一种基于GPU合并访存的模板计算二维线程块选择方法
本发明涉及高性能计算,具体涉及一种基于gpu合并访存的模板计算二维线程块选择方法。
背景技术:
1、模板计算(stencil computation)是有限差分方法在实现中的一个基本操作,它是一种最近邻计算(nearest-neighbor computation),通常需要遍历一个二维或三维空间网格,使用相邻网格点的数据计算出一个值。直到整个网格都被计算一遍,就能得到当前时间步的输出结果。在有限差分求解器的具体设计中,存在很多不同类型的微分算子,这些算子对应不同的模板计算格式,例如计算偏导数使用同一方向的3点或5点模板,计算拉普拉斯算子使用三个方向的5点、7点甚至13点模板。典型的5点模板计算格式如下,
2、
3、其中,u代表计算涉及的数据,例如温度,下标m,n分别表示x,y方向的输入数据索引,下标t代表当前时间步的输出数据;g是输入数据的函数,即计算公式。该格式由一个点(m,n)周围的5个点计算得到中心位置的新数据。
4、模板计算在gpu上有很快的执行速度,但是进一步提高计算性能会遇到很多困难。从计算特征上看,模板计算是典型的内存受限(memory-bound)类型,平均一个字节数据重复使用的次数不多,例如,在5点模板计算中的任何一个数据点只会被用到5次。相比于矩阵乘法这种数据重用非常多的计算模式,模板计算在gpu上的主要优化目标是减少访存或者隐藏访存延迟。
5、通用gpu架构更新换代非常快,但基本采用同一种编程模型,称为simt。这种模型目前事实上的标准接口为cuda和hip。通过使用cuda/hip,整个三维区域的模板计算可以分解为多个线程块(thread block),每个线程负责实际的计算。然而,每个线程完成计算所需的数据不只是一个点,导致一个线程块内的各个线程都要重复访问同一个数据,例如5点模板计算中,每一个点要被5个相邻的线程使用,也就被重复读取5次。这极大增加了带宽的负担。现行的通用做法是采用合并访存(coalescing)和片上共享内存(shared memory),将一个线程块所需的所有数据一次性读取到离计算单元较近的共享内存上,这一做法从两个方面节省了访存时间:第一,计算单元从gpu全局内存读取数据是按块实现的,合并访存能够最大限度地减少内存访问次数;第二,多个线程访问同一数据时只需要从共享内存读取,比从全局内存读取更快。
6、使用合并访存和片上共享内存时,线程块的形状成为影响计算性能的主要因素。原则上,二维线程块可以满足模板计算的要求,同时考虑一个线程块能够拥有的资源上限和为了调度效率最高应该给定的下限,可以大致确定线程块选择的范围。但是,实际计算中,访存合并、bank冲突、资源限制等因素很多,与应用和硬件的关系都非常紧密,凭经验很难选择适合当前计算的线程块,为了解决上述问题,本发明提出了一种基于gpu合并访存的模板计算二维线程块选择方法。
技术实现思路
1、本发明的目的在于解决凭经验难以选择出计算性能较高的线程块,较差的线程块会导致计算资源利用不完全、负载不平衡、访存开销大的问题,进而提出一种综合考虑多种影响gpu上模板计算的因素的基于gpu合并访存的模板计算二维线程块选择方法。
2、为了实现上述目的,本发明采用了如下技术方案:
3、一种基于gpu合并访存的模板计算二维线程块选择方法,包括如下步骤:
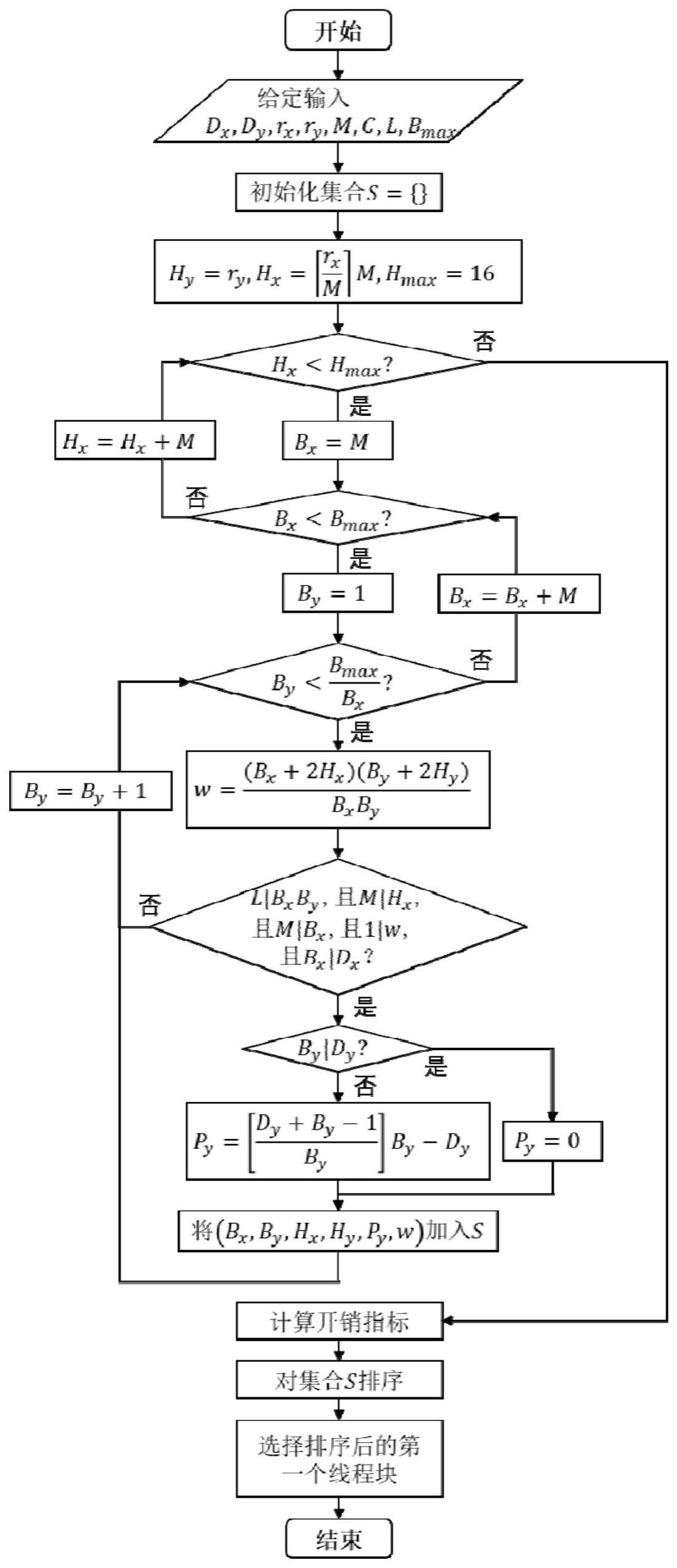
4、s1、给定一个模板计算在二维平面内的半径,确定模板计算过程中一个二维线程块所需的数据形状;
5、s2、基于合并访存技术,计算二维线程块的数据读取次数;给定浮点数精度,获取计算环境的相关信息,确定线程块的筛选条件;
6、s3、依据s2中所述的筛选条件筛选出一个或多个合并访存技术需要的线程块,称为候选线程块;
7、s4、给定开销指标并对其进行排序,依据开销指标从候选线程块中选出理论上最好的线程块,用于实际的gpu计算。
8、优选地,所述s1进一步包括以下内容:假设一个模板计算在二维平面内的半径为rx和ry,则模板计算过程中一个bx×by二维线程块所需的数据形状为(bx+2rx)×(by+2ry),其中,bx×by的部分称为内部,周围的部分表示模板半径内的数据。
9、优选地,s2中所述基于合并访存技术的二维线程块的数据读取次数为整数,且每个二维线程块的数据读取次数均相同;计算二维线程块的数据读取次数时,在数据外侧增加冗余,所述冗余和模板计算半径内的数据一起称为halo区域,将扩充过的数据区域大小记为(bx+2hx)×(by+2hy),具体计算公式为:
10、
11、优选地,s2中所述浮点精度包括有单精度或双精度;所述计算环境相关信息包括有:
12、a)一次内存访存读/写的数据点个数m,称为内存事务;
13、b)gpu共享内存宽度能包含的数据点数量c;
14、c)gpu计算的线程调度单位包含的线程数量l;
15、d)gpu线程块的最大线程数量bmax。
16、优选地,s2中所述线程块的筛选条件,具体为:
17、条件1:bxby≤bmax;其中,bxby表示二维线程块的大小,bmax表示最大的线程块大小;
18、条件2:bxby是l的整数倍;其中,l表示gpu计算的线程调度单位包含的线程数量;
19、条件3:bx是m的整数倍,且hx是m的整数倍;其中,bx表示线程块在x方向的线程数量,m表示一次内存访存读/写的数据点个数,hx表示x方向扩充的数据;
20、条件4:rx≤hx≤bx且ry≤hy≤by;其中,rx和ry表示模板计算在二维平面内的半径;
21、条件5:是整数;
22、条件6:bx是c的整数倍;其中,c表示gpu共享内存宽度能包含的数据点数量;
23、条件7:(dy+py)是by的整数倍;其中,dx×dy×dz表示模板计算处理的三维区域,dx×dy表示三维区域内的二维切片,dy表示二维切片在y方向的线程数量;py表示冗余数据,若by能整除dy,则py=0;若by不能整除dy,则其中,“[]”表示四舍五入计算。
24、优选地,s4中所述开销指标具体包括以下内容:
25、开销指标1:每个二维线程块的数据读取次数,w;
26、开销指标2:冗余数据占总数据的比例,
27、开销指标3:线程块在x方向的线程数量,bx;
28、实际选择过程中,从候选线程块中按照开销指标1、2、3的顺序,选取w较小、i较小、bx较大的线程块用于实际的gpu模板计算。
29、与现有技术相比,本发明提供了一种基于gpu合并访存的模板计算二维线程块选择方法,具备以下有益效果:
30、(1)本发明综合考虑了gpu模板计算合并访存技术、bank冲突、负载平衡等多个因素,建立了约束条件保证选出符合这些限制的候选线程块。
31、(2)本发明设计了保证合并访存技术的性能达到最优的开销指标,能够选出性能最好的线程块。现有技术采用简单的、经验的指标,没有很好地结合模板计算和gpu计算环境两方面的信息。
32、(3)本发明设计了基于数学公式和排序算法的线程块筛选方法,可以实现线程块选择的自动化。
- 还没有人留言评论。精彩留言会获得点赞!