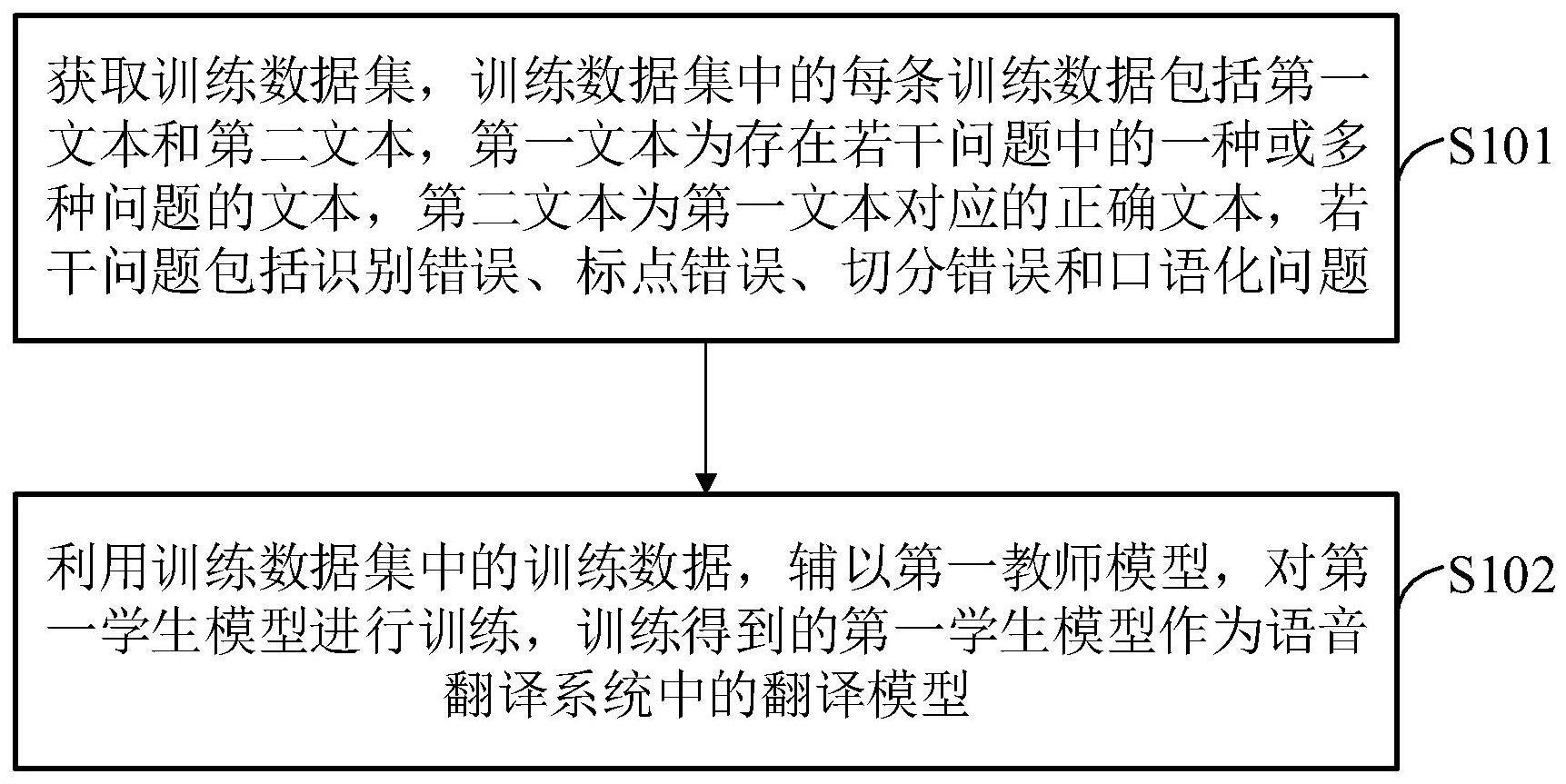
3、获取训练数据集,其中,所述训练数据集包括若干条训练数据,每条训练数据包括第一文本和第二文本,所述第一文本为存在若干问题中的一种或多种问题的文本,所述第二文本为所述第一文本对应的正确文本,所述若干问题包括识别错误、标点错误、切分错误和口语化问题;
4、利用所述训练数据集中的训练数据,辅以第一教师模型,对第一学生模型进行训练,训练得到的第一学生模型作为语音翻译系统中的翻译模型,其中,第一学生模型的训练目标包括:使第一学生模型对训练数据中的第一文本进行翻译得到的翻译结果趋近于所述第一教师模型对同一训练数据中的第二文本进行翻译得到的翻译结果,所述第一教师模型为训练好的文本翻译模型,初始的第一学生模型的结构和参数与所述第一教师模型相同。
5、可选的,所述训练数据集中的每条训练数据还包括该条训练数据中第二文本的标准翻译结果;
6、第一学生模型的训练目标还包括:使第一学生模型对训练数据中的第一文本进行翻译得到的翻译结果趋近于该训练数据中的标准翻译结果。
7、可选的,所述利用所述训练数据集中的训练数据,辅以第一教师模型,对第一学生模型进行训练,包括:
8、从所述训练数据集中获取训练数据;
9、将获取的训练数据中的第一文本输入第一学生模型,以获得第一学生模型的预测概率分布,作为第一预测概率分布;
10、将获取的训练数据中的第二文本输入第二教师模型,以获得所述第二教师模型的预测概率分布,作为第二预测概率分布;
11、根据所述第一预测概率分布和所述第二预测概率分布确定第一预测损失,并根据所述第一预测概率分布和获取的训练数据中的标准翻译结果确定第二预测损失;
12、根据所述第一预测损失和所述第二预测损失,对第一学生模型进行参数更新。
13、可选的,所述训练数据集中包括识别容错训练数据,所述识别容错训练数据为包含的第一文本存在识别错误的训练数据;
14、所述识别容错训练数据的构造过程包括:
15、获取训练音频和所述训练音频对应的识别标注文本;
16、基于语音识别模型对所述训练音频进行语音识别,得到识别文本;
17、若所述识别文本存在识别错误,则基于文本翻译模型对所述识别标注文本进行翻译,得到所述识别标注文本的翻译结果;
18、将存在识别错误的识别文本、所述识别标注文本以及所述识别标注文本的翻译结果组成识别容错训练数据。
19、可选的,所述训练数据集中包括标点容错训练数据,所述标点容错训练数据为包含的第一文本存在标点错误的训练数据;
20、所述标点容错训练数据的构造过程包括:
21、获取第一双语平行语料,所述第一双语平行语料包括第一源语言文本和第一目标语言文本;
22、将所述第一源语言文本的标点去除,并基于标点模型为去除标点后的源语言文本重打标点;
23、若重打标点后的源语言文本存在标点错误,则将存在标点错误的源语言文本、所述第一源语言文本以及所述第一目标语言文本组成标点容错训练数据。
24、可选的,所述训练数据集中包括切分容错训练数据,所述切分容错训练数据为包含的第一文本存在切分错误的训练数据;
25、所述切分容错训练数据的构造过程包括:
26、获取第二双语平行语料,所述第二双语平行语料包括第二源语言文本和第二目标语言文本;
27、对所述第二源语言文本随机选取切分位置,并在选取的切分位置添加分割符,得到存在切分错误的源语言文本;
28、由所述存在切分错误的源语言文本、所述第二源语言文本和所述第二目标语言文本组成切分容错训练数据。
29、可选的,所述训练数据集中包括口语化容错训练数据,所述口语化容错训练数据为包含的第一文本存在口语化问题的训练数据;
30、所述口语化容错训练数据的构造过程包括:
31、获取第三双语平行语料,所述第三双语平行语料包括第三源语言文本和第三目标语言文本;
32、将所述第三源语言文本处理成口语化的源语言文本;
33、将所述口语化的源语言文本、所述第三源语言文本和所述第三目标语言文本组成口语化容错训练数据。
34、可选的,所述将所述第三源语言文本处理成口语化的源语言文本,包括:
35、基于预先训练得到的口语化生成模型,将所述第三源语言文本处理成口语化的源语言文本;
36、其中,所述口语化生成模型采用若干训练规范文本和所述若干训练规范文本分别对应的真实口语化文本训练得到,所述口语化生成模型的训练目标包括:使口语化生成模型对训练规范文本进行处理输出的口语化文本与该训练规范文本对应的真实口语化文本趋于一致。
37、可选的,所述口语化生成模型采用对抗生成模型中的生成器;
38、所述口语化生成模型的训练目标还包括:使所述对抗生成模型中的判别器无法判别作为口语化生成模型的生成器对训练规范文本进行处理输出的口语化文本为生成的口语化文本还是真实的口语化文本。
39、可选的,所述口语化生成模型与第二学生模型联合训练;
40、所述口语化生成模型的训练目标还包括:使第二学生模型对口语化生成模型输出的口语化文本进行处理得到的特征向量趋近于目标特征向量,其中,所述目标特征向量为第二教师模型对口语化生成模型输出的口语化文本对应的训练规范文本进行处理得到的特征向量,所述第二教师模型为训练好的文本翻译模型,初始的第二学生模型的结构和参数与所述第二教师模型相同。
41、一种语音翻译方法,包括:
42、获取待翻译音频;
43、将所述待翻译音频切分为音频段;
44、基于语音识别模型对所述音频段进行语音识别,得到识别结果;
45、基于标点模型对所述识别结果重打标点,得到重打标点后的识别结果;
46、基于上述任一项所述的翻译模型训练方法训练得到的翻译模型,对所述重打标点后的识别结果进行翻译。
47、一种翻译模型训练装置,包括:训练数据集获取模块和翻译模型训练模块;
48、所述训练数据集获取模块,用于获取训练数据集,其中,所述训练数据集包括若干条训练数据,每条训练数据包括第一文本和第二文本,所述第一文本为存在若干问题中的一种或多种问题的文本,所述第二文本为所述第一文本对应的正确文本,所述若干问题包括识别错误、标点错误、切分错误和口语化问题;
49、所述翻译模型训练模块,用于利用所述训练数据集中的训练数据,辅以第一教师模型,对第一学生模型进行训练,训练得到的第一学生模型作为语音翻译系统中的翻译模型,其中,第一学生模型的训练目标包括:使第一学生模型对训练数据中的第一文本进行翻译得到的翻译结果趋近于所述第一教师模型对同一训练数据中的第二文本进行翻译得到的翻译结果,所述第一教师模型为训练好的文本翻译模型,初始的第一学生模型的结构和参数与所述第一教师模型相同。
50、一种处理设备,包括:存储器和处理器;
51、所述存储器,用于存储程序;
52、所述处理器,用于执行所述程序,实现上述任一项所述的翻译模型训练方法的各个步骤。
53、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述任一项所述的翻译模型训练方法的各个步骤。
54、本发明提供的翻译模型训练方法,首先获取训练数据集,然后利用训练数据集中的训练数据,辅以第一教师模型,对第一学生模型进行训练,训练得到的第一学生模型作为语音翻译系统中的翻译模型。由于第一学生模型的训练数据包括第一文本和第二文本,即存在识别错误、标点错误、切分错误、口语化问题中的一种或多种问题的文本和对应的正确文本,并且,在训练时,以使第一学生模型对训练数据中的第一文本进行翻译得到的翻译结果趋近于第一教师模型对同一训练数据中的第二文本进行翻译得到的翻译结果为训练目标(即,以使第一学生模型对存在问题的文本进行翻译得到的翻译结果趋近于第一教师模型对正确文本进行翻译得到的翻译结果为训练目标),因此,训练得到的第一学生模型为具有较好翻译效果且具有容错能力(或者说,对错误具有鲁棒性)的翻译模型,进而,将其应用于语音翻译系统进行翻译时,能够获得较好的语音翻译效果。在本发明提供的翻译模型训练方法的基础上,本发明还提供了一种语音翻译方法,由于该语音翻译方法中使用的翻译模型为采用本发明提供的翻译模型训练方法训练得到的具有较好翻译效果且具有容错能力(或者说,对错误具有鲁棒性)的翻译模型,因此,采用该语音翻译方法对待翻译语音进行翻译,可获得较好的语音翻译效果。
- 还没有人留言评论。精彩留言会获得点赞!