融合通道特征和空间特征的图像复原方法、系统及终端
本发明属于图像去雨,尤其涉及一种融合通道特征和空间特征的图像复原方法、系统及终端。
背景技术:
1、目前,图像去雨技术主要是针对成像过程中的“退化”而提出,图像退化的过程可以表示为:
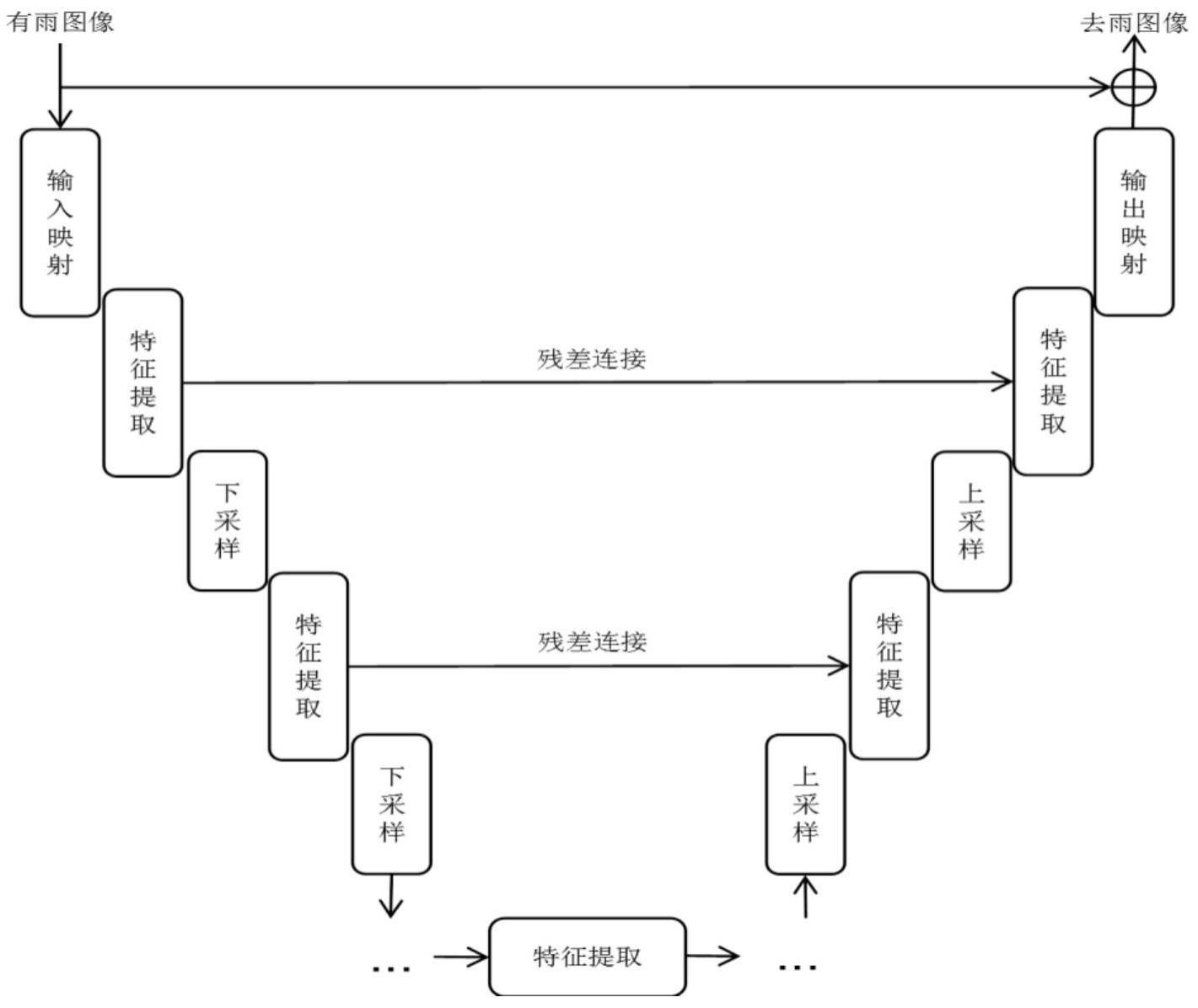
2、g(x,y)=t(f(x,y))+n(x,y)
3、其中,g(x,y)为退化的图像,f(x,y)为原始理想图像,t为图像退化函数,n(x,y)为噪声。而图像复原模型就是通过对退化函数以及噪声的估计来恢复出原图像,图6展示的就是通用的图像复原模型的思路。
4、随着transformer自注意力机制被从nlp移植到计算机视觉领域,通用图像复原方法也越来越多地成功应用了transformer,基于transformer的通用图像复原方法可大致分为基于unet架构的和基于滑动窗口机制的。对于unet架构的方法,2021年的图像复原方法uformer成功的在unet架构中融合了transformer方法,uformer同时也将经典的transformer的全局自注意力模型改变为滑动窗口内的局部自注意力模型,大大减小计算量,同时在不同尺度的特征图上获取到了不同大小的感受野,在多个图像复原任务中达到了sota表现。2022年的图像复原方法restormer设计了一种通道方向的自注意力模块,并配合以一个使网络集中于有效信息的前馈神经网络模块,模型在去雨、去模糊、去噪等多个图像复原任务上取得世界前列的水平。对于基于滑动窗口机制的方法,uformer、swinir都运用了图像上的滑动窗口内局部自注意力机制并且性能超越传统的基于深度卷积网络的方法,swinir继承改进了swin transformer里的transformer模块,将其组织成transformer层并配合以残差连接,达到非常好的通用图像复原效果。2021年的方法etdnet设计了一种新的自注意力去雨网络架构,新的自注意力去雨网络架构能够提供更丰富的多尺度特征以及上下文信息。
5、现有的基于transformer的图像复原网络最大的两个问题就是:第一,因为全局计算的特点导致在大尺寸的特征图上计算量惊人;第二,由于全局均质化的操作导致低层的局部信息容易丢失。利用滑动窗口机制能够有效的减小transformer的计算量。假设输入的特征图尺寸是c×w×h,则transformer的时间复杂度是o(cw2h2),而使用了不重叠滑动窗口内的局部transformer之后,时间复杂度降低到了o(m2hwc)。而且局部transformer比起全局的transformer也能更好的提取和传递局部特征。
6、前面也列举过很多成功运用滑动窗口局部自注意力机制的图像复原方法,它们通常也有较低的时间复杂度和较好的局部特征提取能力,但是它们有时会被特征图某些通道中的冗余信息影响,甚至特征图中可能会有对损失函数收敛无效的冗余通道,最终导致有效通道的信息被稀释。这个问题产生的原因就是基于滑动窗口的自注意力机制虽然对特征图空间方向上的每个部分进行了差异化处理,解决了局部信息丢失的问题,但是它对通道方向上的信息没有做差异化处理,每个通道无论对损失收敛效度如何都被均质化对待了。
7、通过上述分析,现有技术存在的问题及缺陷为:
8、(1)现有基于transformer的图像复原网络由于全局计算特点导致在大尺寸特征图上计算量非常大,且由于全局均质化操作导致低层局部信息容易丢失。
9、(2)现有基于滑动窗口的自注意力机制由于对通道方向上的信息没有做差异化处理,导致每个通道无论对损失收敛效度如何都被均质化对待。
10、(3)现有运用滑动窗口局部自注意力机制的图像复原方法会被特征图通道的冗余信息或对损失函数收敛无效的冗余通道影响,导致有效通道信息被稀释。
技术实现思路
1、针对现有技术存在的问题,本发明提供了一种融合通道特征和空间特征的图像复原方法、系统及终端,尤其涉及一种基于融合通道特征和空间特征的去雨网络的图像复原方法、系统、介质、设备及终端。
2、本发明是这样实现的,一种融合通道特征和空间特征的图像复原方法,包括:构建融合空间特征和通道特征的自注意力网络urformer;利用urformer网络中的特征提取模块,将局部自注意力机制和通道自注意力机制进行结合,提取并保留通道和空间特征。
3、进一步,融合通道特征和空间特征的图像复原方法包括以下步骤:
4、步骤一,构建图像复原模型;将有雨图像和gt图像经过输入映射层完成低层特征提取和特征嵌入,得到准备输入模型的特征张量;
5、步骤二,特征张量连续通过k个编码器层得到二维特征向量并进行下采样,将在最后一层编码器得到的特征向量作为解码器第1层的输入;
6、步骤三,经过k个解码器层后,图像复原模型将最终得到的特征图按通道方向展平为二维特征向量并通过卷积层,得到残差图像;
7、步骤四,在训练迭代输出前将原图直连到残差图像,位于网络顶层的残差直连将残差图像与退化图像相加,得到模型恢复的目标图像。
8、进一步,步骤一中的图像复原模型采用unet结构,整体呈现为分级网络,编码器和解码器的对应级别层由残差直连。
9、给定一张有雨图像i∈r3×h×w和一张gt图像i经过输入映射层,输入映射层实质是3×3的卷积层加上relu激活函数,其中卷积核的个数embed_dim决定正式输入模型的张量的通道数,embed_dim设置为全局超参。输入映射层对i完成低层特征提取和特征嵌入得到准备输入模型的特征张量x0∈rembed_dim×h×w:
10、x0=inputproj(i)。
11、进一步,步骤二中,x0连续通过k个编码器层,在第i个编码器层,上一层输出的xi-1经过多个urformer特征提取模块得到
12、
13、图像复原模型将按通道展平成一个二维的特征向量,再送进下采样层中进行下采样;下采样后将得到的特征图通过一个4×4且步长为2的卷积操作翻倍通道数,最终得到
14、
15、记原始输入urformer特征提取模块的特征图为m,则m经过归一化层norm1,再进入wcst;wcst输出的特征图再通过第一个残差跳连与原始输入的m相加后得到
16、
17、经过第二个归一化层norm2,再进入gdfn;gdfn输出的特征图再通过第二个残差跳连与相加后就得到urformer特征提取模块最终输出的特征图
18、
19、urformer特征提取模块还包括w-cst模块,输入一张特征图y∈rc×h×w,w-cst将y按照窗口大小m×m切割成n个互不重叠的小块,其中的第i块记为yi∈rc×m×m:
20、y={y1,y2,…,yi,…,yn},n=hw/m2;
21、每个小块上开始通道自注意力的计算,在第i块yi∈rc×m×m,yi被复制出三份,对三份分别进行一次1×1的卷积操作,聚合跨通道的像素级上下文信息,得到的三份新的特征图再分别经过一个3×3的深度卷积层,从而获得通道自注意力的q,k和v:
22、
23、将q,k,v均按通道展平为二维向量,展开时q,k行列顺序相反以便产生通道方向的自注意力概率得分图:进行通道自注意力的计算:
24、
25、
26、其中,ɑ为可学习的参数,用于放大系数;计算得出的特征张量再变形回原来c个通道的形状,得到的特征图记为再经过一个1×1卷积就最终得到第i个窗口内,原特征图y的第i个小块上的通道自注意力输出
27、
28、在滑动窗口遍历完特征图y并完成每个窗口内的通道自注意力计算后模型将窗口的信息根据各自原本的位置进行拼接融合,得到w-cst最终的输出:
29、
30、进一步,步骤三中,xi被第i个编码器层输出后准备作为第i+1个编码器的输入。在最后一层编码器之后是一个瓶颈层,得到的特征向量作为解码器第1层的输入。根据unet架构,解码器包括k层,并将每一层输入的张量与编码器中对应层输出的张量拼接后再输入解码层。在解码器第k-i+1层,对应的编码器层是第i个编码器层,输入解码器第k-i+1层的张量记为则输出为:
31、
32、进一步,步骤四中,经过k个解码器层后,模型将最终得到的特征图按通道方向展平为二维特征向量并通过一个3×3卷积层,得到残差图像r∈r3×h×w。位于网络顶层的残差直连将残差图像与退化图像i相加得到模型恢复的目标图像并在一次训练迭代输出前将原图直连到残差图像:
33、
34、图像复原模型urformer是有监督的深度学习网络,在训练urformer时损失函数选择使用charbonnier损失函数监督模型的训练;
35、
36、其中,ε=10-3在实验中是常数。
37、本发明的另一目的在于提供一种应用所述的融合通道特征和空间特征的图像复原方法的融合通道特征和空间特征的图像复原系统,融合通道特征和空间特征的图像复原系统包括:
38、特征提取模块,用于构建图像复原模型;将有雨图像和gt图像经过输入映射层完成低层特征提取和特征嵌入,得到准备输入模型的特征张量;
39、图像编码模块,用于将特征张量连续通过k个编码器层得到二维特征向量并进行下采样,将在最后一层编码器得到的特征向量作为解码器第1层的输入;
40、图像解码模块,用于经过k个解码器层后,图像复原模型将最终得到的特征图按通道方向展平为二维特征向量并通过卷积层,得到残差图像;
41、图像复原模块,用于在训练迭代输出前将原图直连到残差图像,位于网络顶层的残差直连将残差图像与退化图像相加,得到模型恢复的目标图像。
42、本发明的另一目的在于提供一种计算机设备,计算机设备包括存储器和处理器,存储器存储有计算机程序,计算机程序被处理器执行时,使得处理器执行所述的融合通道特征和空间特征的图像复原方法的步骤。
43、本发明的另一目的在于提供一种计算机可读存储介质,存储有计算机程序,计算机程序被处理器执行时,使得处理器执行所述的融合通道特征和空间特征的图像复原方法的步骤。
44、本发明的另一目的在于提供一种信息数据处理终端,信息数据处理终端用于实现所述的融合通道特征和空间特征的图像复原系统。
45、结合上述的技术方案和解决的技术问题,本发明所要保护的技术方案所具备的优点及积极效果为:
46、第一,针对上述现有技术存在的技术问题以及解决该问题的难度,紧密结合本发明的所要保护的技术方案以及研发过程中结果和数据等,详细、深刻地分析本发明技术方案如何解决的技术问题,解决问题之后带来的一些具备创造性的技术效果。具体描述如下:
47、为了解决transformer去雨网络中存在两个主要缺点:一、容易丢失局部特征和通道特征,二、计算量偏大,本发明设计了一种融合空间特征和通道特征的自注意力网络——urformer。该网络提出了一个新的特征提取模块,将局部自注意力机制和通道自注意力机制有效结合。本发明提供的urformer网络在提取并保留通道和空间特征的同时,大幅降低了传统全局transformer的计算量。经验证,本发明的urformer网络在rgb图像去雨任务上表现出优良的性能。
48、经实验证明本发明提出的urformer网络成功按照理论预期地达到了研究目标。在本发明的进行过程中,urformer的诸多优点也被逐步发现和认知:
49、(1)计算量较小:根据wcst模块的原理,局部transformer操作能够有效减少transformer的计算量,另外,在通道数不是特别多的情况下,如embed_dim<32的情形下,通道自注意力机制也比空间自注意力机制能节省计算量。计算量测量实验也验证了urformer计算量较小这一优势。
50、(2)性能好:实验验证了urformer在图像去雨上能达到了一流的性能。
51、(3)端到端(end-to-end):urformer是一个端到端的网络,原始的rgb图像可以直接输入模型无需专门的预处理步骤,输出出来的rgb图像则就是所要求的还原以后的图像,可以直接使用。这使得模型可以随用随插,应用落地也更方便容易。
52、第二,把技术方案看做一个整体或者从产品的角度,本发明所要保护的技术方案具备的技术效果和优点,具体描述如下:
53、本发明提出了一种全新的去雨网络,以远低于同类方法的计算开销,表现出优良的性能。本发明提供的urformer网络具有以下特点:1)使用unet框架,设计了基于与transformer的特征提取模块;2)滑动窗口下的操作大幅降低了计算复杂度;3)在提取空间特征的同时,能够兼顾通道特征的提取。
54、第三,作为本发明的权利要求的创造性辅助证据,还体现在以下几个重要方面:
55、本发明的技术方案填补了国内外业内技术空白:
56、目前业界已有的图像复原技术,尚无以较低计算复杂度,实现优良效果的方法。传统的图像处理方法,需要针对具体的数据进行人工处理,泛化性不好,效果也不佳,费时费力。基于深度神经网络的方法,能够做到一定的通用性,同时能够大幅提升效果,但是(1)计算复杂度太高,(2)泛化性太差,无法落地应用。本方法在已有的基于深度神经网络的方法之上,设计了全新的网络结构,解决了上述两点,使得应用落地更加简单。
- 还没有人留言评论。精彩留言会获得点赞!