智能体探索策略的确定方法、装置、智能体及存储介质
本公开涉及强化学习与智能体进化策略,尤其涉及一种智能体探索策略的确定方法、装置、智能体及存储介质。
背景技术:
1、随着深度强化学习算法在各个领域的发展,智能体能够从原始感觉数据获得复杂的操纵和运动技能,例如用原始像素输入玩雅达利游戏,掌握围棋游戏等。但是,这些深度强化学习算法在具有稀疏或延迟奖励、大状态空间和欺骗性局部优化的任务中存在表现不佳的问题,针对大规模稀疏奖励的问题。相关技术中,为了鼓励智能体在环境中进行充分的探索,会在策略网络输出的行动中加入从高斯分布或ornstein-unlenbeck过程等随机分布中采样的噪声,鼓励智能体访问其很少或从未访问过的状态,以便引导智能体进入未知区域;或者使用最大熵方法在现有状态下采取新的行动,允许智能体在给定状态下通过鼓励行动的高熵分布更好地探索环境。但是,相关技术中的方法在具有欺骗性或稀少的奖励的探索任务中可能会导致次优行为,因此没有取得令人满意的结果。
技术实现思路
1、为克服相关技术中存在的问题,本公开提供一种智能体探索策略的确定方法、装置、智能体及存储介质。
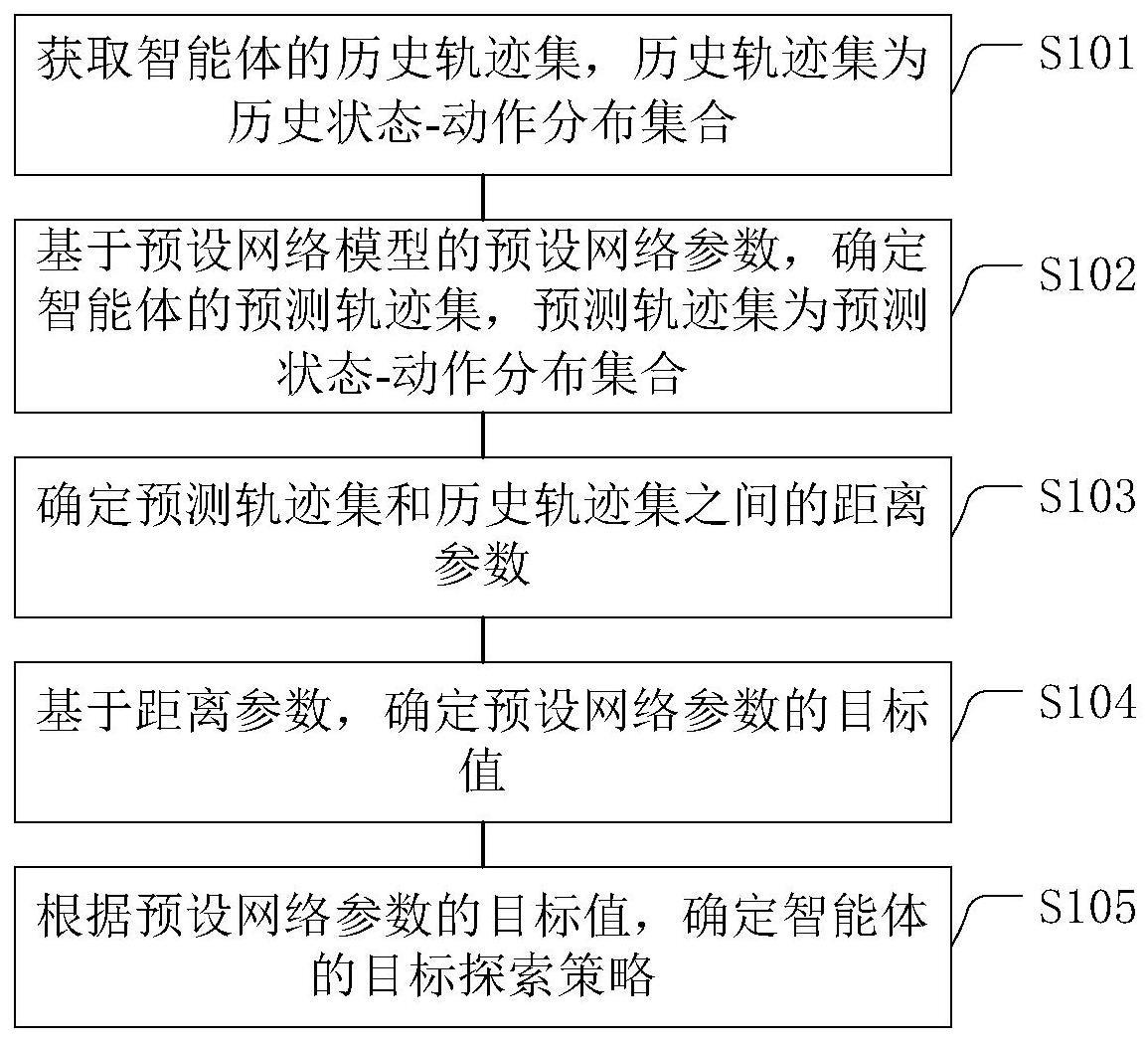
2、根据本公开实施例的第一方面,提供一种智能体探索策略的确定方法,所述探索策略包括基于预设网络模型的探索策略,所述确定方法包括:
3、获取所述智能体的历史轨迹集,所述历史轨迹集为历史状态-动作分布集合;
4、基于所述预设网络模型的预设网络参数,确定所述智能体的预测轨迹集,所述预测轨迹集为预测状态-动作分布集合;
5、确定所述预测轨迹集和所述历史轨迹集之间的距离参数;
6、基于所述距离参数,确定所述预设网络参数的目标值;
7、根据所述预设网络参数的目标值,确定所述智能体的目标探索策略。
8、在一示例性实施例中,所述基于所述距离参数,确定所述预设网络参数的目标值,包括:
9、根据所述距离参数和所述预设网络模型的奖励函数,确定所述预设网络模型的目标函数;所述目标函数和所述奖励函数均为基于所述预设网络参数的函数;
10、将所述目标函数的取值为最大值时所述预设网络参数的取值确定为所述预设网络参数的目标值。
11、在一示例性实施例中,所述根据所述距离参数和所述预设网络模型的奖励函数,确定所述预设网络模型的目标函数,包括:
12、通过以下公式确定所述目标函数:
13、
14、其中,θ表示所述预设网络参数,l(θ)表示所述目标函数,表示所述奖励函数,ρπ表示所述预测状态-动作分布,ρμ表示所述历史状态-动作分布,dmmd(ρπ,ρμ)表示所述距离参数,α表示权重。
15、在一示例性实施例中,所述将所述目标函数的取值为最大值时所述预设网络参数的取值确定为所述预设网络参数的目标值,包括:
16、计算所述目标函数的梯度;
17、基于梯度估计算法,确定所述目标函数的取值为最大值时所述预设网络参数的取值。
18、在一示例性实施例中,所述基于所述预设网络模型的预设网络参数,确定所述智能体的预测轨迹集,包括:
19、对所述预设网络参数进行多次采样,得到所述预设网络参数的多个采样值;
20、将所述预设网络参数的多个采样值输入预设网络模型中,得到所述预测轨迹集。
21、在一示例性实施例中,所述对所述预设网络参数进行多次采样,得到所述预设网络参数的采样值,包括:
22、基于正态分布进行采样:
23、
24、其中,表示所述正态分布,σ表示所述正态分布的标准差,i表示单位矩阵,σ2i表示所述正态分布的协方差矩阵,n表示采样的次数,∈i表示第i次采样值;
25、通过以下公式确定所述预设网络参数的采样值:
26、θi=θ+∈i
27、其中,θi表示第i次采样所述预设网络参数的采样值,θ表示所述预设网络参数。
28、在一示例性实施例中,所述确定所述预测轨迹集和所述历史轨迹集之间的距离参数,包括:
29、确定所述预测轨迹集的每个所述预测状态-动作分布和所述历史轨迹集之间的距离参数。
30、根据本公开实施例的第二方面,提供一种智能体探索策略的确定装置,所述探索策略包括基于预设网络模型的探索策略,所述确定装置包括:
31、获取模块,被配置为获取所述智能体的历史轨迹集,所述历史轨迹集包括历史状态-动作分布集合;
32、第一确定模块,被配置为基于所述预设网络模型的预设网络参数,确定所述智能体的预测轨迹集,所述预测轨迹集包括预测状态-动作分布集合;
33、第二确定模块,被配置为确定所述预测轨迹集和所述历史轨迹集之间的距离参数;
34、第三确定模块,被配置为基于所述距离参数,确定所述预设网络参数的目标值;
35、第四确定模块,被配置为根据所述预设网络参数的目标值,确定所述智能体的目标探索策略。
36、在一示例性实施例中,所述第三确定模块还被配置为:
37、根据所述距离参数和所述预设网络模型的奖励函数,确定所述预设网络模型的目标函数;所述目标函数和所述奖励函数均为基于所述预设网络参数的函数;
38、将所述目标函数的取值为最大值时所述预设网络参数的取值确定为所述预设网络参数的目标值。
39、在一示例性实施例中,所述第三确定模块还被配置为:
40、通过以下公式确定所述目标函数:
41、
42、其中,θ表示所述预设网络参数,l(θ)表示所述目标函数,表示所述奖励函数,ρπ表示所述预测状态-动作分布,ρμ表示所述历史状态-动作分布,dmmd(ρπ,ρμ)表示所述距离参数,α表示权重。
43、在一示例性实施例中,所述第三确定模块还被配置为:
44、计算所述目标函数的梯度;
45、基于梯度估计算法,确定所述目标函数的取值为最大值时所述预设网络参数的取值。
46、在一示例性实施例中,所述第一确定模块还被配置为:
47、对所述预设网络参数进行多次采样,得到所述预设网络参数的多个采样值;
48、将所述预设网络参数的多个采样值输入预设网络模型中,得到所述预测轨迹集。
49、在一示例性实施例中,所述第一确定模块还被配置为:
50、基于正态分布进行采样:
51、
52、其中,表示所述正态分布,σ表示所述正态分布的标准差,i表示单位矩阵,σ2i表示所述正态分布的协方差矩阵,n表示采样的次数,∈i表示第i次采样值;
53、通过以下公式确定所述预设网络参数的采样值:
54、θi=θ+∈i
55、其中,θi表示第i次采样所述预设网络参数的采样值,θ表示所述预设网络参数。
56、在一示例性实施例中,所述第二确定模块还被配置为:
57、确定所述预测轨迹集的每个所述预测状态-动作分布和所述历史轨迹集之间的距离参数。
58、根据本公开实施例的第三方面,提供一种智能体,包括:
59、处理器;
60、用于存储处理器可执行指令的存储器;
61、其中,所述处理器被配置为执行如本公开实施例的第一方面中任一项所述的方法。
62、根据本公开实施例的第四方面,提供一种非临时性计算机可读存储介质,当所述存储介质中的指令由智能体的处理器执行时,使得智能体能够执行如本公开实施例的第一方面中任一项所述的方法。
63、采用本公开的上述方法,具有以下有益效果:本公开中通过预测轨迹集和历史轨迹集之间的距离参数来确定预设网络参数,能够使智能体探索更多未知区域,从而使智能体摆脱局部最优策略,学习到全局最优策略,极大程度提高智能体对新轨迹的探索能力。
64、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!