一种机械硬盘和固态硬盘混合存储系统及方法
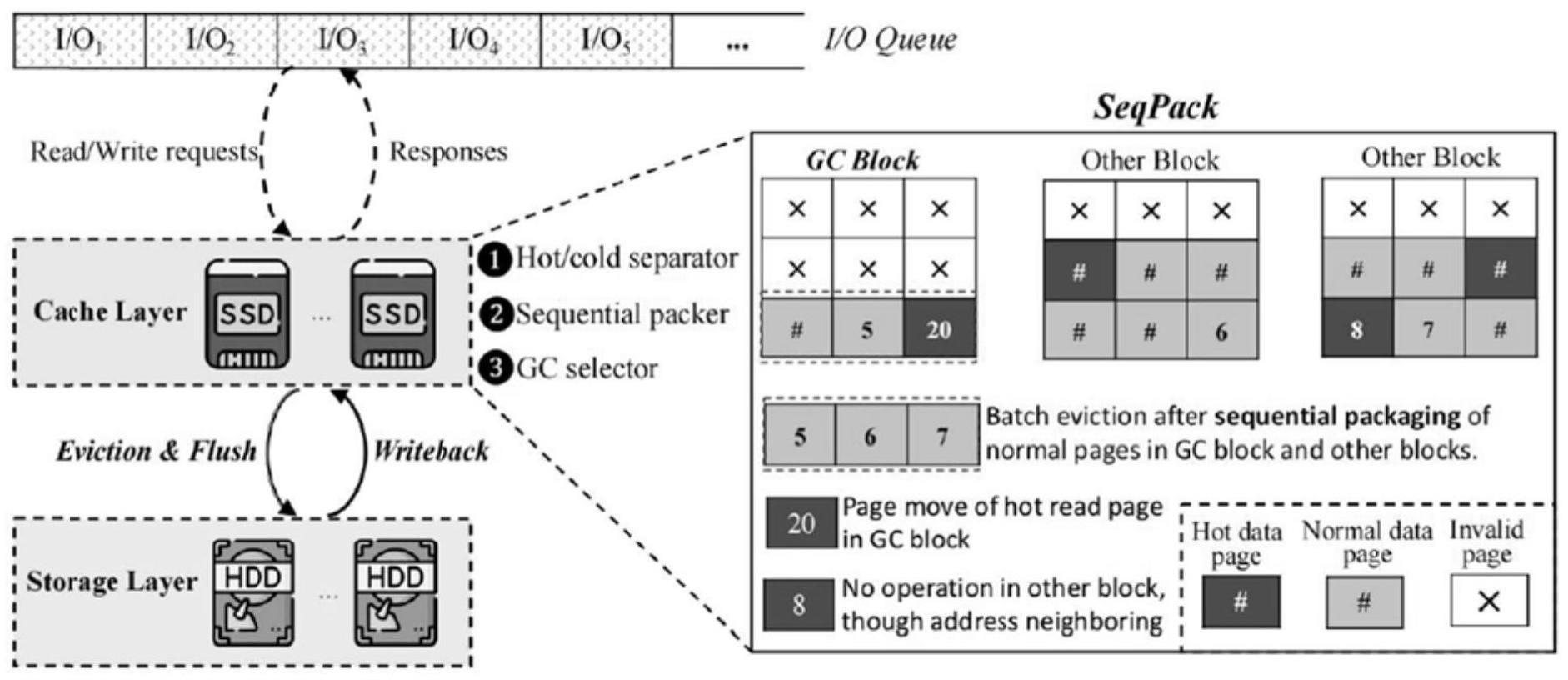
本发明涉及硬盘存储,具体涉及一种机械硬盘和固态硬盘混合存储系统及方法。
背景技术:
1、传统机械硬盘(hdd)和固态硬盘(ssd)在i/o延迟,读写成本以及寿命等方面都有各自的优势和限制。为了发挥出它们各自个最大的优势,通常采用ssd-hdd混合存储以实现低成本高收益。常用的混合存储选题采用基于nand闪存的ssd作为非易失性缓存和传统的hdd作为较低级别的存储,并以类似hdd的成本提供类似ssd的i/o访问。
2、当ssd的存储空间少于阈值时,将ssd缓存数据向hdd慢速存储的驱逐。由于ssd异位更新(out-place update),即数据更新需要将旧的数据标记为无效,在其他的位置进行写入操作,以此完成数据的更新,和写入前擦除(erase-before-program)的特性,即在写入新数据之前,采用垃圾收集(gc)操作来回收ssd空间,这对应于缓存驱逐的过程。它将gc块中的有效数据页刷新到hdd,然后将其擦除,擦除后就可以再次写入数据到该块。针对这些问题,现有技术中提出了各种方案,比如有在准确识别热有效数据页,在gc过程中将它们保留在ssd的快速存储中,以获得更好的i/o性能。另一方面,hdd在提供高顺序带宽方面具有成本效益,但在随机i/o吞吐量方面仍然远远落后于ssd。
技术实现思路
1、本发明针对现有技术的不足,提出一种用于ssd-hdd混合存储系统,在每次驱逐时提供更多可用的缓存空间,而不显著增加将数据刷新到hdd所需的时间,从而最大限度地减少缓存驱逐的负面影响,对应于以垃圾粒度执行的垃圾收集进程,在驱逐过程中,将垃圾收集块和其它ssd块中的地址相邻的冷数据页分组,并通过充分利用高顺序带宽将写到hdd上的机械硬盘和固态硬盘混合存储系统及方法,具体技术方案如下:
2、一种机械硬盘和固态硬盘混合存储系统,设置有冷/热数据分离器,用于在发生读或写访问后,将数据页插入或移动到相应链表的头部,然后,两个lru链表都维护着最近访问的读写页,筛选出热读数据页,并且可以一直缓存在ssd缓存中,同时其它数据页被视为顺序打包的候选者;
3、设置有顺序打包器,通过将垃圾收集块中的弹出页与其它ssd块中的冷数据页打包,将随机写入分组为一个大型顺序写入;
4、设置有垃圾收集选择器,用于基于成本的选择方法来定位垃圾收集目标块,用于制造缓存空间。
5、作为优化:所述顺序打包器工作方法为,针对在当前垃圾收集块内的页面,当其被从ssd写入到hdd中时;记这部分时间为t1,它由两部分构成,其一,将更多的数据从ssd中写入hdd并垃圾收集后,ssd中的有效空间会增大,其他条件不变,ssd达到下一次需要执行垃圾收集的时间会延长,在相同时间内垃圾收集的总次数会减少,即节省了总的垃圾收集时间,将一个网页移动带来的平均垃圾收集节省时间记为tsaving;
6、其二,如果要将该页面移动到hdd中,垃圾收集时就不需要在ssd中再移动,最后将其直接擦除,这会节省一个写操作时间tw_ssd,即
7、t1=tsaving+tw_ssd (1)
8、记这部分时间为t2,它源于两个渠道,第一,将页面写入hdd的时间tw_hdd,第二,若该页面的数据在下一次写入前被读取,数据从hdd中读取的时间会超过从ssd中读取的时间,故增加的时间为tr_hdd-tr_ssd,同时,数据还会被再次写入到ssd中,即增加一个写操作时间tw_ssd;
9、记数据在下一次更新前被读取的概率为p1,则
10、t2=tw_hdd+p1(tr_hdd-tr_ssd +tw_ssd) (2)
11、显然,当t1>t2时,该页被从ssd写入hdd是有利于缩短系统时间的,反之亦然;
12、分析t1和t2的时间构成,发现时间参数tsaving,tw_ssd,tr_hdd,tr_ssd和tw_ssd都可以视为常数,p1是最关键的变量,当某页的p1越小,它被写入hdd的机会更大,为估计p1我们假设某页在单位时间内的写次数n1和读次数n2分别服从于参数为λ1的λ2的泊松分布,且两者是独立的,令t1和t2分别为该页两次写和两次读之间的间隔时间,nt为t时间内该页的读次数,f(t)为t1的概率密度函数,则
13、
14、整理(1)、(2)和(3)式可得,第一类page在垃圾收集时被写入hdd的条件为,
15、
16、分析(4)式,某个页的读写冷热程度直接与它是否应该被写入hdd中相关,为避免估计计算大量的时间参数,采用机制1来实现(4)式的筛选算法:
17、机制1:在ssd中建立一个热读数据的列表和一个热写数据列表,针对第一类page,执行垃圾收集时只将存在于热读列表中同时不在热写列表中的数据保留在ssd中,而将其他数据写入到hdd中;
18、针对被打包的其它块的page,是否将其打包顺序写入hdd中取决于两个方面的因素;
19、一方面,将该类page打包写入hdd中可能会增加该次垃圾收集中page从ssd写入到hdd的总时间,我们记单个page所增加的时间为tw_hdd_nongc,它等于包含和不包含该page的总写时间之差;因为包含该page的写入必然是顺序写入,而不包含该page的写入是随机写入,由于hdd硬件的特性,所以两者之差必然要小于一个page被单独写入hdd的时间tw_hdd,即tw_hdd_nongc<tw_hdd;
20、另一方面,若该类page已经被打包写入到hdd中,经过一段时间的系统运行,该page所在的block将执行垃圾收集,此时存在两种状态,一种状态是,该page未被更新,则此时该page将被置为无效,在gc中直接擦除,不用再写入到hdd中,可以认为该操作将一个page被单独写入hdd的时间tw_hdd减少为tw_hdd_nongc,此时时间的节省值为tw_hdd-tw_hdd_nongc;
21、另一种状态是,该page已被更新,虽然此时该page已被置为无效,在该次垃圾收集中不用再被写入到hdd中,但在上次打包写入hdd中的数据就已经失去了价值,打包写入增加的时间tw_hdd_nongc为净损失,记第一种状态发生的概率为p2,第二种状态发生的概率为1-p2,显然,只有打包写入第二类page增加的总时间t3的期望值小于0时,打包写入才可行,即
22、
23、同理,在假设某页在单位时间内的写次数n1服从于参数为λ1的泊松分布的条件下,令t*为该页所在的block执行垃圾收集时与当前垃圾收集的间隔时间,则
24、
25、
26、故第二类page在垃圾收集时被打包写入hdd的条件为,
27、
28、显然,分析(7)式可得,更应该利用hdd顺序写单位时间成本低的优势将写频率更低的数据打包写入hdd中,按照机制1的方式,设计机制2:
29、针对第二类page,执行gc时只将能够构成顺序写的数据同时不在热写列表中的数据写入到hdd中,而将其他数据保留在ssd中。
30、作为优化:所述垃圾收集选择器具体为,支持顺序打包后,ssd缓存块数据页,包括无效页(type 1)、有效页但在hdd上有副本(type 2)、热读冷写页(type 4),和其它页面(类型3),在缓存替换时触发的垃圾收集过程中,前两类数据页可以直接移除,第三类数据页直接写入hdd,最后一类数据页移动到其它ssd block,不同的数据类型在垃圾收集过程中有不同的开销;
31、另一方面,垃圾分类操作的目的是以更小的成本释放ssd空间,因此引入了一种基于成本的选择方法来定位垃圾目标块,考虑到我们对ssd块中不同类型的数据页进行了不同的操作,等式8定义了使用给定ssd块估算垃圾收集成本的细节,其中,在敏感研究之后,对于块中的类型1到类型4数据页,我们分别有1.0、0.5、0.25和0;
32、
33、其中n1、n2、n3和n4代表不同的页码页面类型;如公式8中所定义,τ的值意味着更多的无效在hdd上有副本的页面和有效页面,两者都可以在垃圾期间直接删除,减小垃圾收集成本,因此,τ最大值的ssd块将被选为垃圾收集块,用于制造缓存空间。
34、本发明的有益效果为:除了传统的lru方法(标记为baseline),我们将ssdup+方案作为另一个比较对应物。ssdup+采用一种新颖的i/o流量检测方法来检测正在运行的用户应用程序的数据访问模式。然后,只有随机访问写入被定向到ssd,而剩余的写入被视为顺序访问并直接分发到hdd。我们认为ssdup+是最相关的工作,因为它考虑了i/o工作负载的访问模式,从而区分了顺序在混合存储系统中写入数据和随机写入数据。
35、1、敏感性分析
36、本发明的设计原则,每个顺序打包的页数限制决定了可以分组然后一起刷新到hdd上的数据页的最大大小,顺序写入。这个限制是一个敏感性参数,选择意味着工程权衡。打包页面限制小可能无法发挥顺序打包的优势,限制大可能会增加数据刷新的时间。我们已经进行了不同大小限制的敏感性测试,从2到64不等。图4显示了使用本发明方法时总体i/o延迟(相比于baseline)的标准化结果。可以看出,它可以在大多数跟踪中产生最佳结果,而页码限制为8。因此,我们在本发明方法的每个顺序打包操作中使用8作为默认的页码限制。
37、2、i/o延迟
38、i/o响应时间是存储系统的主要性能指标。图5显示了重放所选跟踪后i/o响应时间的标准化结果。如图所示,本发明提案在i/o响应时间的测量上优于其他提案。更具体地说,与baseline和ssdup+相比,它平均降低了45.59%和22.64%的平均i/o延迟。有一个异常情况,在运行具有最大顺序写入工作负载比例的lun2跟踪的情况下,我们看到ssdup+的相关工作与我们提出的方法相比,i/o延迟显着降低了43.53%。ssdup+不是先将写入数据缓存到ssd缓存中,而是直接将顺序访问的数据刷新到hdd上,这样当用户应用程序有许多顺序写入请求时,它可以大大减少写入延迟。
39、3、缓存命中率
40、术语缓存命中是指读取请求中的页面被ssd缓存吸收的比例,而不访问底层hdd。更高的缓存命中率意味着对底层hdd阵列的访问更少,这有助于提高i/o性能。换句话说,如果读取请求可以直接响应ssd缓存中的数据页,则相应的读取请求可以以更少的延迟完成。图6(a)报告了使用不同缓存驱逐方案运行基准测试后的命中率结果。如图所示,与其他算法相比,所提出的本发明方法方案提供了最高的命中率。具体来说,与baseline和ssdup+相比,本发明方法将缓存命中率平均提高了0.62%和10.45%。另一方面,ssdup+的缓存命中率结果最差,因为它直接将顺序写入刷新到hdd,导致ssd缓存中的后续读取命中率下降。为了更好地解决这个问题,我们还记录了从hdd获取数据页并将其放入ssd缓存的回写次数,以响应错过的读取请求。如图6(b)所示,ssdup+导致最大数量的回写。我们认为本发明方法通过将热读取数据页移动到其他ssd块来将热读取数据页保留在ssd缓存中,同时它们的原始块承受gc操作,这可以提高读取命中的数量。
41、4、长尾时延
42、长尾延迟是反映运行应用程序时i/o响应能力的另一个关键指标。基于顺序打包的缓存驱逐旨在通过充分利用hdd的高顺序带宽来提高平均i/o延迟,而不影响长尾延迟。图7显示了使用不同缓存驱逐方案重放所选跟踪后i/o请求的长尾延迟(在累积分布函数中)的比较。baseline的线几乎是最低的,因为它没有使用任何优化策略来减少长尾延迟。我们提出的本发明方法在所有跟踪中表现出比使用其他选定方案更好的长尾延迟,除了lun2的跟踪。更具体地说,ssdup+在重放lun2的trace时具有最小的尾部延迟,因为该trace具有最大的顺序写入请求比例,并且直接将它们刷新到hdd有助于提高i/o性能。但是,与baseline和ssdup+相比,本发明可以在第99.99个百分位处平均减少38.54%和38.91%的长尾延迟。这一事实证明,本发明将垃圾收集块和其他ssd块中的地址相邻冷读数据页分组,并以顺序的方式将它们一起写入hdd,不会对i/o请求的尾延迟产生负面影。
- 还没有人留言评论。精彩留言会获得点赞!