一种面向对比学习的动态课程的句子表示方法
本发明涉及自然语言处理领域,具体来说是一种面向对比学习的动态课程的句子表示方法。
背景技术:
1、随着互联网技术的飞速发展,语言作为人类基本的能力,让机器处理自然语言是生产力发展的必然要求,因此从事研究自然语言处理研究具有重要价值和意义。句子表示作为自然语言处理领域中的主要研究方向之一,通过预训练微调的方式被应用到具体的下游任务的应用中。
2、早期的句子表示的方法通过one-hot,tf-idf等基于词袋模型的方法导致数据稀疏。后面利用word2vec用滑动窗口指定固定大小的上下文,利用当前词语预测上下文或者利用上下文文来预测当前词。由于词和向量是一对一的关系,因此无法解决一词多义的问题。bert预训练致力于学习通用的句子表示,并迁移到多个下游应用场景。由于直接利用bert得到的句子表示的效果不是很好,因为直接由语言模型生成的语义向量分布中存在非线性和各向异性的问题,导致任意两个句子的相似度很高,在语义空间中坍缩在一个狭小的空间内。
3、自监督学习通过利用辅助任务从大规模的无监督数据中挖掘自身的监督信息来对网络进行训练,从而学习到对下游任务有价值的表征。对比学习作为自监督学习的一种,在模型训练过程中通过拉近相似数据,推开不相似数据能缓解上述bert句子表示造成的各向异性的问题,从而获得有效的数据表示。在对比学习中,一般通过数据增强的方式获得不同的正样本,在同一批次中的训练数据中,除了锚点样本以外的其他样本作为负样本来更好的学习数据之间的有效信息。而对比学习的核心在于如何构建正负样本的集合。在cv中,通过对图片进行旋转、裁剪、翻转、颜色变换等操作进行数据增强。在nlp中,数据增强的方法往往通过回译,随机删除、字符插入、同义词替换等方式构造正样本。然而由于自然语言的高度抽象性质,这些数据增强的方法不能保持生成的正样本的质量,例如生成的正样本太容易或者太难,如果忽略样本的质量将生成的正样本等同看待会造成句子表示不准确,从而限制了在对比学习中的性能。因此,如何保证正样本的质量对面向对比学习的句子表示具有重要作用。
技术实现思路
1、本发明是为解决现有基于对比学习中正样本质量的不足,提出一种面向对比学习的动态课程的句子表示方法,以期待能更加充分挖掘正样本表示信息,以实现句子表示更精确的建模,从而能提高句子表示的性能。
2、本发明为解决技术问题采用如下技术方案:
3、本发明一种面向对比学习的动态课程的句子表示方法的特点在于,是按如下步骤进行:
4、步骤1、文本数据的预处理:
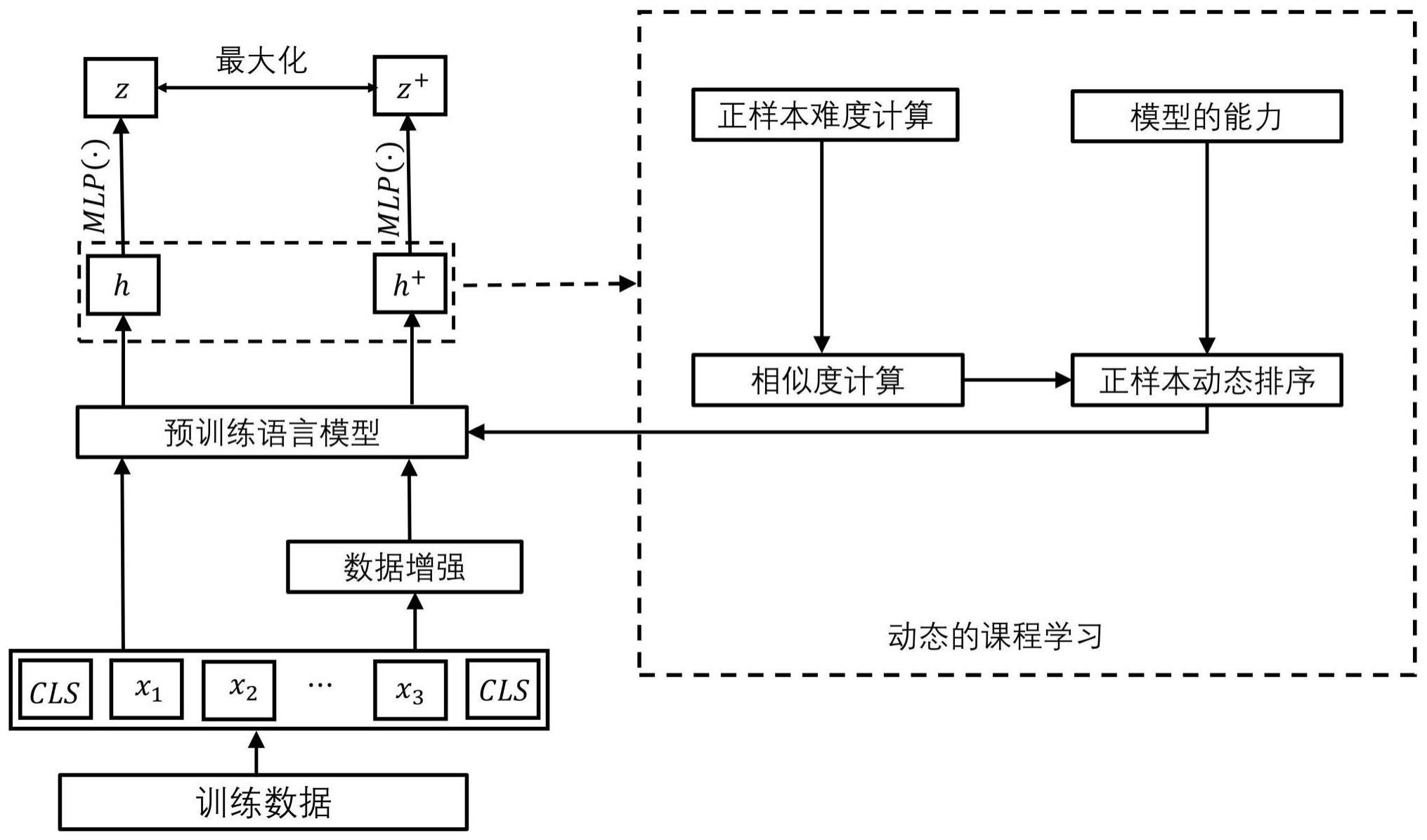
5、步骤1.1、获取n个句子s={s1,…,si,…,sn}并进行数据增强后,得到增强后的句子数据集,记为其中,si表示第i个锚点句子,n表示句子总数;表示第i个锚点句子si增强后的句子集合,并作为第i个正样本集合,且表示第i个锚点句子si增强后的第j个句子并作为一个正样本,m表示每个句子增强后的句子总数;
6、令s′表示预处理后的句子对集合,且
7、步骤2、构建对比学习模型,包括:编码模块、投影模块;其中,所述投影模块是由一层mlp线性层组成;
8、步骤2.1、所述编码模块对句子集合s′中的每个句子进行编码,获得表征其中,hi表示第i个锚点句子si的表征向量,表示增强后的第j个正样本句子的表征向量;
9、步骤2.2、所述投影模块将句子向量表示hi和映射到低维语义向量空间中,从而得到句子向量表示为其中,zi表示第i个锚点句子si的表征向量hi的低维句子表征向量;表示第j个句子的表征向量的低维句子表征向量;
10、步骤3、计算与hi在语义空间中的余弦相似度距离并作为第i个正样本集合中第j个句子的难度di,j,从而得到n×m个正样本的难度集合d={d1,1,…,di,j,…dn,m},并对难度集合d进行降序排序后得到排序后的难度集合,从而根据排序后的难度集合再对n×m个正样本进行排序,得到排序后的正样本句子对集合,将排序后的正样本句子对集合与其对应的锚点句子配对,从而得到排序后的句子对集合其中,si表示排序后的第i个锚点句子,表示排序后的第i个锚点句子si对应的正样本句子集合中的第j个正样本句子;
11、步骤4、正样本难度选取,令对比学习模型的总的训练迭代次数为t,当前迭代次数为t,并初始化t=1;
12、步骤4.1、利用式(1)计算当前第t迭代下对比学习模型的能力c(t),且c(t)∈(0,1]:
13、
14、式(1)中,c0为对比学习模型的初始能力,并初始化为一个固定值;
15、步骤4.2、利用式(2)计算当前第t迭代下对比学习模型的正样本数量p(t):
16、p(t)=n×m×c(t) (2)
17、步骤4.3、令win为滑动窗口的尺寸,令正样本的训练区间为[p(t)-win,p(t)],且p(t)≥win;从而按照训练区间[p(t)-win,p(t)]对排序后的句子对集合s″进行划分,得到当前第t迭代下由易到难的rt个批次的训练样本;记rt为rt个批次中任意第rt个训练句子对;
18、步骤5、利用式(3)构建第t迭代下rt个批次的损失函数lt;
19、
20、式(3)中,λ表示调节参数,τ表示温度参数,表示排序后的第rt个锚点句子的表征向量的低维句子表征向量,表示排序后的第rt个锚点句子对应的正样本句子集合中的第j个正样本句子的表征向量的低维句子表征向量,sim表示余弦相似度;
21、步骤6、在当前第t迭代下将rt个训练批次的训练样本按顺序依次输入所述对比学习模型中,并利用梯度下降法对所述对比学习模型进行迭代训练,同时计算所述损失函数lt以更新模型参数,直到达到所述损失函数lt收敛为止,从而得到当前第t迭代下的最优对比学习模型;
22、步骤7、将t+1赋值给t后,判断t>t是否成立,若成立,则将第t迭代下的最优对比学习模型作为句子表示性能最好的模型,以实现更高质量的句子表示;否则,返回步骤4.1顺序执行。
23、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述句子表示方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
24、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述句子表示方法的步骤。
25、与现有技术相比,本发明有益效果体现在:
26、1、本发明针对现有的对比学习句子表示方法中通过数据增强的方法生成的正样本随机采样正样本的方式会影响对比学习模型性能,从而提出了一种面向对比学习的动态课程的句子表示方法。通过步骤2和步骤3对锚点句子和增强后的正样本句子相似度计算来作为当前增强后句子的难度,相似度越大,难度越小。对增强后的句子对的难度进行降序排列,从而得到由易到难的句子对序列,缓解了因正样本质量不同带来对比学习模型性能受影响的问题,从而获得了更高质量的句子表示。
27、2、本发明针对每个生成的样本在不同的模型所考虑的难度是不同的,且对于同一个模型,在不同的学习阶段考虑的样本难度也是不同的。通过步骤5、6的动态课程对比学习是根据当前模型的难度进行动态排序,从而更准确的更新正样本质量的排序情况,从而更能提高对比学习模型的性能,并生成更高质量的句子表示。
28、3、本发明利用对比学习通过自监督的方式进行预训练,通过构造正负样本来作为监督信号,在模型训练的过程通过迭代重排序正样本的方式对对比学习的目标进行更好地优化。具体来说,本发明不仅学习到对比学习中句子表示的语义信息而且能更细粒度更准确捕获正样本句子的语义信息,通过调参的方式可以促使模型得到高质量的句子表示。
- 还没有人留言评论。精彩留言会获得点赞!