开源许可证法律条款识别方法与装置
本发明属于计算机,涉及一种开源许可证法律条款识别方法及装置,特别涉及一种用于识别开源许可证法律条款内容及其约束倾向的深度学习文本分类算法。
背景技术:
1、当前,开源已经成为软件创新和软件产业发展的主要趋势。与此同时,开源软件的开发和使用也伴随着多种风险,其中最大的风险就是潜在的知识产权风险。通常情况下,软件开发者会为软件或组件选择不同的开源许可证(允许在既定的法律条款下使用、修改或共享源代码的许可证)来约束软件或组件的使用条件,保护自己的知识产权,维护软件的长远发展。
2、现有的开源许可证风险分析,大多集中在许可证的合规性风险分析和兼容性风险分析。其中,许可证的合规性风险主要针对某一单独的许可证进行评估。许可证中声明的约束越多,使用该许可证的软件或组件合规的难度就越大,许可证的合规性风险就越高。许可证的兼容性风险主要针对两个不同的许可证进行判定。通常情况下,开源许可证可大致分为2类:permissive许可证(宽松自由许可证)和copyleft许可证(著佐权许可证)。apache,mit,bsd都是permissive许可证,gpl则是典型的copyleft许可证。两类许可证最大的区别是:copyleft许可证规定修改和扩展软件必须使用相同的许可证,即要求使用相同许可证进行修改和扩展后的分发;而permissive许可证则没有这项规定,即不要求使用相同许可证进行修改和扩展后的分发。因此,若某一个开源软件或组件同时声明使用apache和gpl许可证,则这两个许可证在“使用相同许可证进行分发”这项具体的法律条款上具有不同的约束倾向,存在兼容性风险,该开源软件或组件可能存在知识产权风险。
3、简言之,当前的开源许可证风险分析方法的分析对象是许可证文件,不同的许可证之间是否存在兼容性风险主要根据许可证所属类别判断。然而,目前没有官方定义的开源许可证分类标准。因此,兼容性风险的判断依据也不够合理。由以上例子可知,不同开源许可证中特定法律条款的约束倾向是否一致是判断两个许可证之间是否存在兼容性风险的更为具体准确的依据。使用深度学习文本分类这种人工智能方法,可以通过模拟人脑的思维过程,理解许可证文本的语义。具体地,可以通过给许可证文本中的语句分类,自动化地识别许可证文本中声明的特定的法律条款并判断条款的约束倾向(允许/不允许、要求/不要求等)。
4、综上,准确识别开源许可证中声明的特定的法律条款及其约束倾向有助于判断不同许可证之间是否存在兼容性风险。因此,本发明提供了一个基于深度学习文本分类算法的开源许可证法律条款识别装置。
技术实现思路
1、为了解决上述问题,本发明提供一种开源许可证法律条款识别方法及装置,为判断不同开源许可证之间是否存在兼容性风险提供更为准确合理的依据。
2、为了实现上述发明目的,发明了以下技术方案:
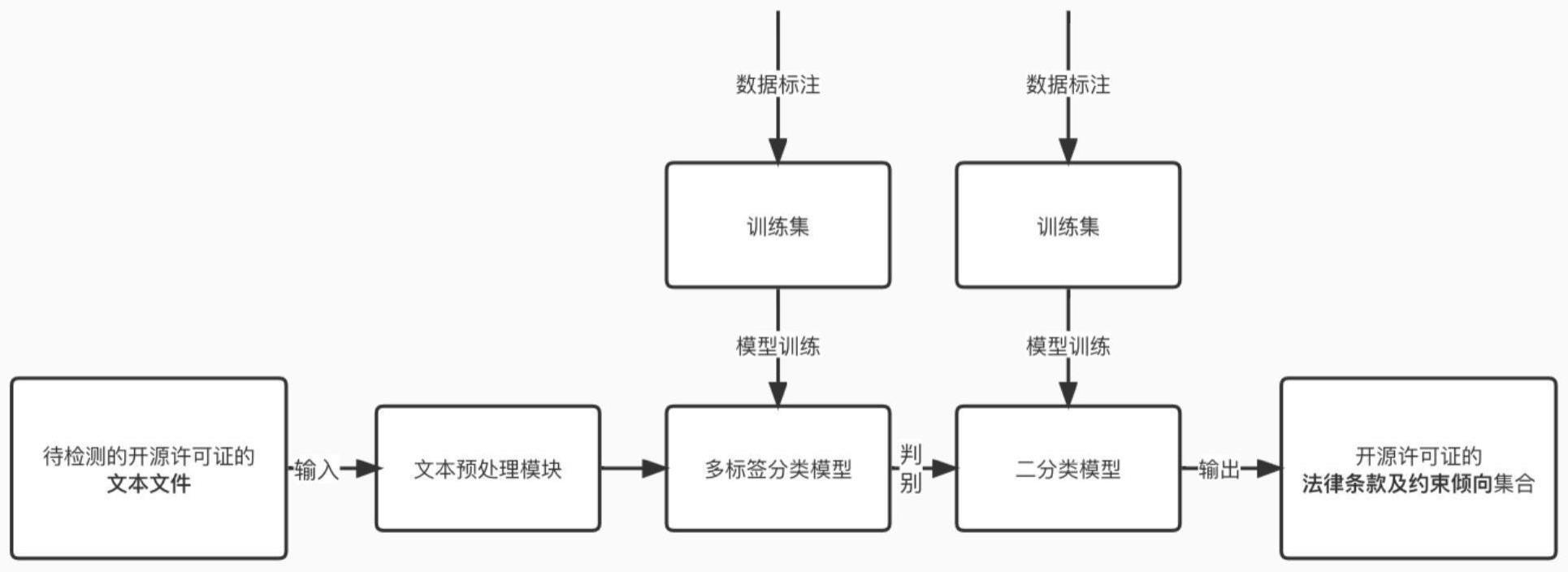
3、一种开源许可证法律条款识别方法,所述方法包括:
4、将开源软件的许可证文本切分成若干个语句;
5、对每一语句进行法律条款的多标签分类,以获取包含法律条款的语句以及该语句中的法律条款;
6、对包含法律条款的语句进行约束倾向的分类,得到所述许可证文本中法律条款对应的约束倾向;
7、基于所述法律条款及该法律条款对应的约束倾向,得到所述许可证文本中法律条款的识别结果。
8、进一步地,所述将开源软件的许可证文本文件切分成若干个语句,包括:
9、获取开源软件的许可证文本;
10、基于所述许可证文本包含的句号、分号和冒号,对所述许可证文本切分,以得到若干个语句。
11、进一步地,所述对每一语句进行法律条款的多标签分类,以获取包含法律条款的语句,包括:
12、对所述语句进行分词;
13、识别每一个法律条款标签的英文描述,并构建标签句子向量矩阵c;
14、基于预训练词向量模型计算每一个词的词向量,并构建第一语句词向量矩阵;
15、将所述第一语句词向量矩阵输入至一个单层的bi-lstm神经网络,得到所述语句的句子矩阵h;
16、利用自注意力机制对所述语句的句子矩阵h进行特征提取,得到所述语句的特征矩阵m(s);
17、基于所述标签句子向量矩阵c,对所述语句的句子矩阵h进行标签注意力机制的特征提取,得到所述语句的特征矩阵m(l);
18、根据所述特征矩阵m(s)和所述特征矩阵m(l),得到融合矩阵m;
19、使用sigmoid函数对融合矩阵m进行计算,得到所述语句的法律条款标签;其中,所述法律条款标签包括k个维度,每一维度表示对应一法律条款的类型。
20、进一步地,所述将所述第一语句词向量矩阵输入至一个单层的bi-lstm神经网络,得到所述语句的句子矩阵h,包括:
21、计算第p个时间戳的正向传播状态其中,表示第p-1个时间戳的正向传播状态,wp表示所述语句中第p个词的词向量;
22、计算第p个时间戳的反向传播状态其中,表示第p-1个时间戳的反向传播状态;
23、基于各时间戳的正向传播状态构建正向传播矩阵其中,n表示所述语句中词的数量;
24、基于各时间戳的反向传播状态构建反向传播矩阵
25、根据所述正向传播矩阵和所述反向传播矩阵得到所述语句的句子矩阵h。
26、进一步地,利用自注意力机制对所述语句的句子矩阵h进行特征提取,得到所述语句的特征矩阵m(s),包括:
27、计算自注意力分数a(s)=softmax(w2tanh(w1h));其中,w1和w2为权重矩阵;
28、基于所述自注意力分数a(s)和所述语句的句子矩阵h,得到所述语句的特征矩阵m(s)。
29、进一步地,所述基于所述标签句子向量矩阵,对所述语句的句子矩阵h进行标签注意力机制的特征提取,得到所述语句的特征矩阵m(l),包括:
30、计算标签注意力分数a(l)=ch;
31、基于所述标签注意力分数a(l)和所述语句的句子矩阵h,得到所述语句的特征矩阵m(l)。
32、进一步地,所述法律条款的类型包括:商业用途、分发、修改、私人使用、专利使用、商标使用、代码开源、许可与版权声明、相同许可证、修改记录、免责和担保。
33、进一步地,所述对包含法律条款的语句进行约束倾向的分类,得到所述许可证文本中法律条款对应的约束倾向,包括:
34、将所述包含法律条款的语句输入至预训练albert模型,得到第二语句特征向量矩阵;
35、对所述第二语句特征向量矩阵进行分类,得到所述许可证文本中法律条款对应的约束倾向。
36、一种开源许可证法律条款识别装置,所述装置包括:
37、文本预处理模块,用于将开源软件的许可证文本切分成若干个语句;
38、多标签分类模块,用于对每一语句进行法律条款的多标签分类,以获取包含法律条款的语句以及该语句中的法律条款;
39、二分类模块,用于对包含法律条款的语句进行约束倾向的分类,得到所述许可证文本中法律条款对应的约束倾向;基于所述法律条款及该法律条款对应的约束倾向,得到所述许可证文本中法律条款的识别结果。
40、一种电子设备,其特征在于,包括:处理器,以及存储有计算机程序指令的存储器;所述处理器执行所述计算机程序指令时实现上述任一所述的开源许可证法律条款识别方法。
41、与现有技术相比,本发明设计并实现了一个使用深度学习文本分类模型识别开源许可证法律条款的装置。本发明中使用的深度学习文本分类模型可以通过训练,自主地学习识别开源许可证中声明的特定的法律条款和判断条款约束倾向的方法,大大节省了人力和时间成本。本发明可被广泛应用于开源许可证兼容性风险分析领域,供广大软件开发者和专家使用。
- 还没有人留言评论。精彩留言会获得点赞!