用于ICD编码的改进型BERT模型构建方法及ICD编码方法与流程
本发明属于病案编码,具体涉及一种用于icd编码的改进型bert模型构建方法及icd编码方法。
背景技术:
1、针对智能icd编码场景下(icd:国际疾病分类international classification ofdiseases是依据疾病的某些特征,按照规则将疾病分门别类,并用编码的方法来表示),当编码人员查看电子病历进行分析时,首先会检查电子病案中病人的各种信息结果给出多个编码结果,然不是只通过出院诊断和手术报告名称。但是想利用各类信息,就需要将先验医学知识直接应用于电子病案的编码中,这是一个是极其困难的,主要存在以下困难点:
2、1)医学知识具有随意性或异质性:一些诊断可能与一些检查报告结果中一些具体指标相关,而一些诊断是与既往病史有关,即诊断过程。
3、2)对编码存在参考价值的知识是零散复杂的,很难用明确的逻辑去总结成规律;
4、基于上述缺陷,有技术人员提出采用分类模型(例如bert模型)进行智能编码,然后随着训练发现,icd编码的数据是极度不平衡的,正对那些罕见的分类,模型得不到足够的数据,很难训练出泛化能力的效果很好的结果。并且编码是需要考虑病历前后文关系,通过分析、挖掘、思考后得到的,那么即使通过大量的数据进行训练还是无法得到可以满足要求的模型,其输出编码准确性与编码员编码之前仍存在较大差距。
5、因此,将离散的任意医疗规则转化为对模型有增强效果的知识库是一个急需改进应用的问题。
技术实现思路
1、医学相关常识和医学规则在智能医疗领域起着重要作用,但是如何将这些先验的医学知识和规则嵌入到模型中,指导模型特定任务的调优是个棘手的问题。针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种用于icd编码的改进型bert模型构建方法及icd编码方法,对bert模型基于医疗知识领域进行适应性改进,将不同类型的医疗先验知识融合入深度模型,提高模型的可行性和编码准确度。
2、为了解决上述技术问题,本发明采用了如下的技术方案:
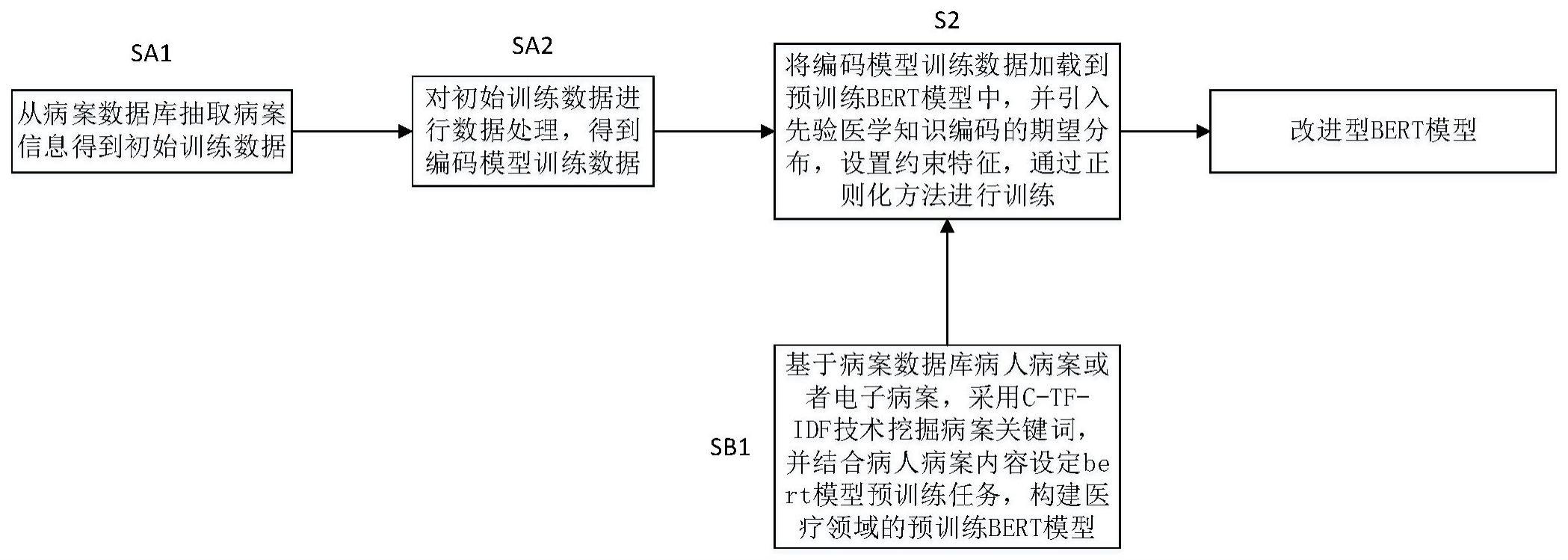
3、一种用于icd编码的改进型bert模型构建方法,其特征在于:按照以下步骤进行:
4、sa1:从病案数据库抽取病案信息得到初始训练数据;
5、sa2:对初始训练数据进行数据处理,得到编码模型训练数据;
6、sb1:基于病案数据库病人病案或者电子病案,采用c-tf-idf技术挖掘病案关键词,并结合病人病案内容设定bert模型预训练任务,构建医疗领域的预训练bert模型;
7、s2:将步骤sa2中获取到的编码模型训练数据加载到步骤sb1得到的预训练bert模型中,并引入先验医学知识编码的期望分布,设置约束特征,通过正则化方法进行训练,得到改进型bert模型。
8、通过上述方案,成功地将离散的先验医学知识进行分类,正对不同类型的先验知识应用不同的技术,将其融入到bert深度编码预测模型中,提供了足够的灵活性来将任意先验知识源作为特征,所以该方法为组合任意的先验知识参与到神经网络的训练过程中。并且训练的目标函数具有可微性,更方便与深度网络模型融合;它能够将不同类型的医疗先验知识融合入深度模型,指导深度模型的有偏向的训练优化,并能够区分不同医疗先验知识对icd编码模型预测的重要性。
9、进一步的,步骤sa1中所述病案信息至少包括病案中出院记录的诊断名称、手术记录的手术名称、病人基本信息、病人特征属性以及icd编码;病人特征属性包括且不仅限于检测指标异常项和现病史项。
10、采用上述方案,结合了不同的病人特征,作为输入来进行结合编码,对编码功能有很好的解释功能,提高编码精准度。
11、再进一步的,步骤sa2中数据处理的内容为:
12、结合文本序列化表将出院记录的诊断名称、手术记录的手术名称进行文本字符序列化;
13、t={t1,t2…,tt};
14、结合病人特征编码表将病人特征属性进行向量化;
15、x={x1,x2…,xk},其中k表示k个病人特征。
16、采用上述方案,经病案进行数字化转换,以融合将文字数值的输入转化成模型所需的数字输入,来进行模型训练。
17、再进一步的技术方案,步骤sb1的具体步骤为:
18、sb11、从病案数据库病人病案中,筛选包括adrg(核心疾病诊断相关组)分组信息的病案;对adrg分组信息中前m位相同的分成一组,得到n组分类病案;m、n为正整数;
19、sb12、对n组分类病案中任意选择一个病案文本,并获取病案关键词,并对病案序列和向量化;
20、病案关键词获取方法:采用c-tf-idf加权技术得到a个病案关键词;
21、sb13、基于病案关键词,根据知识图谱对病案设定至少一个预训练任务来构建预训练的训练数据集:
22、sb14、基于预训练的训练数据集,基于病案数据库病人病案构建医学领域的预训练bert模型。
23、其中,c-tf-idf中“c”表示adrg的分组;“tf-idf”是一种用于信息检索与数据挖掘的常用加权技术。tf是词频(term frequency),idf是逆文本频率指数(inverse documentfrequency)。
24、采用上述技术方案,采用c-tf-idf加权技术对病案关键词进行提取,并结合知识图谱对病案设置预训练任务,以减小病案和模型之间的差异。
25、再进一步的技术方案,步骤sb13预训练任务包括基于知识图谱的病案关键词替换任务、病案文本前向后文关联任务;
26、其中,所述病案关键词替换任务运用于未知的病案数据库的病人病案文本和已知电子病案;
27、所述病案关键词替换任务的具体操作为:
28、确定病案文本中所有病案关键词以及所有病案关键词出现的个数、每个病案关键词的频次、位置;
29、获取所有病案关键词在知识图谱中的解释内容;
30、按照病案关键词出现的先后顺序选择病案关键词,并锁定该病案关键词在病案文本中首次出现的位置;
31、对首次出现的病案关键词内容使用特殊字符[mask]进行替换;
32、结合该病案关键词在知识图谱中的解释,将该特殊字符[mask]采用解释内容进行替换;该病案文本中后续出现的病案关键词保持不变;
33、直至将所有病案关键词替换完成;
34、其中,所述病案文本前向后文关联任务运用于已知电子病案;
35、所述病案文本前向后文关联任务的具体操作为:
36、确定病案文本中所有病案关键词以及所有病案关键词出现的个数、每个病案关键词的频次、位置;
37、获取任意一个病案关键词在知识图谱的解释内容,并获取该病案关键词的负样本关键词以及该负样本关键词在知识图谱的解释内容
38、结合病案关键词、病案关键词在知识图谱的解释内容、负样本关键词、负样本关键词在知识图谱的解释内容进行数据处理后,得到对应特征向量转换来进行bert模型编码,将特征向量组成对比学习损失,来建立该病案关键词在电子病案中前后文的关联关系;
39、直至将所有病案关键词关联完成。
40、采用上述方案,通过设置预训练任务将离散的医学知识融入到不同的阶段中,实现用医学先验的知识提高模型性能的目的。
41、再进一步的技术方案,步骤s2的具体内容为:
42、s21:将步骤sa2得到的编码模型训练数据,输入到步骤sb1得到的预训练bert模型,得多特征输入矩阵;
43、h={h1,h2…,ht,ht+1}=bert_encoder(t1,t2…,tt,x);
44、其中,bert_encoder(.)为预训练bert模型的编码器结构;
45、s22:所述预训练bert模型的编码器结构上增加一个多层感知机,则在归一化指数函数层softmax即可得到icd编码的预测概率分布;
46、则预测的编码概率分布由后验概率分布表示为:p(yp|x(p),θ);
47、s23:根据最大似然交叉熵损失函数得到初始bert模型目标函数;
48、预测的编码概率分布和真实值yp之间的交叉熵平均值为:
49、
50、该交叉熵平均值即为所求初始bert模型目标函数;
51、s24:整合医学知识融入到初始bert模型目标函数中,设置先验知识的约束特征集合引入一个期望分布,该期望分布中医学特征都被描述为期望值;其中:
52、
53、φ(x,y)是特征函数;
54、b是特征的期望的约束边界;
55、s25:将icd编码后验分布p(yp|x(p),θ)和医学上的先验分布q(y)的kl散度作为目标函数的正则项,即:
56、
57、其中,α是一个超参数;是icd编码的个数;kl散度用于测量期望分布和预测值之间差异的kullback leibler散度;
58、s26:用约束集合表示的先验知识替换为对数线性模型表示的先验分布q(y);
59、其中,先验知识采用对数线性模型表示为:
60、其中,γ为权重参数,是根据先验医学知识不同的约束特征类别得到的可学习置信矩阵;
61、则目标函数表示为:
62、
63、
64、s27:再引入逻辑函数来模拟病人属性对icd编码影响,得到使用多层感知机模型学习先验医学知识编码的期望分布为:
65、
66、为icd编码和病人属性之间的参数集;
67、则得到最终的改进型bert模型:
68、
69、采用上述方案,基于bert神经网络的预测模型来获取所有可能的icd编码的预测概率,并结合最大似然交叉熵损失函数得到初始目标函数,整合医学知识融入bert分类模型中,引入一个期望分布并设置约束特征,通过正则化方法得到进一步的目标函数,通过优化新的目标函数得到最优模型来进行参数预测icd编码。基于改进型bert模型,在进行编码校验时,大大提高了编码准确性,使最终编码更接近编码员编码内容。
70、一种icd编码方法,按照以下步骤进行:
71、步骤一:获取病人病案,并对病人病案进行数据处理,得到输入数据;
72、所述数据处理内容为:结合文本序列化表将出院记录的诊断名称、手术记录的手术名称、病人基本信息进行文本字符序列化;
73、t={t1,t2…,tt};
74、结合病人特征编码表将病人特征属性进行向量化;
75、x={x1,x2…,xk},其中k表示k个病人特征。
76、步骤二:将输入数据带入如权利要求1得到的改进型bert模型,输出icd编码。
77、通过上述改进型bert模型,医学知识融入到不同的阶段中,实现用医学先验的知识提高模型性能的目的,使最终编码更加准确。
78、本发明的有益效果:
79、成功地将离散的先验医学知识进行分类,正对不同类型的先验知识应用不同的技术将其融入到深度编码预测模型中。其中,大数据预训练阶段,无监督的构建医学知识库,结合医学编码的知识库对模型的再次预训练,形成医学专业领域的预训练语言模型。模型微调阶段,将医学特征向量化加入到模型中,通过正则化的方法优化模型训练最优化的过程。
80、通过本发明提出的方法,提供了足够的灵活性来将任意先验知识源作为特征,所以该方法为组合任意的先验知识参与到神经网络的训练过程中,并针对不同icd编码给出与其相关的电子病案特征,对编码结果有了很好的解释功能;训练得到的目标函数具有可微性,更方便与深度网络模型融合;它能够将不同类型的医疗先验知识融合入深度模型,指导深度模型的有偏向的训练优化,并能够区分不同医疗先验知识对icd编码模型预测的重要性。在使用bert模型进行icd分类任务时,在bert预训练阶段、bert下游任务的微调阶段fine-tunning分别用了不同的手段将离散的医学知识融入到不同的阶段中,实现用医学先验的知识提高模型性能的目的。
- 还没有人留言评论。精彩留言会获得点赞!