小样本学习的对非结构化招标文本智能审核方法及系统与流程
本发明涉及计算机,具体地,涉及一种基于小样本学习的对非结构化招标文本智能审核方法及系统。
背景技术:
1、目前合同文本审核主要针对于固定模板的合同,通过利用动态规划、相似度计算等方式来验证合同的合规性,判断所签署合同是否通过审核,提高审核效率。
2、专利文献cn114842493a(申请号cn202210449692.)公开了一种合同审核方法、合同审核系统和可读存储介质,该发明通过计算合同模板与签署合同的相似度,利用预设的阈值来判断合同是否合规,但无法解决本文所提及的招标文本描述多样、差异大的问题。
3、专利文献cn115688736a(申请号:cn202211344167.0)公开了一种文档审核方法、装置、设备及存储介质,其中,文档审核方法包括:获取待审核文档,作为目标文档;从文档库中查找目标文档的审核参考文档;若查找到目标文档的审核参考文档,则参考目标文档的审核参考文档对目标文档进行审核;若未查找到目标文档的审核参考文档,则从目标文档中抽取要素,并对抽取的要素进行审核。但该发明没有针对合同,无法动态判断合同是否通过审核。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种小样本学习的对非结构化招标文本智能审核方法及系统。
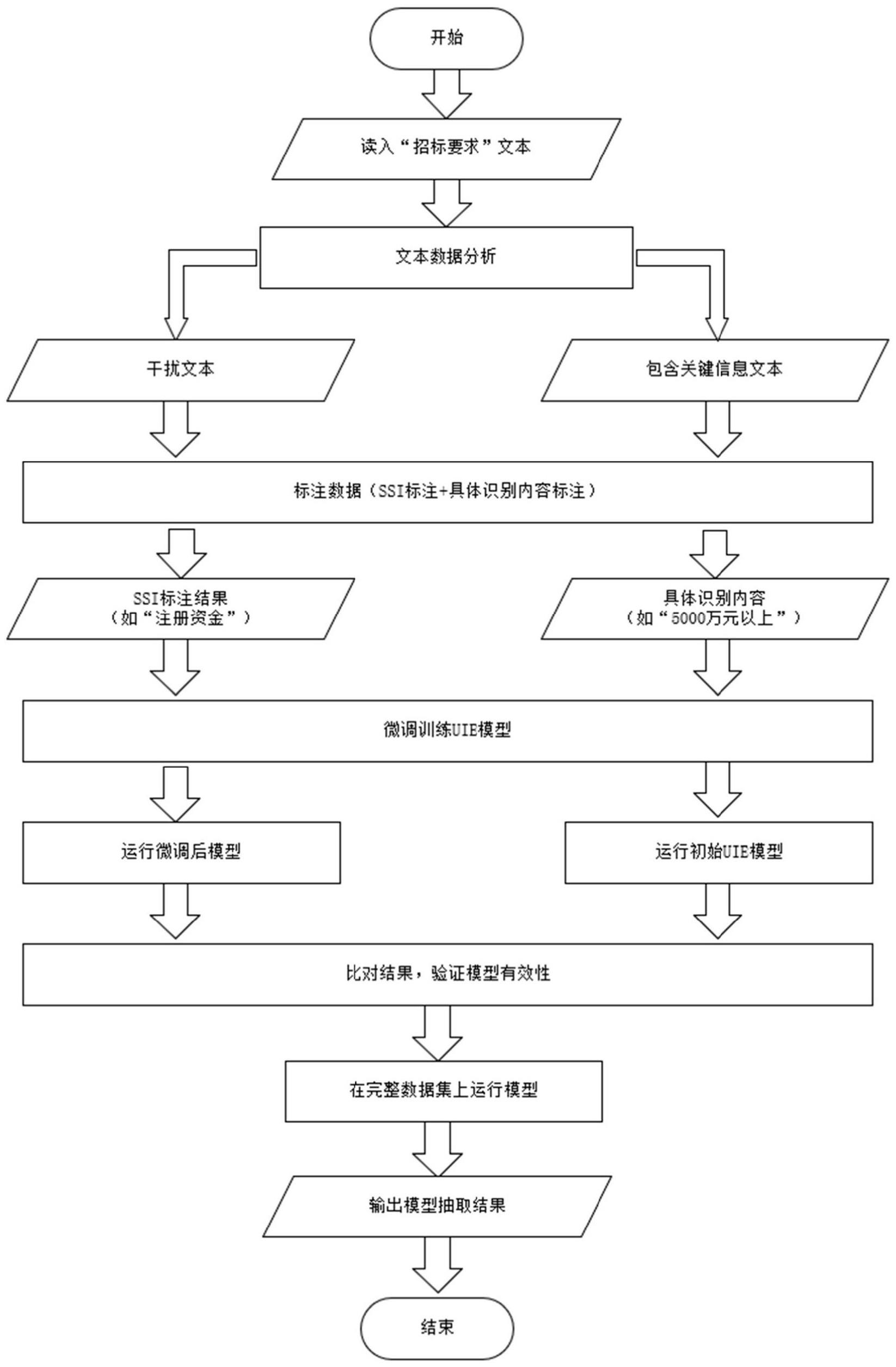
2、根据本发明提供的一种小样本学习的对非结构化招标文本智能审核方法,包括:
3、步骤s1:分析及标注文本数据;
4、步骤s2:对标注后的文本数据抽取模型进行调整;
5、步骤s3:通过测试数据进行对比试验证明模型有效性;
6、步骤s4:利用构建好的模型完成对文本的审核。
7、优选地,在所述步骤s1中:
8、步骤s1.1:对已有文本数据进行数据分析,将读取到的文本数据,进行数据清洗,包括将空白符号和非法字符去除;
9、步骤s1.2:将存在干扰但无标签的文本保留作为负样本,文本的标注形式为ssi和text标记的源文本拼接构成;
10、ssi由spot标记发现对象,指示需要进行抽取任务的实体或触发词,由asso标记关系种类。
11、优选地,在所述步骤s2中:
12、步骤s2.1:将ssi和源文本作为输入,利用encoder编码器获取ssi和输入源文本的隐藏层表示:
13、h=encoder(s1,s2,…,s|s|,x1,x2,…,x|x|)
14、其中,s为结构模式指导器ssi,s1,s2,s3,...s|s|为该任务下所有的结构模式,|s|为总的结构模式数目;x表示待识别文本,x1,x2,x3,...x|x|其中文本所包含的子句,|x|为总的文本子句数目;
15、步骤s2.2:uie模型将信息抽取子任务建模为文本生成任务,并利用解码器完成,给定文本表示的特征向量h,编码器decoder以自回归的形式生成sely:
16、y=[y1,y2,…,y|y|]
17、
18、其中,sel为模型的输出形式,sel以结构化文本的方式表述了需要模型抽取的所有spot对象和asso对象,其中y为转化为用于提取信息记录的sel序列,yi为sel序列中在解码的步骤i下生成的第i个令牌;为解码步骤i下对应的解码器状态。
19、优选地,利用teaching-forcing交叉熵作为损失函数,利用监督数据调整已经预训练好的uie模型:
20、
21、其中,为损失函数,p指代概率,θe,θd分别为编码器和解码器的参数,y为sel序列中的令牌。
22、优选地,在所述步骤s3中:
23、通过测试集数据将未调整的模型与调整过的模型基于预设指标进行比较,当调整后的模型在预设指标提升至预设标准,模型调整具备有效性;
24、在所述步骤s4中:
25、将合同内容输入至模型中,自动获取文中描述的注册资金及支付方式,用于核验。
26、根据本发明提供的一种小样本学习的对非结构化招标文本智能审核系统,包括:
27、模块m1:分析及标注文本数据;
28、模块m2:对标注后的文本数据抽取模型进行调整;
29、模块m3:通过测试数据进行对比试验证明模型有效性;
30、模块m4:利用构建好的模型完成对文本的审核。
31、优选地,在所述模块m1中:
32、模块m1.1:对已有文本数据进行数据分析,将读取到的文本数据,进行数据清洗,包括将空白符号和非法字符去除;
33、模块m1.2:将存在干扰但无标签的文本保留作为负样本,文本的标注形式为ssi和text标记的源文本拼接构成;
34、ssi由spot标记发现对象,指示需要进行抽取任务的实体或触发词,由asso标记关系种类。
35、优选地,在所述模块m2中:
36、模块m2.1:将ssi和源文本作为输入,利用encoder编码器获取ssi和输入源文本的隐藏层表示:
37、h=encoder(s1,s2,…,s|s|,x1,x2,…,x|x|)
38、其中,s为结构模式指导器ssi,s1,s2,s3,...s|s|为该任务下所有的结构模式,|s|为总的结构模式数目;x表示待识别文本,x1,x2,x3,...x|x|其中文本所包含的子句,|x|为总的文本子句数目;
39、模块m2.2:uie模型将信息抽取子任务建模为文本生成任务,并利用解码器完成,给定文本表示的特征向量h,编码器decoder以自回归的形式生成sely:
40、y=[y1,y2,…,y|y|]
41、
42、其中,sel为模型的输出形式,sel以结构化文本的方式表述了需要模型抽取的所有spot对象和asso对象,其中y为转化为用于提取信息记录的sel序列,yi为sel序列中在解码的步骤i下生成的第i个令牌;为解码步骤i下对应的解码器状态。
43、优选地,利用teaching-forcing交叉熵作为损失函数,利用监督数据调整已经预训练好的uie模型:
44、
45、其中,为损失函数,p指代概率,θe,θd分别为编码器和解码器的参数,y为sel序列中的令牌。
46、优选地,在所述模块m3中:
47、通过测试集数据将未调整的模型与调整过的模型基于预设指标进行比较,当调整后的模型在预设指标提升至预设标准,模型调整具备有效性;
48、在所述模块m4中:
49、将合同内容输入至模型中,自动获取文中描述的注册资金及支付方式,用于核验。
50、与现有技术相比,本发明具有如下的有益效果:
51、1、本发明通过使用小样本学习的方法,对训练模型微调,不仅提升了模型的信息的抽取能力,也避免了人力标注数据成本过高的问题;
52、2、本发明通过使用微调后的预训练模型,使得模型在本文应对的非结构化招标文本方面有很好的表现;
53、3、本发明的模型本身应用于信息抽取领域,在通用领域方面可直接应用,但对于合同审核此垂直领域,所对应的具体实体、关系又有所不同,无法直接使用,需要进行微调,使其更适合于合同领域,并保留了其本身的泛化能力,使得模型在面对新的招标文本上也有很好的表现。
- 还没有人留言评论。精彩留言会获得点赞!