基于图对比学习的未知目标立场检测方法、装置
本发明涉及数据挖掘分析,具体涉及一种基于图对比学习的未知目标立场检测方法、装置。
背景技术:
1、文本立场检测,也称为立场分类或立场识别,是指从用户发表的文本中自动判断其对于预先给定目标的立场。文本立场检测与文本情感分析是文本意见挖掘领域的重要研究方向,与文本情感分析不同的是,文本立场检测需要判别表达方式更为复杂的“支持、反对或中立”的立场,而不是对指定对象的积极或消极的情感极性。
2、传统特定目标的立场检测,更多的是针对单一目标立场检测的,是指给定单一的文本(推特、微博、新闻文章、辩论文本等)以及目标,需要确定文本对给定的目标的态度是支持、反对或者中立,即假设训练集和测试集中存在着相同目标的数据。然而,实际中收集所有目标主题的数据用于训练是不可行的,总是存在大量的未出现过目标的数据,且针对一个新的目标话题,获取其高质量的标签往往是很昂贵的,因此研究自适应未知目标的未知目标立场检测至关重要。
技术实现思路
1、本发明要解决的技术问题是:提供一种基于图对比学习的未知目标立场检测方法,通过采集社交网络文本数据,得到评论文本对主题文本所持立场的概率。
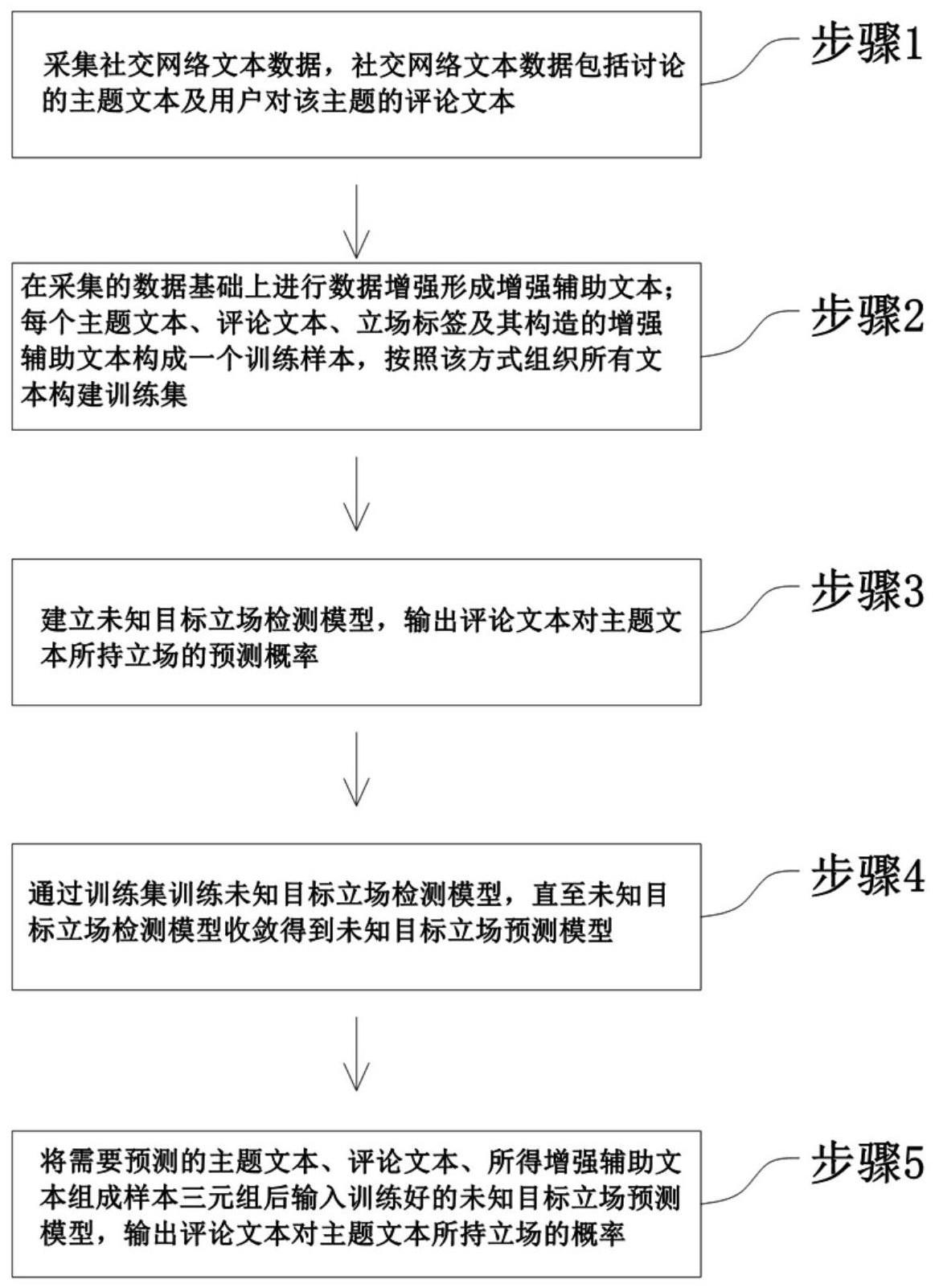
2、本发明解决上述技术问题所采用的技术方案是:一种基于图对比学习的未知目标立场检测方法,包括以下步骤:
3、1)采集数据:采集社交网络文本数据,社交网络文本数据包括讨论的主题文本及用户对该主题的评论文本。
4、2)在采集的数据基础上进行数据增强形成增强辅助文本;每个主题文本、评论文本、立场标签及其构造的增强辅助文本构成一个训练样本,按照该方式组织所有文本构建训练集;
5、3)建立未知目标立场检测模型,输出评论文本对主题文本所持立场的预测概率;
6、4)通过训练集训练未知目标立场检测模型,直至未知目标立场检测模型收敛得到未知目标立场预测模型;
7、5)将需要预测的主题文本、评论文本、所得增强辅助文本组成样本三元组后输入训练好的未知目标立场预测模型,输出评论文本对主题文本所持立场的概率。
8、优选的,所述增强辅助文本包括第一辅助文本和第二辅助文本;对每个评论文本掩码其内容中关键词构造第一辅助文本,对每个评论文本掩码其内容中的非关键词构造第二辅助文本;
9、有立场标签的已知话题目标数据集合为即训练集;无立场标签的未知目标数据集合即测试集;其中是已知话题目标中有标记样例的立场标签,和分别为掩盖掉内容关键词的第一辅助文本和掩盖掉内容非关键词的第二辅助文本,ns和nd分别为已知目标和未知目标的样本个数,使用已知话题目标数据集合中关于已知话题目标的每一个句子训练未知目标立场检测模型,使得该未知目标立场检测模型泛化到新出现的未知目标数据集合上,预测关于未知目标的句子的立场。
10、优选的,所述未知目标立场检测模型基于图对比学习,所述未知目标立场检测模型包括特征编码模块和句法表征及语义表征提取模块;
11、特征编码模块:将所述主题文本、评论文本和/或增强辅助文本作为输入,输出主题文本、评论文本和/或增强辅助文本的特征和句法结构图;
12、句法表征及语义表征提取模块包括句法表征提取模块和语义表征提取模块,
13、对每个评论文本掩码其内容中关键词构造第一辅助文本,将获得的掩盖关键词的第一辅助文本以及句法结构图作为句法表征提取模块的输入,句法表征提取模块输出句法模式特征;
14、对每个评论文本掩码其内容中的非关键词构造第二辅助文本;将获得的掩盖非关键词的第二辅助文本以及句法结构图作为语义表征提取模块的输入,语义表征提取模块输出语义表征特征。
15、优选的,所述未知目标立场检测模型还包括全局语义重建模块、立场检测模块;
16、全局语义重建模块:将获得的句法模式特征和语义表征特征作为输入,输出句法与语义的融合特征;
17、立场检测模块:将获得的句法与语义的融合特征作为输入,输出评论文本对主题文本所持立场的预测概率。
18、优选的,所述特征编码模块学习文本的向量化特征表示;若是单个的文本r,将其构造为“[cls]r[sep]”格式输入给特征编码模块;若是针对主题目标t的评论x,则其将每个样例构造为"[cls]t[sep]x[sep]"格式输入给特征编码模块,得到[cls]标记隐藏层的dm维向量作为输入的特征表示,以及输入句子x所有单词在最后一层隐藏层的特征矩阵
19、z,z=fθ(x)=bertbase([cls]t[sep]r[sep]
20、在一个训练批中,所有样例的特征表示可定义为nb为训练批的大小。
21、优选的,所述句法表征及语义表征提取模块中,所述句法表征提取模块和语义表征提取模块分别将文本结构分解为句法表征结构图和语义表征结构图,分别从目标无关特征和目标依赖特征的角度对文本语义进行表示。
22、优选的,所述句法表征及语义表征提取模块中,基于句法依存树为每个句子构造图,以捕获句子中的词之间依赖关系;每个句子的邻接矩阵可以表示为:
23、
24、其中,ai,j为邻接矩阵第i行第j列的状态,x(wi,wj)表示句子x的句法依存树中单词wi与单词wj有边相连。
25、优选的,所述句法表征及语义表征提取模块中,掩码关键词的句子与邻接矩阵a构成了“句法表征结构图”;掩码非关键词的句子与邻接矩阵a构成了“语义表征结构图”;
26、
27、
28、其中,分别为“句法表征结构图”的初始特征矩阵和“语义表征结构图”的初始特征矩阵,分别对应句法表征结构图中结点的特征向量和语义表征结构图中结点的特征向量。
29、优选的,所述句法表征及语义表征提取模块中,将“句法表征结构图”的特征矩阵和归一化的邻接矩阵输入gcn模块(图卷积神经网络模块)获取上下文中目标无关的句法特征矩阵;
30、
31、其中,为句法结构第l层卷积的特征矩阵,d为度矩阵,为可训练的权重矩阵;
32、将“语义表征结构图”的特征矩阵和归一化的邻接矩阵输入gcn模块获取上下文中主题目标依赖的语义特征矩阵;
33、
34、其中,为语义结构第l层卷积的特征矩阵。
35、已知主题目标t的特征为采用基于检索的注意力机制学习句法特征矩阵与特定目标的关系度。
36、
37、
38、其中,αj为的第j个特征对的注意力,t表示向量的转置操作,为可学习的参数。进而,我们计算得到代表句法表达模式的融合特征:
39、
40、其中,为可学习的参数,
41、优选的,所述句法表征及语义表征提取模块中,定义一个神经网络投影头h=gψ(f)=w(2)σ(w(1)f),将特征向量映射到计算对比损失的空间,其中σ(·)是一个relu非线性激活函数;针对第i样例,经过投影后的正样本对的特征表示为其对比学习的训练目标为:
42、
43、其中,sim(u,v)=utv/||u||||v||表示向量u和v在l2标准化后的余弦相似度。τ为温度参数;
44、所述句法表征及语义表征提取模块中,在每个训练批的对比学习损失为:
45、
46、其中,为训练批数据增强后的数据集合,其大小为2nb。
47、优选的,所述全局语义重建模块中,将原始评论文本的编码z=fθ(x)作为全局语义特征,融合特征定义为:
48、
49、
50、
51、
52、其中,gcns,gcnt分别为针对“句法表征结构图”和“语义表征结构图”的图卷积模块;为句法模式向语义表征主动融合的特征,为语义表征向句法模式主动融合的特征;两种融合特征通过平均池化转换为一维向量特征,其定义为:
53、
54、进一步地,通过kl散度保持原始全局语义特征和重建语义特征间分布一致性。
55、
56、因此,全局语义保持的学习目标为:
57、
58、优选的,所述立场检测模块中,采用具有softmax归一化的全连接层预测概率分布:
59、
60、其中,为输入样例xi预测的立场概率分布,dp为立场标签的维度,和为可学习参数,dm为隐藏层表示维度。
61、进一步地,通过对样例的预测标签与真实标签y的交叉熵损失来训练分类器:
62、
63、优选的,所述未知目标立场预测模型中,学习目标为通过立场分类损失组间对比学习损失和全局语义保持损失来训练模型;
64、
65、其中,α、β是可调节的超参数,θ表示模型中所有可训练的参数,λ表示l2正则化系数。
66、一种计算机装置,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现如上述的基于图对比学习的未知目标立场检测方法。
67、一种计算机可读存储介质,其上存储有程序,程序被处理器执行时实现如上述的基于图对比学习的未知目标立场检测方法。
68、本发明的有益效果是:本发明的基于图对比学习的未知目标立场检测方法,通过在社交网络媒体中采集数据,在采集的数据基础上进行数据增强形成增强辅助文本;每个主题文本、评论文本、立场标签及其构造的增强辅助文本构成一个训练样本,按照该方式组织所有文本构建训练集;建立未知目标立场检测模型,输出评论文本对主题文本所持立场的预测概率,并收敛得到未知目标立场预测模型;将需要预测的主题文本、评论文本、所得增强辅助文本组成样本三元组后输入训练好的未知目标立场预测模型,输出评论文本对主题文本所持立场的概率。
69、句法表征提取模块和语义表征提取模块分别将文本结构分解为句法表征结构图和语义表征结构图,分别从目标无关特征和目标依赖特征的角度对文本语义进行表示。本发明的未知目标立场检测方法,通过构建分别关注“句法表征”和“语义表征”的双视角特征图,并利用图对比学习方法学习目标无关的句法结构特征,以此作为跨目标特征共享的桥梁。通过图对比学习,增强了语用特征表征质量,本发明可以很好的处理未知目标立场预测任务。
- 还没有人留言评论。精彩留言会获得点赞!