一种基于全局训练空间的情感分析方法
本发明涉及自然语言处理,具体包括一种基于全局训练空间的情感分析方法。
背景技术:
1、文本情感分析,又称为观点挖掘(opinion mining),可以按分析粒度分为篇章级情感分析、句子级情感分析和方面级情感分析。
2、在基于方面的情感分析中,面向目标的意见词提取(towe)旨在根据方面术语提取相应的意见词。以往的研究在towe任务的建模过程中忽略了隐式方面,只关注显式方面。
3、面向目标的意见词提取是细粒度情感分析的一个子任务。在这项任务中,给定特定的方面术语和与其相关的上下文,towe任务旨在提取与特定方面相关的意见词,但问题在于,towe有两种类型的训练样本。在显式方面中,方面术语与至少一个意见词相关联,而在隐式方面中,方面术语没有相应的意见词。以前的研究只用显式方面来训练和评估他们的模型,导致了样本选择偏差的问题。具体来说,以往的towe模型只用显式方面进行训练,而这些模型将被用来对全局空间的显式方面和隐式方面进行推理。因此,泛化性能将受到伤害。
4、其次,现有技术还存在一些缺陷,第一是由于非正式文本通常较短,有的句子无法有效提取出适合的方面术语(即目标)和意见表达(意见词),所以这类句子是需要进行清理的。第二是非正式文本当中有许多非正式语言以及社交媒体给定的标签,这类噪声会对词法与句法分析产生较大的干扰,所以需要将非正式文本恢复为自然语言。第三是由于在一个句子中的意见表达是针对于该句子中的方面术语,所以需要通过定义相关的相似度计算公式来刻画词语与词语之间的关联程度。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于全局训练空间的情感分析方法解决了现有技术存在样本选择偏差、泛化性能差、缺乏对非正式文本的处理的问题。
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于全局训练空间的情感分析方法,包括以下步骤:
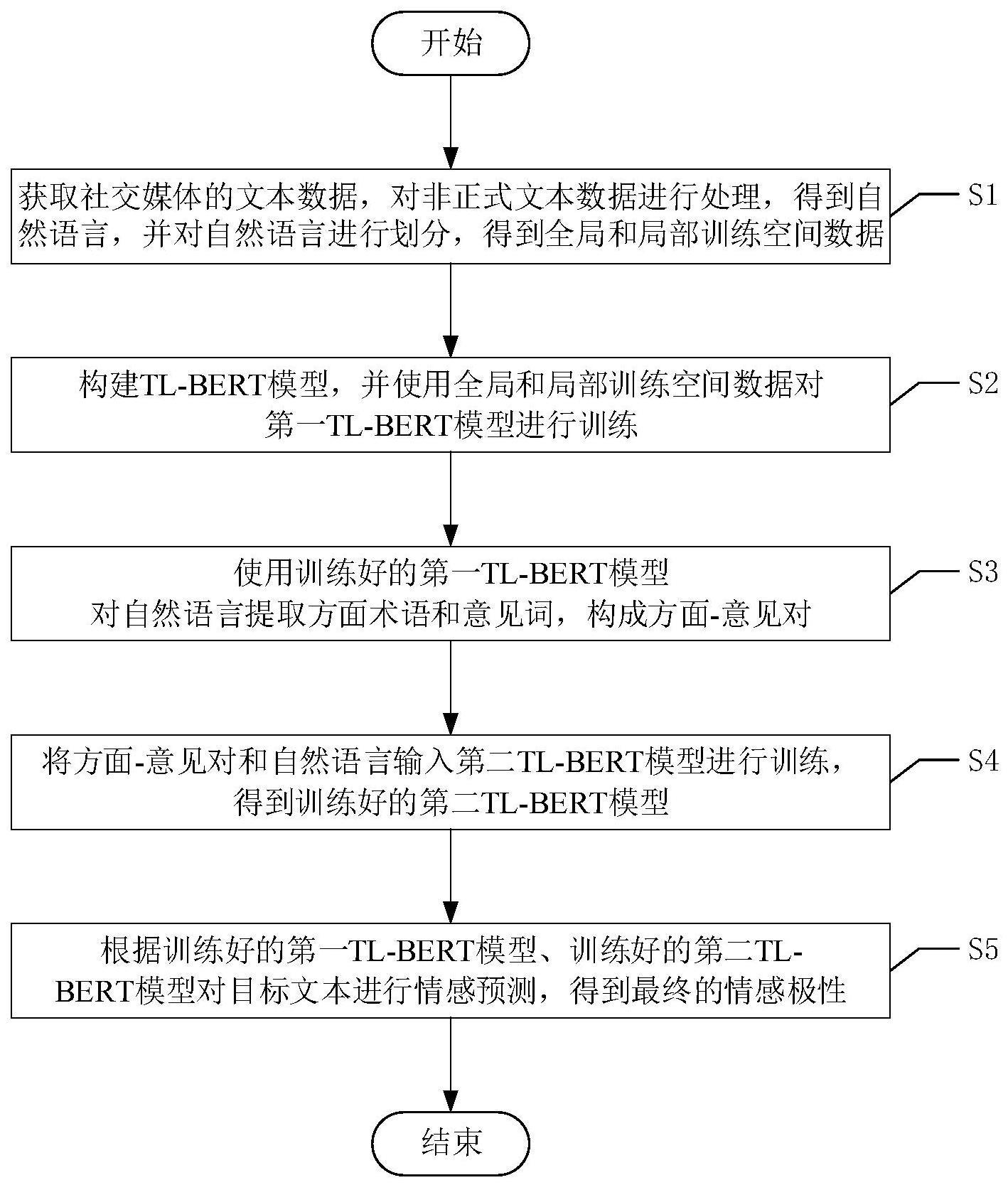
3、s1、获取社交媒体的文本数据,对非正式文本数据进行处理,得到自然语言,并对自然语言进行划分,得到全局和局部训练空间数据;
4、s2、构建tl-bert模型,并使用全局和局部训练空间数据对第一tl-bert模型进行训练;
5、s3、使用训练好的第一tl-bert模型对自然语言提取方面术语和意见词,构成方面-意见对;
6、s4、将方面-意见对和自然语言输入第二tl-bert模型进行训练,得到训练好的第二tl-bert模型;
7、s5、根据训练好的第一tl-bert模型、训练好的第二tl-bert模型对目标文本进行情感预测,得到最终的情感极性。
8、进一步地,步骤s1的具体实现方式如下:
9、s1-1、获取社交媒体的文本数据,提取文本数据中的非正式文本数据,记作t1,t2,t3,...,ti,...,tn;
10、s1-2、清除掉非正式文本数据中社交媒体为文本添加的内容,得到第一次清理后的数据;包括用户名链接(比如“@username”),回复的内容(比如“回复@username”);
11、s1-3、对第一次清理后的数据清理掉emoji、emoticon和非英文内容,得到第二次清理后的数据;
12、s1-4、将第二次清理后的数据中社交媒体中的话题标签替换为原本的文字,得到第三次清理后的数据;
13、s1-5、对第三次清理后的数据进行以“。”、“.”、“!”、“!”、“?”、“?”为标准的切割,得到自然语言;
14、s1-6、对自然语言标注显式方面和隐式方面的训练样本;
15、s1-7、对自然语言划分全局和局部训练空间数据,即进行全局空间训练集划分、全局空间验证测试集划分、局部空间训练集划分、局部空间验证测试集划分。
16、进一步地,tl-bert模型包括bert-base层、多头注意力层、长短期记忆网络和解码器;bert-base层的输出端连接多头注意力层的输入端;多头注意力层的输出端连接长短期记忆网络的输入端;长短期记忆网络的输出端连接解码器的输入端。
17、进一步地,步骤s2的具体实现方式如下:
18、s2-1、将全局和局部训练空间数据中的句子s转化为新的句子sb={w0,...,wi,...,wq};其中,w0为字符“[cls]”;wi、wq均为字符“[sep]”;
19、s2-2、为新的句子生成段索引is={0,...,0}和位置索引ip={0,...,q},其中,q表示新的句子共有q个词;
20、s2-3、将新的句子sb、新句子的段索引is和新句子的位置索引ip输入第一tl-bert模型,对第一tl-bert模型进行训练,得到训练好的第一tl-bert模型。
21、进一步地,步骤s2-3的具体实现方式如下:
22、s2-3-1、将新的句子sb、新句子的段索引is和新句子的位置索引ip输入bert-base层,获取新的句子sb中每个词的词向量,并将词向量组合成对应的句向量e;
23、s2-3-2、根据公式:
24、q=wq*e
25、k=wk*e
26、v=wv*e
27、得到查询向量q、键值对向量k和v;其中,e表示句向量;wq为权重矩阵;wk为权重矩阵;wv为权重矩阵;q、k、v∈rm×d,其中d是神经网络中隐藏单元的数量,m是序列长度;r为矩阵,意思就是q、k、v这三个向量其实是一个矩阵,r这个矩阵是m行n列。
28、s2-3-3、将查询向量q、键值对向量k和v输入多头注意力层,根据公式:
29、
30、得到多头注意力层第i个头的注意力向量mai;其中,softmax表示激活函数,softmax将注意力向量mai的值输出为[0,1];qi为多头注意力层第i个头的查询向量;ki为多头注意力层第i个头的键值;vi为多头注意力层第i个头的键值;
31、s2-3-4、根据公式:
32、
33、得到方面术语向量a;其中,n表示共有n个注意力头;wia为权重矩阵;
34、s2-3-5、将方面术语向量输入长短期记忆网络,根据公式:
35、it=σ(wxiat+whiht-1+bi)
36、ft=σ(wxfat+whfht-1+bf)
37、
38、
39、ot=σ(wxoat+whoht-1+bo)
40、ht=ottanh(ct)
41、得到当前时刻的隐藏状态ht;其中,it为输出门的输出,wxi、whi为权重矩阵,bi为偏置;ft为遗忘门的输出,wxf、whf为权重矩阵,bf为偏置;at为当前时刻的方面术语向量;σ为sigmoid激活函数,取值范围为[0,1];为候选细胞状态,wxc、whc为权重矩阵,bc为偏置;tanh为激活函数,取值范围为[-1,1],ht-1为上一时刻的隐藏状态;ct为当前时刻细胞状态;it为输入门的输出,ct-1为上一时刻的细胞状态;ot为输出门的输出,wxo、who为权重矩阵,bo为偏置;
42、s2-3-6、将当前时刻的隐藏状态ht输入解码器,得到新的句子的隐藏状态
43、s2-3-7、根据公式:
44、
45、
46、
47、分别得到对应的标签为b的概率h1、对应的标签为i的概率h2和对应的标签为o的概率h3;其中,w1a、b1a、w2a、w3a、为可学习参数;b表示开始,i表示内部,o表示其他;
48、s2-3-8、比较h1、h2和h3,将预测的最大概率值记为并将预测的最大概率值对应的标签作为隐藏状态对应的标签
49、s2-3-9、根据公式:
50、
51、得到损失值lateu,并回传损失值lateu,修改模型参数;其中,p表示第p个词;表示第p个词对应的标签为s”时的概率;表示第p个词对应的标签;log的底为e;为全局和局部训练空间数据中的句子转化后的句子集合;
52、s2-3-10、重复步骤s2-3-1至步骤s2-3-9,直到达到预定的次数,完成模型训练。
53、进一步地,步骤s3的具体实现方式如下:
54、s3-1、对自然语言提取句子;
55、s3-2、将句子送入训练好的第一tl-bert模型,得到句子对应的方面术语e={a0,...,aj,...,am'-1};其中,m'表示共有m'个方面术语,
56、s3-3、将句子对应的方面术语添加到句子的末尾,并用字符[sep]隔开,得到具有提示符的句子
57、s3-4、对具有提示符的句子生成对应的段索引和对应的位置索引其中,q'表示具有提示符的句子共有q'个词;
58、s3-5、将具有提示符的句子段索引和位置索引输入训练好的第一tl-bert模型,得到方面术语aj对应的意见词其中,lj表示第j个方面术语的意见词的数量;
59、s3-6、将方面术语和意见词构成方面-意见对。
60、进一步地,步骤s4的具体实现方式如下:
61、s4-1、根据方面-意见对对意见词对句子中的意见词和方面术语打上标签;
62、s4-2、将带有标签的句子、带有标签的句子对应的段索引和带有标签的句子对应的位置索引输入第二tl-bert模型中,得到带有标签的句子的隐藏状态
63、s4-3、对带有标签的句子的隐藏状态求平均值,得到
64、s4-4、根据公式:
65、
66、
67、得到对应的感情极性为积极的概率h'和对应的感情极性为消极的概率h”;w1s、为权重矩阵;为可学习参数;
68、s4-5、比较h'和h”,将最大概率值记为并将最大概率值对应的感情极性记为即情绪标签;
69、s4-6、根据公式:
70、
71、得到第二tl-bert模型的损失值laopsc,并回传损失值laopsc,修改模型参数;其中,k表示第j个方面术语的第k个意见词;为第j个方面术语的第k个意见词对应的标签为s'时的概率;为第j个方面术语的第k个意见词对应的标签;
72、s4-7、重复步骤s4-1至步骤s4-6直到预定的次数;完成第二tl-bert模型的训练,得到训练好的第二tl-bert模型。
73、进一步地,步骤s5的具体实现方式如下:
74、s5-1、将目标文本输入训练好的第一tl-bert模型,得到方面术语和意见词,构成目标文本的方面意见对;
75、s5-2、使用目标文本的方面意见对目标文本进行标记,并将标记后的目标文本输入到训练好的第二tl-bert模型,将输出的标签作为目标文本的情感极性。
76、本发明的有益效果为:本发明引入了全局训练空间使模型的训练,更加接近于真实世界的语境,使模型具有更好的泛化能力,简化了计算量;解决了目标词和意见词之间一对多和多对一的问题;添加了对非正式文本的处理,提高了识别准确度。
- 还没有人留言评论。精彩留言会获得点赞!