一种基于深度强化学习的筹划方案动态训练生成方法与流程
本发明属于作战筹划领域,具体涉及一种基于深度强化学习的筹划方案动态训练生成方法。
背景技术:
1、作战筹划是对战争的构想和设计,是为达成某种作战目标而需要采取的手段。不同于作战任务规划需要制定具体的计划方案以及根据反馈进行实时调整,作战筹划面向可能的敌情信息和作战意图,对作战兵力编成和行动任务进行战前的静态筹划部署从而形成大的作战构想,属于战前的静态方案制定阶段,不进行作战过程中的动态调整。由于筹划方案制定涉及的知识领域多为非线性且难以工程化表达,很难用传统的优化方法求解,指挥员多根据对目标意图的理解和自身经验,通过近似量化估计的方式制定筹划方案,再根据推演效果不断改进筹划方案。
2、但在作战筹划领域,仍然缺失智能化与工程化的方法,现有作战任务规划技术没有涉及将战前静态的作战筹划问题制定成动态训练和生成问题,缺乏针对不同敌情信息和兵力资源情况下进行模型能力训练提升的方法以及模型的动态训练和更新机制,同时奖励设计没有考虑时序情况下单个任务与总体团队之间的权重配合。如何将静态的作战筹划方案制定转换为可动态训练与生成的问题、如何根据变化的敌情在战前静态阶段快速有效制定筹划方案,以及如何考虑时序情况下的单个任务与总体团队的协同配合,仍是一个亟待解决的问题。
技术实现思路
1、本发明的目的在于针对解决背景技术中提出的问题,提出一种基于深度强化学习的筹划方案动态训练生成方法。
2、为实现上述目的,本发明所采取的技术方案为:
3、本发明提出的一种基于深度强化学习的筹划方案动态训练生成方法,应用于基于深度强化学习的筹划方案动态训练生成系统,基于深度强化学习的筹划方案动态训练生成方法包括:
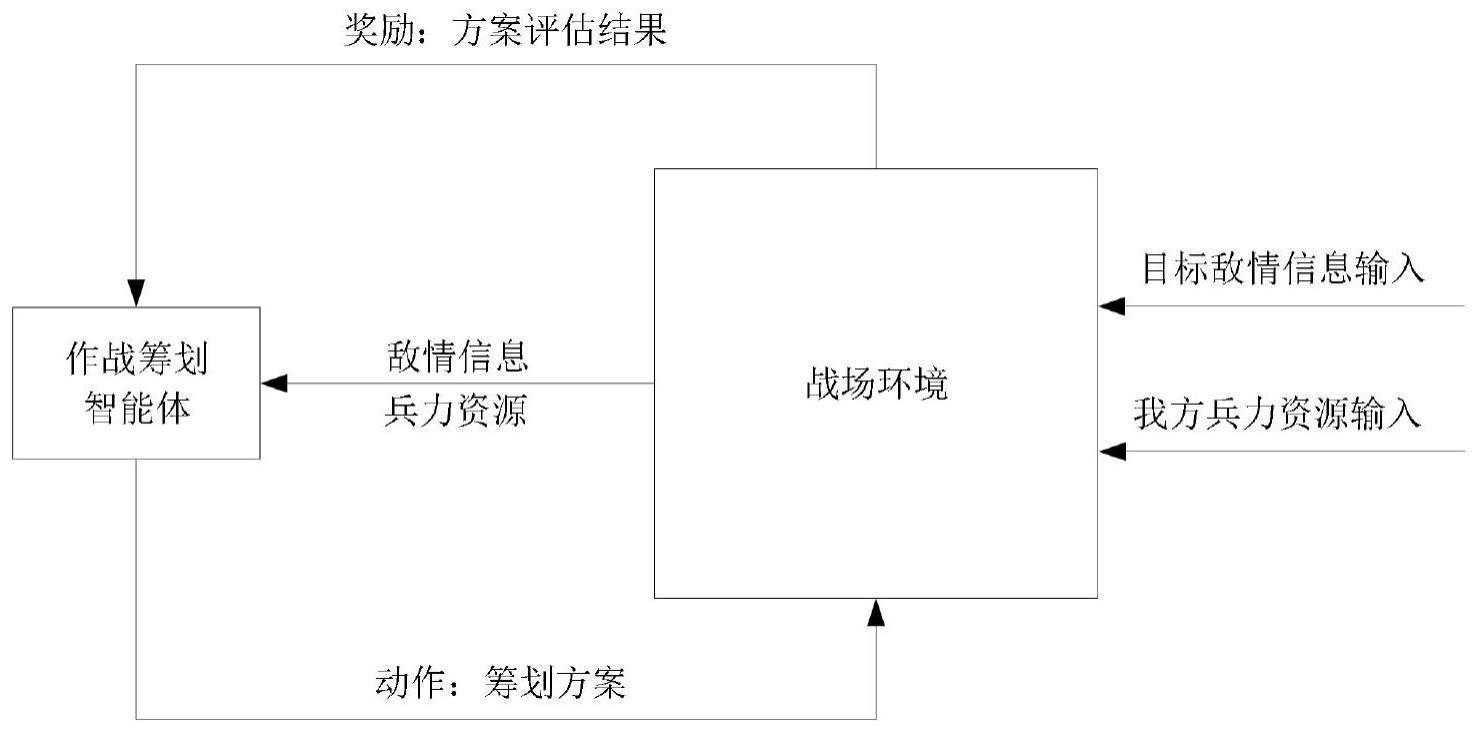
4、构建基于神经网络的作战筹划智能体模型。
5、利用目标敌情信息、我方兵力资源和推演系统得到的作战奖励训练作战筹划智能体模型直至收敛。
6、将目标敌情信息和我方兵力资源输入至训练好的作战筹划智能体模型,作战筹划智能体模型输出筹划方案。
7、所述神经网络结构设计如下:
8、将目标敌情信息和我方兵力资源中的兵力单元、装备类型和当前状态采用embedding方法进行映射形成特征向量后,与目标敌情信息和我方兵力资源中的各位置高度进行归一化处理,然后连接并输入两层全连接层。
9、然后前25%的特征向量输入进最大池化层,提取各兵力单元、各装备类型、各当前状态和各位置高度的最大特征后,与后75%的特征向量合并输出到lstm网络模型进行映射形成特性向量a。
10、特性向量a经过一层全连接输出,与作战任务类型embedding方法映射后的特征向量进行交叉,输出筹划方案中的作战任务类型。
11、对输出的作战任务类型进行embedding方法映射,与各兵力单元embedding方法映射后的特征向量进行交叉后,再与特性向量a经过一层全连接后的输出交叉,输出筹划方案中的执行任务的兵力单元。
12、特性向量a经过一层全连接输出,输出筹划方案中的延迟开始时间。
13、特性向量a经过一层全连接输出,输出筹划方案中的位置信息。
14、优选地,作战筹划智能体输出的筹划方案用action表示:
15、
16、其中,actioni()表示第i类型动作,参数unit表示我方兵力资源中执行任务的兵力单元,参数delaytime表示延迟开始时间,参数offset表示区域或位置点,参数mode表示作战任务类型。
17、优选地,推演系统得到的作战奖励设计如下:
18、作战奖励通过事件触发,设计各事件的奖励权重数值。
19、奖励事件的零和,我方被损毁获得负的奖励,击毁敌方获得正的奖励。
20、总体奖励与单独奖励的平衡,用一个团队系数表示对整体筹划奖励的重视程度,设置系数为τ,则某个兵力单元修正后的rewardi计算如下:
21、
22、
23、0≤τ≤1
24、其中,ri表示第i个兵力单元的奖励,表示所有兵力单元自身的平均奖励,且当τ=0时,修正后的奖励即各兵力单元自身的奖励,当τ=1时,修正后的奖励即为所有兵力单元自身的平均奖励,n表示训练的局数。
25、优选地,利用目标敌情信息、我方兵力资源和推演系统得到的作战奖励训练作战筹划智能体模型直至收敛,包括:
26、将目标敌情信息和我方兵力资源输入至作战筹划智能体模型,作战筹划智能体模型输出筹划方案。
27、推演系统根据输出的筹划方案推演得到作战奖励,并输入至作战筹划智能体模型中,作战筹划智能体模型进行更新。
28、不断重复,直至作战奖励收敛,则作战筹划智能体模型收敛,得到训练好的作战筹划智能体模型。
29、优选地,训练作战筹划智能体模型时,分别针对固定的我方兵力资源和目标敌情信息进行训练:场景设置为我方兵力资源不变、目标敌情信息不变,训练得到固定场景下的作战筹划智能体模型。
30、针对规定的我方兵力资源和随机的目标敌情信息进行训练:随机不同的目标敌情信息,训练得到适应不同目标敌情信息场景下的作战筹划智能体模型,设置目标敌情信息场景增加率为α,设置目标敌情信息场景的变化程度为:
31、sn+i=sn+αsn
32、其中,sn为总目标敌情信息场景数量,sn为当前训练局的目标敌情信息场景数量,sn+1为下一局的目标敌情信息场景数量,根据总训练局数设置α的范围为0.1-0.5。
33、针对随机的我方兵力资源和随机的目标敌情信息进行训练:随机不同的我方兵力资源情况,训练得到适应不同目标敌情信息和不同我方兵力资源场景下的作战筹划智能体模型,设置我方兵力资源场景增加率为β,设置我方兵力资源场景的变化程度为:
34、mn+1=mn+βmn
35、其中,mn为总我方兵力资源场景数量,mn为当前训练局的我方兵力资源场景数量,mn+1为下一局的我方兵力资源场景数量,根据总训练局数设置β的范围为0.1-0.5。
36、优选地,基于深度强化学习的筹划方案动态训练生成系统,包括:
37、任务编辑界面,实现对作战任务类型和参数的编辑配置。
38、场景录入界面,实现对目标敌情信息和我方兵力资源的录入。
39、模型训练界面,实现对算法的选择、超参的配置以及奖励的设置。
40、作战筹划界面,根据输入的目标敌情信息和我方兵力资源推理出最优的作战筹划方案。
41、与现有技术相比,本发明的有益效果为:
42、本方法通过对基于神经网络的作战筹划智能体模型进行训练,并将目标敌情信息和我方兵力资源输入至训练好的作战筹划智能体模型,生成筹划方案,并且整个训练过程在我方兵力资源和目标敌情信息都会变化的情况下,得到一个能够适应不同场景的具有泛化能力的作战筹划智能体模型,输出的筹划方案更加精准可靠,同时为了促进不同兵力单元的协同配合,考虑总体奖励和单独奖励的平衡,设置奖励事件的权重,并引入系数,使筹划方案的制定趋近于合作与平衡。
- 还没有人留言评论。精彩留言会获得点赞!