用于分布式存储系统IO实时聚合的方法及设备与流程
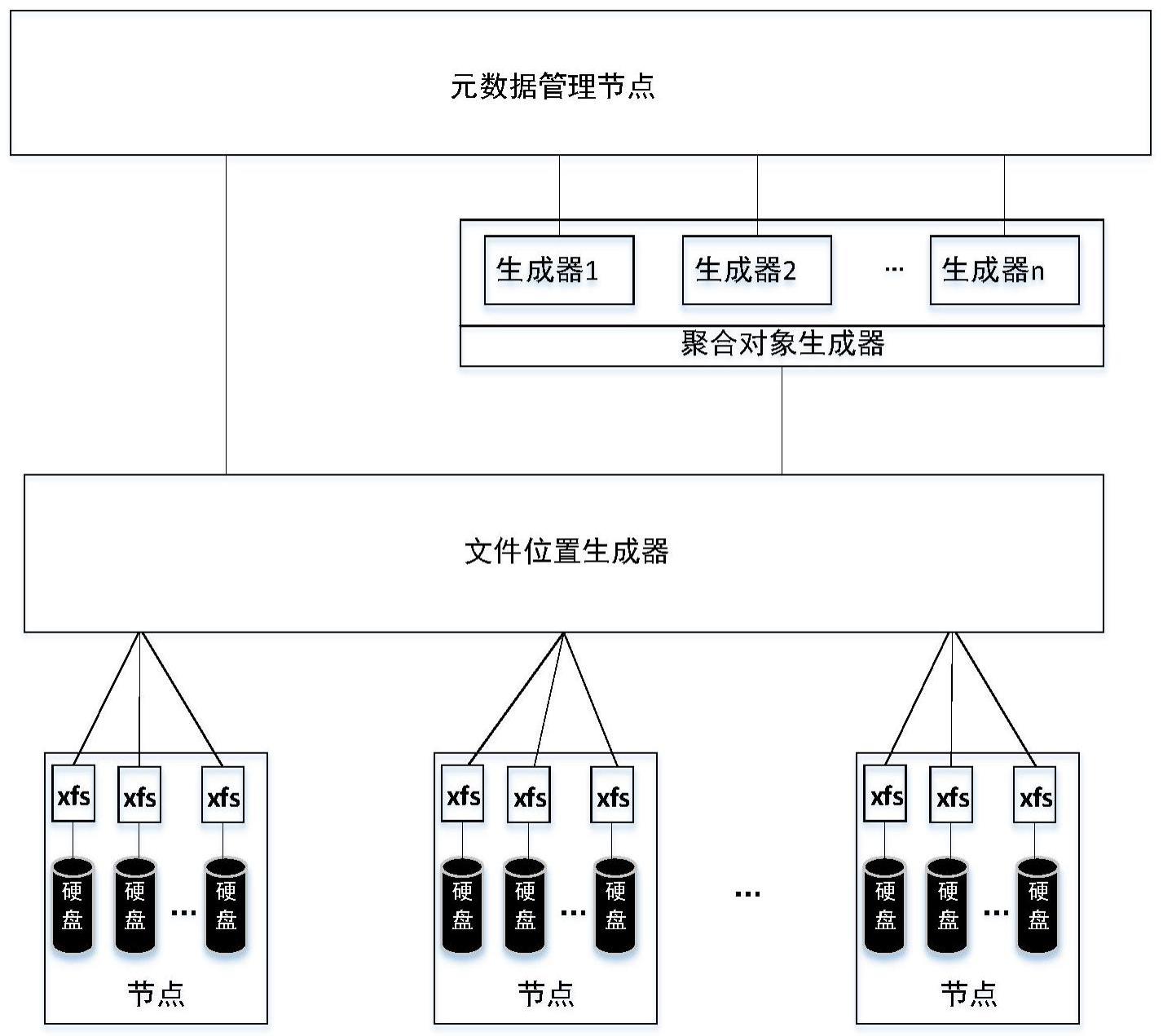
本发明涉及一种用于分布式存储系统io实时聚合的方法及设备。
背景技术:
1、在分布式系统环境中,数据的写入请求来自不同节点,为实现io实时聚合,分布式锁是比较容易想到的一种方案,但是这种传统实现方式不但会大幅度降低写入性能而且还增加复杂度。
技术实现思路
1、本发明的目的在于提供一种用于分布式存储系统io实时聚合的方法及设备。
2、为解决上述问题,本发明提供一种用于分布式存储系统io实时聚合的方法,包括:
3、步骤s1,获取申请写入文件的完整写入io请求,所述完整写入io请求包括:文件路径、偏移量、申请写入文件大小,其中,所述偏移量为0;
4、步骤s2,基于所述完整写入io请求,在元数据管理节点查询申请写入文件是否存在;
5、步骤s3,若文件不存在,则获取申请写入文件对应的新聚合对象的写入名及写入偏移量;
6、步骤s4,若文件存在,获取申请写入文件的剩余大小部分对应的新聚合对象的写入名及写入偏移量,其中,申请写入文件的剩余大小部分=申请写入文件大小-原文件的大小;
7、步骤s5,通过位置生成器基于步骤s3获取到的新聚合对象的写入名,产生实际写入本地文件系统路径;基于实际写入本地文件系统路径、文件大小和步骤s3获取到的新聚合对象的写入偏移量,尝试将申请写入文件写入对应的存储节点的硬盘;或,通过位置生成器基于原聚合对象和步骤s4获取到的新聚合对象的写入名,分别产生对应的实际写入本地文件系统路径;基于实际写入本地文件系统路径、申请写入文件大小和步骤s4获取到的新聚合对象的写入偏移量,尝试将申请写入文件写入对应的存储节点的硬盘;
8、步骤s6,若申请写入文件写入成功,则将文件id、申请写入文件大小、新聚合对象的写入名和新聚合对象的写入偏移量记录到元数据管理节点。
9、进一步的,在上述方法中,步骤s3,若文件不存在,则获取申请写入文件对应的新聚合对象的写入名及写入偏移量,包括:
10、步骤s31,若文件不存在,则聚合对象生成器节点发送申请生成申请写入文件对应的新聚合对象的请求,并从所述聚合对象生成器节点获取基于生成申请写入文件对应的新聚合对象的请求,反馈的申请写入文件对应的新聚合对象的写入名及写入偏移量,其中,所述生成申请写入文件对应的新聚合对象的请求,包括:申请写入文件id和文件大小。
11、进一步的,在上述方法中,步骤s31,从所述聚合对象生成器节点,获取基于生成申请写入文件对应的新聚合对象的请求,反馈的申请写入文件对应的新聚合对象的写入名及写入偏移量,包括:
12、步骤s311,聚合对象生成器节点从内存文件系统中加载聚合对象集合其中,聚合对象集合中的每个聚合对象的属性包括:写入名、已分配大小和引用计数;
13、步骤s312,聚合对象生成器节点读取配置文件信息,所述配置文件信息包括:预设的聚合对象大小的上限值、聚合对象集合的预设规模n、本地后端ip地址及所述本地后端ip地址对应的网卡mac地址和主机名host name;
14、步骤s313,若聚合对象集合中的聚合对象总数m小于预设规模n,则在所述聚合对象集合继续创建n-m个聚合对象,并为每个新创建的聚合对象配置写入名、已分配大小和引用计数,其中,每个新创建的聚合对象的写入名=“hash(mac+hostname)”+“128位整数随机值”,已分配大小的初始值设置为零,引用计数的初始值设置为零;
15、步骤s314,从聚合对象集合中选择已分配大小最小的聚合对象,
16、步骤s315,若选择的聚合对象的已分配大小+申请写入文件大小<=设定聚合对象大小值,则选定该聚合对象;
17、步骤s316,更新选定的聚合对象已分配大小及引用计数,其中,已分配大小=选定的聚合对象原来的已分配大小+申请写入大小,引用计数=选定的聚合对象原来的引用计数+1;
18、步骤s317,将选定的聚合对象原来的已分配大小作为选定的聚合对象的写入偏移量,聚合对象生成器节点向生成申请写入文件对应的新聚合对象的请求,反馈申请写入文件对应的选定的聚合对象的写入偏移量和写入名;
19、步骤s318,若选择的聚合对象的已分配大小+申请写入文件大小>设定聚合对象大小值,从聚合对象集合中移除选择的聚合对象,并将移除的聚合对象的写入名、已分配大小和引用计数,记录至元数据管理节点后,重新转到步骤s313执行。
20、进一步的,在上述方法中,步骤s4,若文件存在,获取申请写入文件的剩余大小部分对应的新聚合对象的写入名及写入偏移量,包括:
21、步骤s41,若文件存在,则比较申请写入文件的大小和原文件的大小,
22、步骤s42,若申请写入文件的大小<=原文件的大小,则使用原文件的聚合对象;
23、步骤s43,若申请写入文件的大小>原文件的大小,则申请写入文件的小于等于原文件大小部分使用原文件的聚合对象;申请写入文件的剩余大小部分=申请写入文件的大小-原文件的大小;通过向所述聚合对象生成器节点发送申请生成申请写入文件的剩余大小部分对应的新聚合对象的请求,其中,所述申请生成申请写入文件的剩余大小部分对应的新聚合对象的请求,包括:申请写入文件id,申请写入文件的剩余大小部分;并从聚合对象生成器节点获取,基于所述申请生成申请写入文件的剩余大小部分对应的新聚合对象的请求,反馈申请写入文件的剩余大小部分对应的新聚合对象的写入名及写入偏移量。
24、进一步的,在上述方法中,步骤s43,从聚合对象生成器节点获取,基于所述生成申请写入文件的剩余大小部分对应的新聚合对象的请求,反馈的申请写入文件的剩余大小部分对应的新聚合对象的写入名及写入偏移量,包括:
25、步骤s431,聚合对象生成器节点从内存文件系统中加载聚合对象集合其中,聚合对象集合中的每个聚合对象的属性包括:写入名、已分配大小和引用计数;
26、步骤s432,聚合对象生成器节点读取配置文件信息,所述配置文件信息包括:预设的聚合对象大小的上限值、聚合对象集合的预设规模n、本地后端ip地址及所述本地后端ip地址对应的网卡mac地址和主机名host name;
27、步骤s433,若聚合对象集合中的聚合对象总数m小于预设规模n,则在所述聚合对象集合继续创建n-m个聚合对象,并为每个新创建的聚合对象配置写入名、已分配大小和引用计数,其中,每个新创建的聚合对象的写入名=“hash(mac+hostname)”+“128位整数随机值”,已分配大小的初始值设置为零,引用计数的初始值设置为零;
28、步骤s434,从聚合对象集合中选择已分配大小最小的聚合对象,
29、步骤s435,若选择的聚合对象的已分配大小+申请写入文件的剩余大小<=设定聚合对象大小值,则选定该聚合对象;
30、步骤s436,更新选定的聚合对象已分配大小及引用计数,其中,已分配大小=选定的聚合对象原来的已分配大小+申请写入文件的剩余大小,引用计数=选定的聚合对象原来的引用计数+1;
31、步骤s437,将选定的聚合对象原来的已分配大小作为选定的聚合对象的写入偏移量,聚合对象生成器节点向生成申请写入文件对应的新聚合对象的请求,反馈申请写入文件对应的选定的聚合对象的写入偏移量和写入名;
32、骤s438,若选择的聚合对象的已分配大小+申请写入文件的剩余大小>设定聚合对象大小值,从聚合对象集合中移除选择的聚合对象,并将移除的聚合对象的写入名、已分配大小和引用计数,记录至元数据管理节点后,重新转到步骤s433执行。
33、进一步的,在上述方法中,步骤s6,尝试将申请写入文件写入对应的存储节点的硬盘之后,还包括:
34、步骤s7,若申请写入文件写入失败或文件删除,则向所述聚合对象生成器节点发送减少引用计数的请求。
35、进一步的,在上述方法中,步骤s7,向所述聚合对象生成器节点发送减少引用计数的请求,包括:
36、步骤s71,根据减少聚合对象的引用计数的请求中的聚合对象的写入名名查出该聚合对象名来自的聚合对象生成器节点的ip地址,基于所述聚合对象生成器节点的ip地址,向对应的聚合对象生成器节点发送减少引用计数请求,所述减少聚合对象的引用计数的请求包括:减少聚合对象的写入名;
37、步骤s72,基于所述生成器节点发送减少引用计数请求,在元数据管理节点查找减少聚合对象的写入名,若元数据管理节点存在减少聚合对象的写入名,则在元数据管理节点中将减少聚合对象的引用计数减1;否则,在聚合对象集合中查找减少聚合对象的写入名,若聚合对象集合存在减少聚合对象的写入名,则将减少聚合对象的引用计数减1;若所述聚合对象集合中不存在减少聚合对象的写入名,则返回失败;
38、步骤s73,若元数据管理节点或聚合对象集合中的某个聚合对象的引用计数为零,则将该引用计数为零的聚合对象从元数据管理节点或聚合对象集合中删除。
39、进一步的,在上述方法中,步骤s6,将文件id、申请写入文件大小、新聚合对象的写入名和新聚合对象的写入偏移量记录到元数据管理节点之后,还包括:
40、步骤s81,获取读请求,基于所述读请求从元数据管理节点中获取文件id、聚合对象的写入名的写入名和写入偏移量、文件大小;
41、步骤s82,位置生成器根据聚合对象的写入名计算出其在本地文件系统路径,再根据本地文件系统路径、聚合对象的写入偏移量及文件大小从本地文件系统读取数据。
42、根据本发明的另一面,提供一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现权利要求1至8中任一项所述的方法。
43、根据本发明的另一面,提供一种用于在网络设备端信息处理的设备,该设备包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发该设备执行权利要求1至8中任一项所述的方法。
44、与现有技术相比,本发明方法中的io实时聚合可以用在完整写入io场景,完整写入指的是从零偏移量开始,写入大小等于该文件实际大小的写入。本发明方法中的聚合对象拥有{写入名+分配大小+引用计数}等属性,且最终聚合对象文件大小不超过设定大小。
45、本发明包括:使用聚合对象生成器节点装置生成聚合对象,io写入新生成的聚合对象中,后续所有对该io的读取都将访问聚合对象。聚合对象拥有{写入名+分配大小+引用计数}等属性,且最终聚合对象文件大小不超过设定大小。io写入前先查询元数据管理节点,对于新文件写入,发送生成聚合对象请求到聚合对象生成器节点获取聚合对象的写入名及写入偏移量;对于已存在文件的覆盖写io,写入请求不超过原大小部分,使用原聚合对象写入;对于超过部分发送剩余大小请求到聚合对象生成器节点以获取新聚合对象。本发明提供的io实时聚合方法能在分布式存储系统中不用分布式锁高效工作,并极大降低最终写入硬盘的文件总数,实践中超100亿文件写入性能不衰减。
46、本发明中,元数据和数据分离,元数据管理节点负责整个系统元数据的管理,数据部分采用哈希方式写入本地文件系统。现有方案中,当文件数量达到一定规模时,随着文件数量的继续增多,本地文件系统的写入速度会逐渐降低,在海量文件数据写入场景下,系统写入性能将受到很大影响,严重影响用户使用体验。本发明提供的分布式存储系统io实时聚合方法能解决海量文件数据写入性能下降的问题,可以做到超百亿文件写入,性能不下降。
47、本发明方法提供的文件聚合生成器不使用分布式锁,各生成器之间完全对等,在保证性能的同时极大降低复杂度,为io实时聚合提供坚实的基础保障。
- 还没有人留言评论。精彩留言会获得点赞!