一种基于预设规则的航空事故报告双语检索方法与流程
本发明涉及一种基于预设规则的航空事故报告双语检索方法,具体涉及一种基于深度学习神经网络及自然语言处理相关的航空报告双语检索方法。
背景技术:
1、随着全球航空业的发展,航空文本数据激增,大量航空安全事件的查询方法研究已成为热点问题。美国国家运输安全委员会(national transportation safety board,ntsb)收集了大量航空安全事件,并将过程描述、可能原因、安全建议等调查结果记录在航空事故报告中,是价值丰富的信息检索来源,对识别航空安全隐患、有效预防事故发生、解释事故发生原因和提高应急处理能力具有重要意义。但是ntsb数据库中的航空事故报告全部为英文,对于不擅长英文的相关人员,如何实现为输入的中文查询语句,检索到最相似的英文事故报告,是目前航空业亟待解决的难题。
2、传统的文本跨语言信息检索方法主要借助机器翻译技术,将源语言的查询语句翻译成目标语言的查询语句,然后再在目标语言文档库中检索,返回查询结果。该方法存在以下不足:一是查询效果依赖于翻译质量,翻译误差会严重影响后续的检索性能;二是模型对专业术语的含义理解存在偏差,语义表示不够准确。为了克服传统方法的不足,可以采用跨语言语义表示模型,将查询语句与文档编码成同一语义表示空间的向量,再进行相似度计算。该方法避免了机器翻译误差,提高了检索结果的准确度。nils reimers和irynagurevych提出的sentence-bert跨语言语义表示模型采用孪生网络结构,能够快速计算文本相似度,对工业界具有实用价值。但是,将sentence-bert预训练模型应用于航空领域时需要微调,而目前没有通用的航空领域双语文本相似度数据集,若直接采用ntsb航空数据库文本的全部组合构建数据集,数量级为亿级,过于冗余。因此,本发明设计了一种高效利用庞大数据量、节省计算资源消耗的样本选取方法,微调sentence-bert预训练模型,实现航空事故报告的双语检索。此外,针对概括性较强的航空专业术语,不同于直接输入模型得到向量编码,本发明设计了基于向量相似度的解释句提取算法,通过构建词典得到更准确的语义编码结果。
技术实现思路
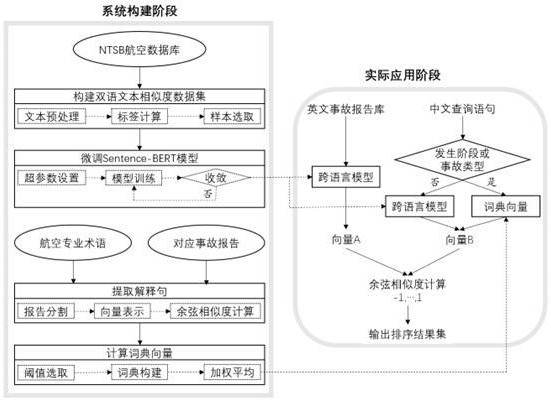
1、为了解决上述问题,本发明提供一种基于预设规则的航空事故报告双语检索方法。对于一般性的查询语句,通过在航空数据集上微调后的sentence-bert模型得到其语义编码向量;当查询语句为发生阶段或事故类型,即概括性较强的航空专业术语时,通过基于向量相似度的解释句提取算法,为其构建词典,进一步得到其语义编码结果。将ntsb数据库中的英文事故报告及用户输入的中文查询语句编码成向量后,使用余弦距离计算二者的相似度,输出与查询语句最相似的10个事故报告,从而实现航空事故报告的双语检索。
2、本发明的技术方案为:本发明提供一种基于预设规则的航空事故报告双语检索方法,方法包括:
3、s1 对ntsb航空数据库的内容进行文本预处理,计算查询语句与事故报告的相似度标签,依照设计的样本选取方法,构建双语文本相似度数据集;
4、s2 使用s1构建的航空数据集微调sentence-bert预训练模型;
5、s3 设计基于向量相似度的解释句提取算法,为航空专业术语构建词典,进一步计算词典向量,得到该术语的语义编码结果;
6、s4 在实际应用阶段,为不同类型的查询语句采取相应的语义编码规则,构建航空事故报告双语检索系统;
7、s5 采用基于包含关系的相关性分数计算方法,建立定量指标,评价该系统的检索效果。
8、s1进一步包括 :
9、s101 取ntsb航空数据库中的英文事故报告作为待查询的内容,将每个事故报告对应的英文短描述句(由发生阶段和事故类型构成)翻译成中文并去重,作为查询语句;
10、s102 对英文事故报告进行文本预处理,包含去除停用词、缩写转全写、分词等步骤;
11、s103 从总计7519条查询语句中,选取200条准确率低和300条频繁出现的查询语句,“准确率低”指的是该语句的预训练模型查询结果的准确率较低,“频繁出现”指的是该查询语句在ntsb数据库中对应的事故报告数量较多;
12、s104 计算上述500条查询语句和全部事故报告的相似度标签;
13、s105 构建航空领域跨语言文本相似度数据集,数据集中每对训练数据包含中文查询语句、英文事故报告和相似度标签。
14、s2进一步包括:
15、s201 将构建好的数据集划分成训练集、验证集、测试集,设置模型最大迭代次数、优化器、初始学习率、批尺寸等超参数;
16、s202 将中文查询语句和英文事故报告输入sentence-bert预训练模型,编码成向量,并计算余弦距离,根据相似度标签计算均方误差损失函数,并根据优化算法进行反向传播,迭代更新网络参数,直到完成设定的最大迭代次数。
17、s3进一步包括:
18、s301 ntsb航空编码手册规定的发生阶段和事故类型均为航空专业术语,从航空数据库中为每个术语取出对应的事故报告;
19、s302 假设航空专业术语a对应的一个事故报告为 bi,将事故报告 bi以句号分割得到句子集合 {c1, c2, … ,cn};
20、s303 用sentence-bert将 a 和 {c1, c2, … ,cn} 分别编码成向量,得到向量o和向量集合 {e1, e2, … ,en};
21、s304 计算航空专业术语与对应事故报告中每句话的向量余弦相似度,即 cos(o,e1), cos(o, e2), ... , cos(o, en). 从而得到该术语的一个解释句向量:, 加入词典中;
22、s305 假设一个术语对应k条事故报告,则该术语的词典(即解释句向量集合)为{si}k, 设置初始阈值为0.1,去掉余弦相似度小于阈值的向量,计算剩下m个向量的softmax加权平均,得到该术语的词典向量为:.
23、其中m为航空专业术语对应的满足阈值条件的解释句个数, o为sentence-bert编码的航空专业术语向量,s为sentence-bert编码的解释句向量,occur_emb为航空专业术语的词典向量表示;
24、s306 设置阈值分别为0.1, 0.2, …, 0.9,重复s305的过程,得到该术语在不同阈值条件下的词典向量,取查询结果定量指标评价最好的一种,作为该术语最终的向量表示。
25、s4进一步包括 :
26、s401 采用在航空数据集上微调后的sentence-bert模型,预先将航空数据库中的所有事故报告编码成向量,并离线存储;
27、s402 在实际应用阶段,对用户实时输入的查询语句进行判断;
28、s403 对于一般性的查询语句,通过微调后的sentence-bert模型得到其语义编码向量;
29、s404 当查询语句为发生阶段或事故类型时,通过词典向量得到其语义编码结果;
30、s405 计算查询语句与所有事故报告的向量余弦相似度,并从高到低排序,输出前10个报告。
31、s5进一步包括 :
32、s501 根据ntsb航空编码手册中的定义,梳理发生阶段和事故类型的包含关系;
33、s502 根据包含关系,计算模型输入的查询语句与模型输出的事故报告之间的相关性分数:.
34、其中counti表示查询语句中发生阶段和事故类型的总个数,counto∈i表示事故报告对应发生阶段和事故类型包含于或等于查询语句中发生阶段和事故类型的个数;
35、s503 采用map和ndcg两个指标,对模型的查询效果进行评价。
36、本发明有如下的有益效果:本发明提供一种双语检索方法,可以为输入的中文查询语句,检索到最相似的英文事故报告,为不擅长英文的相关人员解决了一大难题;实现了快速查询相似航空报告的功能,从而可以借鉴历史事故的发生原因、处理措施和安全建议,对有效预防事故发生、提高应急处理能力和航空安全管理水平具有指导意义。
37、与现有技术相比,本发明具有以下优点:
38、1、无需机器翻译步骤,即可实现双语检索,避免了翻译偏差,提高了检索结果的准确度。
39、2、设计了一种高效利用庞大数据量、节省计算资源消耗的样本选取方法。该方法通过减少查询语句及制定正负样本选取规则,将训练数据量从亿级降为30万左右,从而实现sentence-bert模型在航空领域的微调。微调后模型查询效果的极大提升验证了该方法的有效性。
40、3、设计了一种基于向量相似度的解释句提取算法,直接使用预训练模型为航空专业术语提取相应的解释句,将所有解释句向量的加权平均结果作为该术语的向量表示,得到更准确的语义编码结果。该方法不仅可以提升航空专业术语的查询效果,而且提供了一种无需花费时间微调、快速提高预训练模型应用效果的新思路。
41、4、构建了基于预设规则的航空事故报告双语检索系统,为不同类型的查询语句选取相应的语义编码规则。定量指标评价结果表明了该检索系统的有效性。
- 还没有人留言评论。精彩留言会获得点赞!