一种多语言的视觉词义消歧方法
本发明涉及计算机视觉和自然语言处理的综合领域,具体涉及一种多语言的视觉词义消歧方法。
背景技术:
1、近年来,随着信息技术和深度学习的不断发展,网络上也产生大量不同模态的数据数据,推动了计算机视觉和自然语言处理技术的发展。在传统的深度学习研究当中,大部分研究仅仅关注数据的单一模态,可能会导致数据信息不够全面导致结果的可靠性不高并且无法满足多种应用场景的需求。然而在真实世界中,数据往往是以不同的模态存在的。因此,结合多种数据来源(如文本、图像、语音)来进行研究和分析,以实现更加准确和全面的信息理解和实现跨模态的信息融合,为自然语言处理和计算机视觉的研究提供更多的数据来源,从而推动这些领域的发展。
2、视觉词义消歧(visual word sense disambiguation)是计算机视觉和自然语言处理领域中的一项综合任务,目的通过给定不同语言的词和上下文,在候选图像中选择与目标词预期含义最相似的图像。我们将难题转换为计算文本和图像的相似度计算任务。
3、然而,目前基于深度学习的文本和图像相似度计算方法为主要为基于交叉注意力机制方法,由于交叉注意力机制需要计算图像和文本中所有位置之间的相似度,导致计算复杂度高,并且当输入的文本存在错误或者噪声时,交叉注意力机极容易受到干扰,影响性能。
技术实现思路
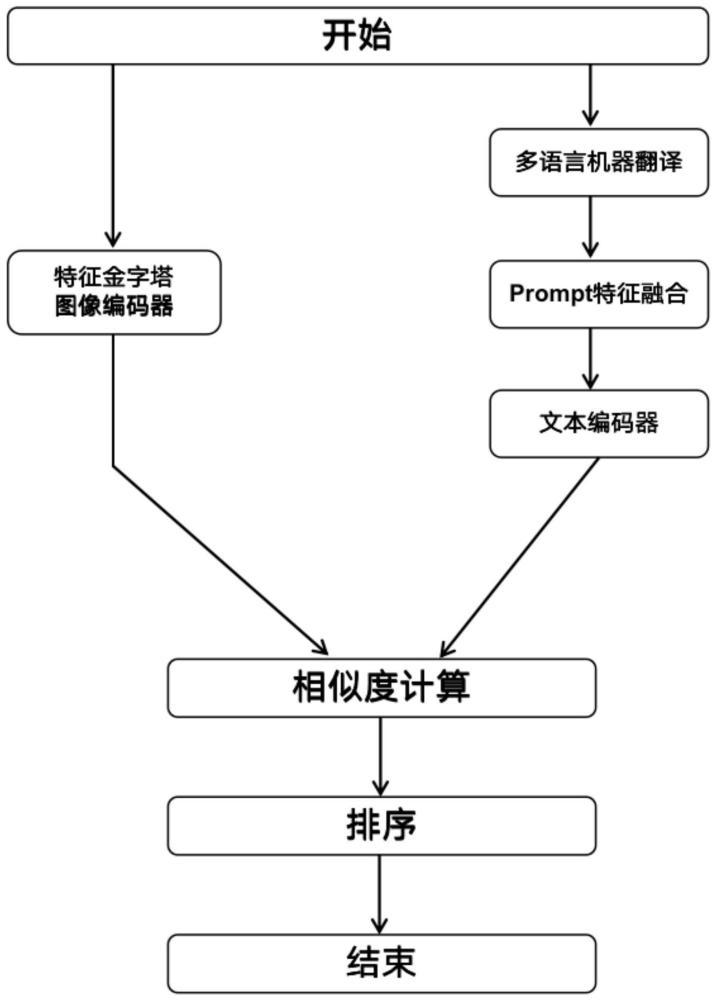
1、本发明通过构建由多语言机器翻译模块、文本编码器模块、图像编码器模块、相似度计算模块、排序模块组成的视觉词义消歧模型,解决多语言的视觉词义消歧问题。
2、实现本发明目的具体技术步骤如下:
3、s1.多语言机器翻译模块接受给定的不同语言的上下文作为输入,编码器通过将不同语言的句子转化成一个语义表示向量,解码器根据语义表示向量和输入时生成的目标语言单词序列,逐步翻译成对应的目标语言;
4、s2文本编码器模块通过对s1得到的目标语言,选取合适的prompt工程并融合到s1多语言机器翻译得到的文本当中作为输入,将输入的文本转换为一个表示文本的序列,最后该序列输入到多个层级的transformer编码器进行处理,得到一个表示整个文本的固定维度向量表示;
5、s3图像编码器模块使用引入特征金字塔结构的“vision transformer”网络模型,通过不同分辨率和尺度的特征提取器和transformer编码器结合,实现了对候选图像不同层次、不同尺度的信息建模和学习以获取更全面的多尺度视觉信息;
6、s4.相似度计算模块通过将s2文本编码器的得到的整个文本的固定维度向量表示和s3图像编码器得到的固定维度向量表示进行余弦相似度计算,作为文本和图像的相似度评分标准;
7、s5.排序模块将通过s4得到的余弦相似度进行排序,从候选图像中得到与给定目标词最相似的图像。
8、步骤s1所述的多语言机器翻译,将给定的不同语言的上下文翻译成对应的目标语言,具体包括如下步骤:
9、a.预处理阶段:对给定的不同语言的上下文本进行分词、标记化和编码等预处理步骤,以便模型能够对其进行处理;
10、b.编码阶段:将步骤a得到源文本语言编码成一个语义表示向量。具体公式为:ht=fenc(xt,ht-1)其中,xt是第t个时间步的输入,ht是第t个时间步的隐藏状态,fenc()是编码器的函数;
11、c.解码阶段:将步骤b得到语义表示向量,生成目标语言的文本。具体公式为:st+1=fdec(yt,st,c)其中,yt是第t个时间步的输出,st是第t个时间步的隐藏状态,c是编码器生成的语义表示,fdec()是解码器的函数。
12、步骤s2中由步骤s1得到目标语言的上下文,其特征在于进行分词和嵌入操作,转换为一个表示文本的序列,输入到多个层级的transformer编码器中进行处理,在每个transformer编码器中,输入序列首先经过自注意力(self-attention)层,用于捕捉序列内部的关联性,然后通过前馈神经网络(feedforward neural network)层,进一步提取文本特征,最终每个transformer编码器会输出一个与输入序列长度相同的表示文本的序列,其中每个位置的向量表示捕捉了该位置的文本信息和上下文关系,具体计算公式为:
13、词嵌入层:将输入的文本序列x=[x1,x2...xn]中的每个词xi映射为一个d维的向量ei,其中d是词嵌入的维度。词嵌入层的计算公式为:
14、e=[e1,e2.....en]=embedding(x) (1)
15、多头自注意力层:对词嵌入向量进行多头自注意力计算,得到一个n×d的输出向量a,其中n是文本序列的长度,d是隐藏层维度。多头自注意力层的计算公式为:
16、mha(q,k,v)=concat(head1,....,headn)wo (2)
17、
18、a=mhe(e,e,e) (4)
19、其中,q=k=v=e是自注意力机制的输入,是分别作用于q,k,v的权重矩阵,h是头数,attention是自注意力机制公式,concat是将所有头的输出拼接起来,wo是输出向量的权重矩阵。
20、前馈神经网络层:对多头自注意力层的输出向量a进行前馈神经网络计算,得到一个n×d的输出向量f。前馈神经网络层的计算公式为:
21、f=max(0,aw1+b1)w2+b2 (5)
22、其中,w1,b1,w2,b2是可学习的权重矩阵和偏置向量,max是relu激活函数。最终,文本编码器的输出向量为n×d的f。
23、步骤s3中的图像编码器为引入特征金字塔结构的“vision transformer”的图像编码器对候选图像进行特征提取
24、具体流程为:
25、对于每个stage中的视觉提取器的具体流程为:
26、假设输入的图像为其中himg和wimg表示图像的高度和宽度,cimg表示通道数。
27、首先将图像划分成若干个大小为p×p的patchs,假设图像的总patchs数为n,则每个patchs可以表示为一个p×p×c的张量。
28、接着,将每个patchs张量进行展平操作,将其转换成一个长度为d的向量,其中d=p×p×c。展平操作可以表示为:
29、xi,j=flatten(xi:i+p-1,j:j+p-1) (6)
30、其中,xi,j∈rd表示第i行第j列的patchs所对应的向量,xi:i+p-1,j:j+p-1表示输入图像中从(i,j)开始大小为p×p×c的子矩阵,flatten()表示展平操作。
31、将所有的patchs向量堆叠起来,形成一个n×d的矩阵:
32、x=[x1,x2,····xh-p+1,w-p+1] (7)
33、最后,将得到的n×d的矩阵x作为输入,通过线性变换得到矩阵:
34、z=xw+b (8)
35、其中,w∈rd表示线性变换的权重矩阵,b∈rd表示偏置项,z表示嵌入的维度。
36、得到的z即为每个patchs的特征表示。
37、将每个patchs和位置嵌入送到transformer编码器中,并且将每个stage输出reshape后得到{f1,f2,···fn}尺寸为h×w/p2,其中p的步幅可以为4,8,16,32,对不同stage的得到的特征金字塔{f1,f2,···fn}分别做1*1卷积处理,这样得到的不同尺度的特征可以和文本编码器的输出向量进行相似度计算。
38、步骤s4根据步骤s2得到的文本固定维度向量和步骤s3得到的图像固定维度向量进行余弦相似度计算,作为文本和图像的相似度评分标准。余弦相似度计算是一种衡量向量之间相似度的常用方法,通过计算两个向量之间的夹角余弦值,值越接近1表示向量越相似,值越接近-1表示向量越不相似。
39、步骤s5计算得到的余弦相似度进行排序,取相似度最大值作为与给定目标词最相似的图像。
- 还没有人留言评论。精彩留言会获得点赞!