众包地图道路对象要素聚类方法、系统及存储介质与流程
本发明属于高精度地图,具体涉及一种众包地图道路对象要素聚类方法、系统及存储介质。
背景技术:
1、在自动驾驶技术的发展过程中,需要借助高精度地图进行定位和规划。高精度地图提供了比传统地图更加精确的道路级别和车道级别的导航信息,能更好的服务于自动驾驶车辆。而基于众包地图的方法收集大量的众包道路的最新数据是为自动驾驶提供与现实世界保持一致性最好的方式。
2、高精度地图的成图主要包括了车端数据采集和云端数据成图两个方面。云端建图系统主要利用汽车搭载的多传感器回传的数据作为众包源,通过地图学习方式实现地图的实时增量变化。其中聚类是高精度地图生产中地图学习中的一环,其主要目的是将同一类型的多个对象数据聚类成一簇,为地图学习的后续步骤提供有效的结果输出,能够保证众包地图的增量地图数据与地图供应商地图数据可以进行周期性的交互更新。
3、常见的聚类算法有很多,各自都有一定的优缺点。针对k-means算法来说,k值的选取不好把握,对于不是凸的数据集比较难收敛。如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。容易陷入局部最优,对噪音和异常点也非常敏感。
4、针对谱聚类算法来说,选择不同的相似矩阵构建方法会对结果有很大的影响,对参数的选择也比较敏感,其构建完成后还是需要基于k-means进行聚类,且仍具有上述问题。并且数据量较大时,构建相似性矩阵是非常耗费时间的,算法的算力不强。针对dbscan聚类算法来说,如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差。如果样本集较大时,聚类收敛时间较长。针对传统的均值漂移聚类算法,只采用距离作为聚类判断,无法综合考虑复杂的实际道路环境。并且,对于一些稀疏和密集不显著区分的数据,聚类效果也不好。
5、目前,均值漂移的聚类算法大多应用于图像类数据,比如,专利文献cn104751185b公开的基于均值漂移遗传聚类的sar图像变化检测方法,该方法的实现步骤为:(1)导入图像;(2)构造差异图像;(3)均值漂移滤波;(4)遗传模糊聚类;(5)分割差异图像;(6)输出结果。如专利文献cn105718942b公开的基于均值漂移和过采样的高光谱图像不平衡分类方法,该方法首先将高光谱图像的每一个像素点用特征向量表示,用主成分分析降维方法提取第一主成分高光谱图像;利用均值漂移算法得到分割图,对分割图块中的像素点光谱值求和做平均得到局部空间信息;随机选取原高光谱图像数据中的每一类别样本,对样本数少的类别采用smote技术过采样预处理,然后对各个类别样本两两训练支持向量机;对分类超平面上由少数类和多数类训练的支持向量再次过采样;结合空谱信息对测试样本利用混合核支持向量机分类器得到分类图;最后由最大投票方法对分割图和分类图融合得到最终的分类结果。又如专利文献cn111695389a公开的一种车道线聚类方法及装置,该方法包括:获取车道线特征图像,将车道线特征图像中的像素点按照预设规则构成特征点集合;根据预设条件依次从特征点集合中的选取特征点组,并对特征点组进行横向聚类,生成各聚类组;分别计算各聚类组的聚类中心;根据预设车道线保留条件及各聚类中心与已有车道线集合的关系对已有车道线集合中的车道线进行更新,并返回根据预设条件将特征点集合中的特征点组进行横向聚类,生成各聚类组的步骤,直至遍历完特征点集合,得到车道线特征图像的聚类结果。以上方法虽然实现了车道线聚类方法,但其中心思想是通过获取车道线特征图像,从图像的视觉特征去进行聚类,不仅需要提前制定预设规则,同样也并不适用于所有类型的道路要素。因此,针对大量包含不同类型的众包道路对象数据,结合常见聚类算法的不足之处,找到一种聚类算法准确且快速的实现更好的聚类结果,是目前亟待解决的问题。
6、因此,有必要开发一种众包地图道路对象要素聚类方法、存储介质、设备及车辆。
技术实现思路
1、本发明的目的在于提供一种众包地图道路对象要素聚类方法、系统及存储介质,以提高算法的效率,且计算量小、不受异常点影响,能适用于多种数据分布类型的聚类。
2、第一方面,本发明所述的一种众包地图道路对象要素聚类方法,包括以下步骤:
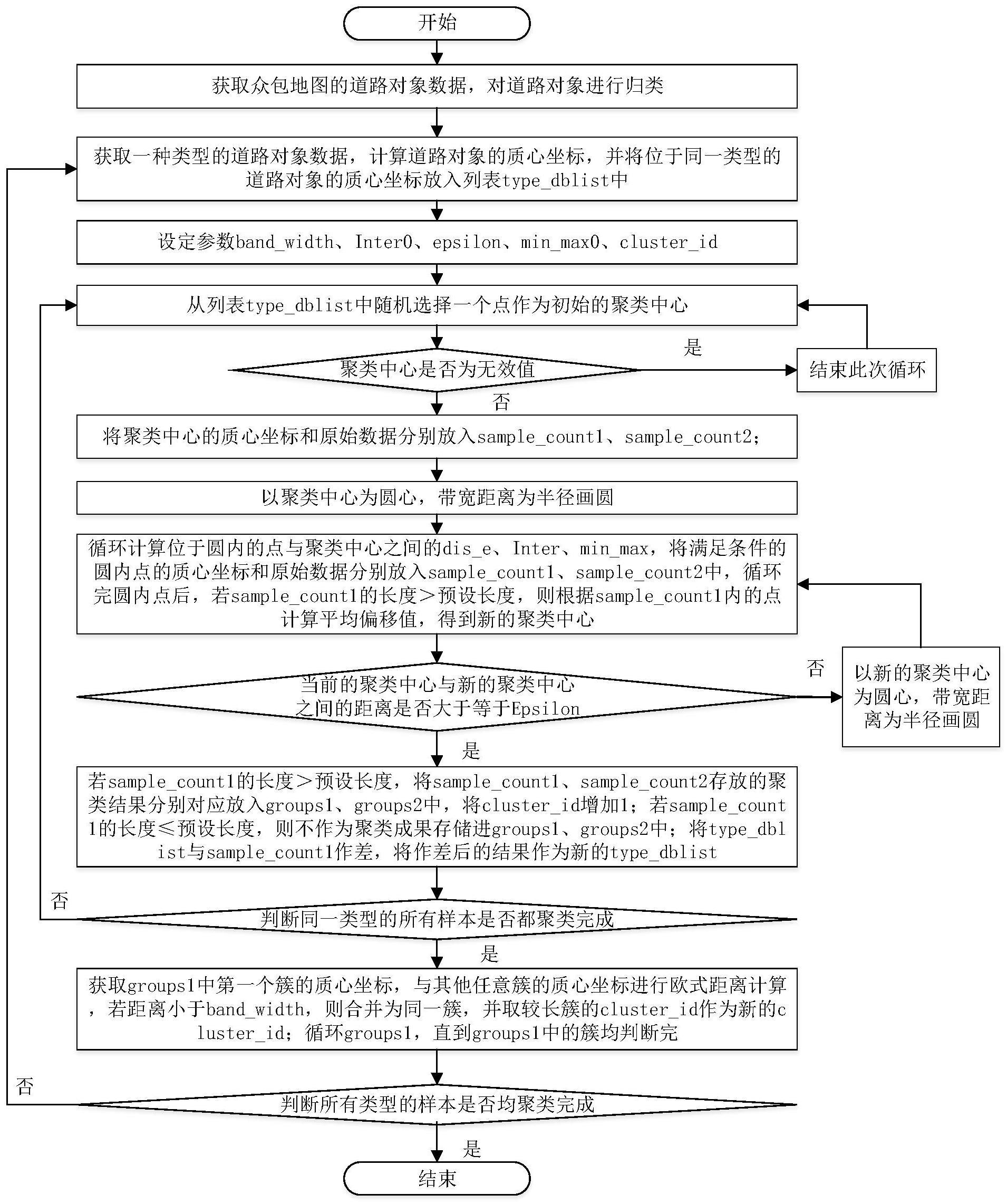
3、s1:获取众包地图的道路对象数据,对道路对象要素进行归类,随机选择一种类型的道路对象数据,计算道路对象的质心坐标,并将位于同一类别的道路对象的质心坐标放入一列表type_dblist中;
4、s2:定义参数:设定初始聚类中心与聚类样本点之间的带宽距离band_width、相交面积与较小面积之比的阈值inter0、两个质心坐标的距离阈值epsilon、较小面积与较大面积之比的阈值min_max0,以及cluster_id的初始值,其中,cluster_id为聚类类别标签;
5、s3:当列表type_dblist不为空时,在列表type_dblist中随机选择一个点作为初始的聚类中心,若该聚类中心为无效值,则结束此次循环,并重新选取一个点;否则将该聚类中心的质心坐标放入列表sample_count1,将该聚类中心的原始数据放入列表sample_count2;
6、s4:以聚类中心为圆心,带宽距离band_width为半径画圆,循环计算位于圆内的点与聚类中心之间的质心距离dis_e、相交面积与较小面积之比inter、较小面积与较大面积之比min_max,将同时满足dis_e<epsilon,inter<inter0,且min_max<min_max0的圆内点的质心坐标和原始数据分别放入列表sample_count1、列表sample_count2中,循环完圆内点后,若列表sample_count1的长度大于预设长度,则根据列表sample_count1内的点计算平均偏移值,得到新的聚类中心;若当前的聚类中心与新的聚类中心之间的距离≥epsilon时,则进入步骤s5;反之,则以新的聚类中心为圆心,重复执行步骤s4;
7、s5:判断列表sample_count1的长度,若列表sample_count1的长度>预设长度,将聚类结果进行保存,将列表sample_count1、列表sample_count2存放的聚类结果分别对应放入列表groups1、列表groups2中,此时认为同属于第一个簇的样本已全部找到,将cluster_id增加1;若列表sample_count1的长度≤预设长度,则认为是异常点,不作为聚类成果存储进列表groups1、列表groups2中;最后将列表type_dblist与列表sample_count1作差,将作差后的结果作为新的列表type_dblist,循环步骤s3-s5,直到同一类型的所有的样本都聚类完成,并进入步骤s6;
8、s6:循环列表groups1,获取groups1中第一个簇的质心坐标,与其他任意簇的质心坐标进行欧式距离计算,若距离小于带宽距离band_width,则合并为同一簇,并取较长簇的cluster_id作为新的cluster_id;已经过合并的簇就不再进行下一次合并簇判断,直到列表groups1里面的簇都循环判断完一遍为止;
9、s7:至此当前道路对象要素的聚类结果已全部输出,再进行不同类型的最外层循环,循环步骤s1-s6,直到所有类型的样本均聚类完成。
10、可选地,所述步骤s1中,获取众包地图的道路对象数据,对道路对象要素进行归类,具体包括:
11、s11:采集众包地图道路要素对象数据,经数据清洗、数据标定得到道路对象要素;
12、s12:将道路对象要素按照预设对象要素分类规则进行归类,得到不同类型的道路对象数据。
13、可选地,所述步骤s4中,质心距离dis_e的计算方法,具体为:
14、假设当前的质心坐标点为d维空间中的x(x,x2,…,xi,…,xd),待聚类列表中的样本点为y=[y1,y2,…,yj,…,yn],其中,n为样本数量,yj(y,y2,…,yi…,yd);
15、则质心距离的计算公式如下:
16、
17、其中,dis(x,yj)表示质心距离。
18、可选地,所述步骤s4中,相交面积与最小面积之比inter的计算方法为:
19、假设初始聚类中心对象的面积为area1,待聚类样本对象的面积为area2,两个对象的相交面积为intersection_area;
20、则两个对象的相交面积与较小面积之比inter为:
21、inter=intersection_area/min(area1,area2)。
22、可选地,所述步骤s4中,较小面积与较大面积之比min_max的计算方法为:
23、假设初始聚类中心对象的面积为area1,待聚类样本对象的面积为area2,两个对象的相交面积为intersection_area;
24、则两个对象的较小面积与较大面积之比min_max为:
25、min_max=min(area1,area2)/max(area1,area2)。
26、可选地,所述步骤s4中,计算新的聚类中心的方法如下:
27、
28、
29、new_center=numerator/denominator
30、其中,denominator为分母,numerator为分子,new_center为新的聚类中心。
31、可选地,所述步骤s6中,
32、假设列表groups1中有簇[c1,c2,…ck,…,cm],其中,ck中存储了属于ck簇所有样本点的质心坐标[ck1,ck2,…,ckt,…,ckp],计算ck簇所有样本点的质心坐标平均值的公式如下:
33、
34、
35、其中,cd_mean为ck簇中所有样本点的质心坐标平均值;c为ck簇中所有样本点的质心坐标的和。
36、可选地,如果d=2,则ck簇的平均质心坐标为(x1_mean,x2_mean),如果d=3,则ck簇的平均质心坐标为(x1_mean,x2_mean,x3_mean),以此类推,其中,d为维度。
37、可选地,对道路对象要素进行归类,具体为:
38、将道路对象按照对象的类型和子类型进行分类。
39、可选地,所述类型包括箭头、车线、地面标志、边界中的至少一种;
40、其中,箭头的子类型包括右转、直行+左转、直行+右转、左转+右转、左前方、右前方、直行+掉头、左转+掉头、左掉头、右掉头、禁止左转、禁止右转、禁止调头、禁止左转和右转、禁止左转和调头、禁止右转和调头、左转+直行+右转、左转+右转+调头中的至少一种;
41、车线的子类型包括虚拟线、细虚线段、粗虚线段、单虚线、单实线、双虚线、双实线、左实右虚线、右实左虚线、铺设边缘线、停止线、斑马线、减速带、停车让行线、导流线、停车位标线中的至少一种;
42、地面标志的子类型包括文字、地面限速中的至少一种;
43、边界的子类型包括护栏、路沿、栅栏、地理边界、墙体中的至少一种。
44、第二方面,本发明所述的一种众包地图道路对象要素聚类系统,包括处理器和存储器;其中,所述存储器内存储有计算机可读程序,所述计算机可读程序被处理器调用时,能执行如本发明所述的众包地图道路对象要素聚类方法的步骤。
45、第三方面,本发明所述的一种存储介质,其内存储有计算机可读程序,所述计算机可读程序被调用时,能执行如本发明所述的众包地图道路对象要素聚类方法的步骤。
46、本发明具有以下优点:
47、(1)由于本发明所采用的数据是多边形类型,本发明将复杂的多边形类型转换为质心进行表达,以便后续的聚类。
48、(2)常规的均值漂移算法一般只将距离作为判断,本发明在此基础上,将多边形对象转换为质心作为突破点,综合考虑质心的距离、相交面积与较小面积对象的比、较小面积与较大面积比等多几何关系实现对象数据的聚类。
49、(3)本发明改进的均值漂移算法能够很好地解决异常点以及极小簇的影响,对数据类型和数据分布也不敏感,聚类速度较快,能够较好地适用于复杂的道路对象要素数据。
50、(4)本发明还针对道路对象要素数据的特殊性,在聚类过程进行判断,不仅考虑对象之间的关系,还会扩大聚类对象的范围,综合考虑对象与其邻域对象之间的关系。
51、综上所述,本发明具有效率高,计算量小,且不受异常点影响的优点,能够适用于多种数据分布类型的聚类。
- 还没有人留言评论。精彩留言会获得点赞!