一种事件抽取方法、装置、设备及计算机可读存储介质
本发明涉及信息抽取领域,特别涉及一种事件抽取方法、装置、设备及计算机可读存储介质。
背景技术:
1、事件抽取是自然语言处理中的一项十分重要且非常具有挑战性的任务,其目的是抽取文本中的事件信息。虽然目前事件抽取已经有了大量的研究,但大多数方法都假设句子中没有重叠事件的情况,使得这些方法并不适合处理具有重叠事件问题的场景。并且,现有的大多数事件抽取方法并不能有效的捕获到句子中与重叠事件有关的信息,比如触发词和论元在句子中的间距太远,这种长距离依赖信息就难以被捕获。
2、有鉴于此,提出本技术。
技术实现思路
1、本发明公开了一种事件抽取方法、装置、设备及计算机可读存储介质,旨在解决无法捕获长距离依赖信息以及重叠事件问题;
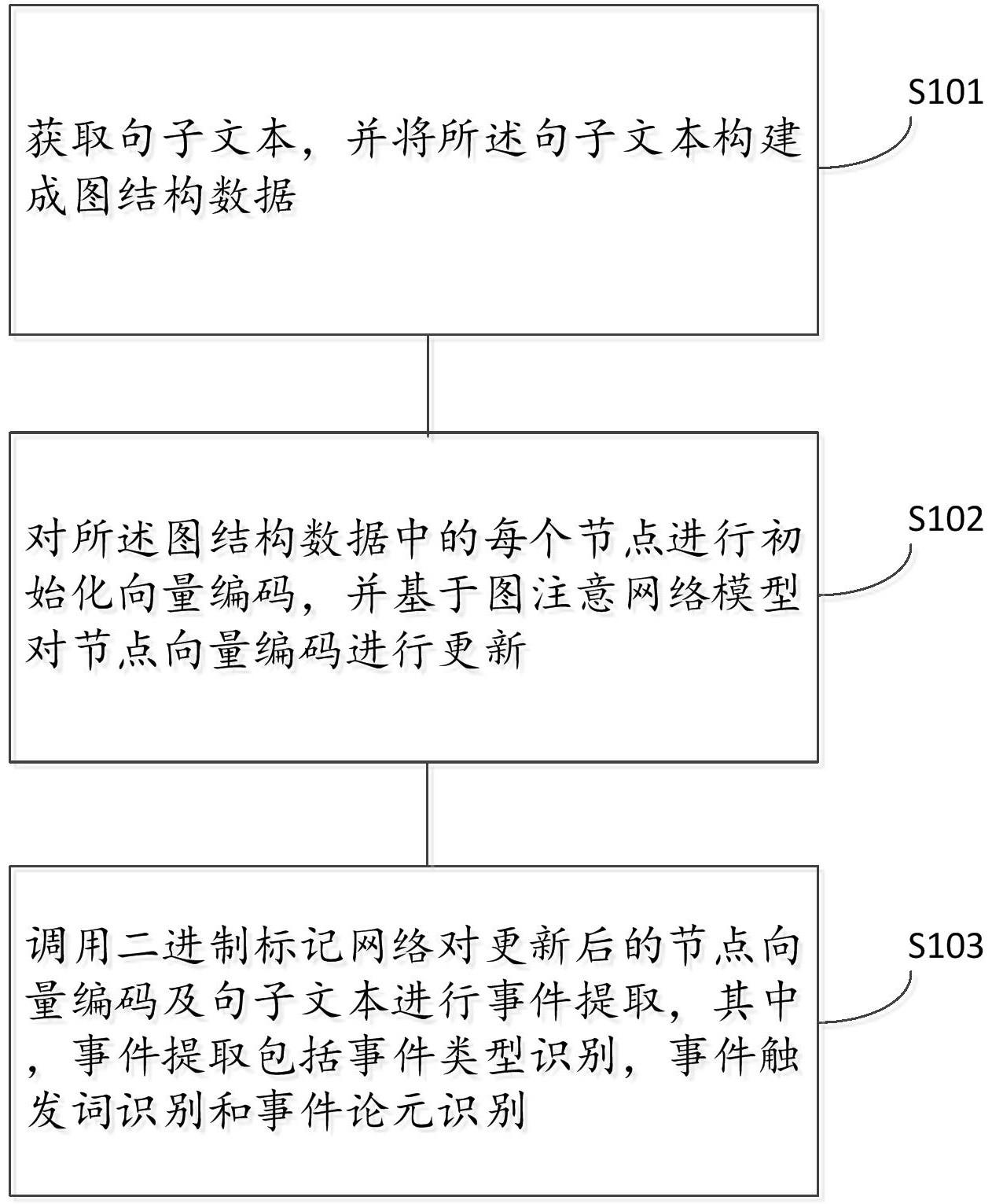
2、本发明第一实施例提供了一种事件抽取方法,包括:
3、获取句子文本,并将所述句子文本构建成图结构数据;
4、对所述图结构数据中的每个节点进行初始化向量编码,并基于图注意网络模型对节点向量编码进行更新;
5、调用二进制标记网络对更新后的节点向量编码及句子文本进行事件提取,其中,事件提取包括事件类型识别,事件触发词识别和事件论元识别。
6、优选地,所述将所述句子文本构建成图结构数据具体为:
7、对句子进行依存句法分析,构建以字为节点,以依存关系为连接边的依存图结构数据;
8、对句子进行命名实体识别,构建以命名实体为节点,以实体与实体首尾字的映射关系为连接,以及构成实体的字序列之间双向连接的实体图结构数据;
9、构建以字自身为起点和终点的自连接图结构数据;
10、将所述依存图结构数据、所述实体图结构数据和所述自连接图结构数据的节点特征进行加权求和、边进行合并,构建句子所对应的图结构数据。
11、优选地,所述对所述图结构数据中的每个节点进行初始化向量编码,并基于图注意网络模型对节点向量编码进行更新具体为:
12、对句子文本中任一字进行向量编码,得到对应的特征向量,,维度包括利用bert获取的预训练特征、查找随机初始化的词性矩阵获取的词性特征和利用绝对位置获取的位置特征,使用bert对实体进行向量编码,得到任一实体对应的特征向量;
13、由句子文本中的字向量和命名实体词向量构成得到融合图结构数据中的节点向量集合对应的初始化向量编码为,其中
14、对图结构数据中的任意两个节点之间进行注意力系数eij的计算,如公式(1)所示:
15、(1)
16、其中,代表第个节点的邻居集合,代表维度为的权重矩阵,代表两个向量拼接的方法,代表单层前馈神经网络;注意力系数归一化处理如公式(2)所示:
17、(2)
18、其中,代表第个节点的邻居集合,k表示第i个节点的第k个邻居节点,leakyrelu代表非线性激活函数,leakyrelu函数的输出值定义为,score小于0的值置为-0.2,score大于0则保持原值,如公式(3)所示:
19、(3)
20、根据计算结果,对节点的向量编码进行加权求和,如公式(4)所示:
21、(4)
22、其中,代表学习到的向量编码,代表sigmoid函数。
23、优选地,所述调用二进制标记网络对更新后的节点向量编码及句子文本进行事件提取,其中,事件提取包括事件类型识别,事件触发词识别和事件论元识别具体为:
24、建立事件类型集合的初始化事件类型向量矩阵;利用注意力机制来计算事件类型与句子文本对应的字节点中每个之间的相关性,如公式(5)~(6)所示:
25、(5)
26、(6)
27、其中为事件类型的个数,为句子文本的长度,和代表权重矩阵,代表事件类型的向量编码,代表绝对值运算操作,代表向量编码点乘操作,代表向量编码串联拼接操作;每个事件类型被预测的概率如公式(7)所示:
28、(7)
29、其中,σ代表sigmoid函数,阈值的事件类型为事件类型预测的结果,;
30、利用条件层标准化模块(condition layer normalization, cln)将预测的事件类型与字信息进行融合,如公式(8)~(10)所示:
31、(8)
32、(9)
33、(10)
34、其中,()为条件层标准化模块,与代表可训练的权重矩阵,与分别代表的均值和标准差;代表条件获得项,代表偏置项,代表字的向量编码,计算得到字向量集合;再将其输入自注意力层;如公式(11)所示:
35、(11)
36、其中,()为自注意力层,将输入二进制标记网络中识别触发词的起始位置和结束位置,如公式(12)~(13)所示:
37、(12)
38、(13)
39、其中,代表句子文本,代表预测到的事件类型,代表sigmoid函数,代表触发词的起始位置,代表触发词的终止位置;和代表维度为的权重矩阵,和代表偏置项;代表句子文本中第个字的向量编码;得到触发词起始位置和终止位置的标注概率序列,起始位置,终止位置,其中,代表句子文本的长度;将任一阈值的字作为触发词的起始位置,将任一阈值的字作为触发词的终止位置,得到事件的触发词,其中;
40、继续利用cln模块将触发词与进行融合,触发词的向量编码为其包含的字向量编码累加取平均,再将结果输入到自注意力网络中,如公式(14)~(15)所示:
41、(14)
42、(15)
43、其中代表触发词词语的长度,代表文本句子的长度,将输入事件论元对应的对组二进制标记网络中识别论元的起始位置和结束位置;如公式(16)~(17)所示:
44、(16)
45、(17)
46、其中,为指示函数,代表论元的起始位置,代表可训练的权重举证,为偏移项,代表乱云的结束位置,代表可训练的权重举证,为偏移项。判断当前所识别的论元是否属于该事件类型,如公式(18)所示:
47、(18)
48、其中,为sigmoid函数,代表句子文本中第个字的向量编码;与为论元角色的权重矩阵和偏置项;每个论元角色会得到一组论元起始位置和终止位置的标注概率序列,对于任意论元的标注概率序列起始位置,终止位置,将任一阈值的字作为触发词的起始位置,将任一阈值的字作为触发词的终止位置,得到该事件的论元角色集合;
49、根据上述操作,基于图注意力网络和二进制标记网络的事件抽取的损失函数如下式(19):
50、(19)
51、其中,rl的含义是预测到的事件论元,代表训练数据集,x代表代表训练集中第x条训练样例,代表当前句子文本事件类型的集合,代表当前句子文本在给定事件类型时的触发词的集合,代表当前句子文本在给定事件类型和事件触发词时的论元角色的集合,其中,,分别对应的公式如下式(20)~(22):
52、(20)
53、(21)
54、(22)
55、其中,代表当前输入句子的长度,代表事件类型的预测概率,代表触发词起始位置的预测概率,代表触发词终止位置的预测概率,代表事件论元起始位置的预测概率,代表事件论元终止位置预测的概率,代表训练数据中事件类型的真实0/1标签,代表训练数据中触发词起始位置的真实0/1标签,代表训练数据中触发词终止位置的真实0/1标签,代表训练数据中事件论元起始位置的真实0/1标签,代表训练数据中事件论元终止位置的真实0/1标签;之后针对损失函数loss使用梯度下降算法在训练集上更新网络参数,保存固定训练轮次中loss最低的模型。
56、将测试句子文本送入训练好的事件抽取联合模型中,输出对应的事件类型信息,事件类型信息包括:事件类型、事件触发词和事件论元。
57、本发明第二实施例提供了一种事件抽取装置,包括:
58、图结构数据构建单元,用于获取句子文本,并将所述句子文本构建成图结构数据;
59、节点向量编码更新单元,用于对所述图结构数据中的每个节点进行初始化向量编码,并基于图注意网络模型对节点向量编码进行更新;
60、事件提取单元,用于调用二进制标记网络对更新后的节点向量编码及句子文本进行事件提取,其中,事件提取包括事件类型识别,事件触发词识别和事件论元识别。
61、本发明第三实施例提供了一种事件抽取设备,包括存储器以及处理器,所述存储器内存储有计算机程序,所述计算机程序能够被所述处理器执行,以实现如上任意一项所述的一种事件抽取方法。
62、本发明第四实施例提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序能够被所述计算机可读存储介质所在设备的处理器执行,以实现如上任意一项所述的一种事件抽取方法。
63、基于本发明提供的一种事件抽取方法、装置、设备及计算机可读存储介质,通过先将所述句子文本构建成图结构数据,接着对所述图结构数据中的每个节点进行初始化向量编码,并基于图注意网络模型对节点向量编码进行更新;调用二进制标记网络对更新后的节点向量编码及句子文本进行事件提取,其中,事件提取包括事件类型识别,事件触发词识别和事件论元识别,可以看出:以依存句法关系为理论基础构建图结果数据,利用命名实体识别技术(ner)为图结构数据融入实体信息,通过图注意力网络学习到句子中元素的相互依赖性。该模型不但可以有效的抽取事件,而且通过二进制标记网络解决了重叠事件问题。
- 还没有人留言评论。精彩留言会获得点赞!