一种视频语义降噪方法、装置及电子设备与流程
本技术涉及视频处理和深度学习的,具体而言,涉及一种视频语义降噪方法、装置及电子设备。
背景技术:
1、目前的图像降噪主要是通过训练深度卷积神经网络,对原始(raw)域图像进行去噪,具体例如:对于图像降噪来说,使用训练好的神经网络提取原始域图像的色彩信息、亮度信息和纹理信息,从而在空间域两个维度上来估计和抑制噪声方差来实现降噪的效果。然而,对于视频流降噪来说,主要是在时间域和空间域两个维度上来实现视频流的降噪,在具体的实践过程中发现,使用目前的图像降噪方法对视频流的降噪效果不好。
技术实现思路
1、本技术实施例的目的在于提供一种视频语义降噪方法、装置及电子设备,用于改善视频流的降噪效果不好的问题。
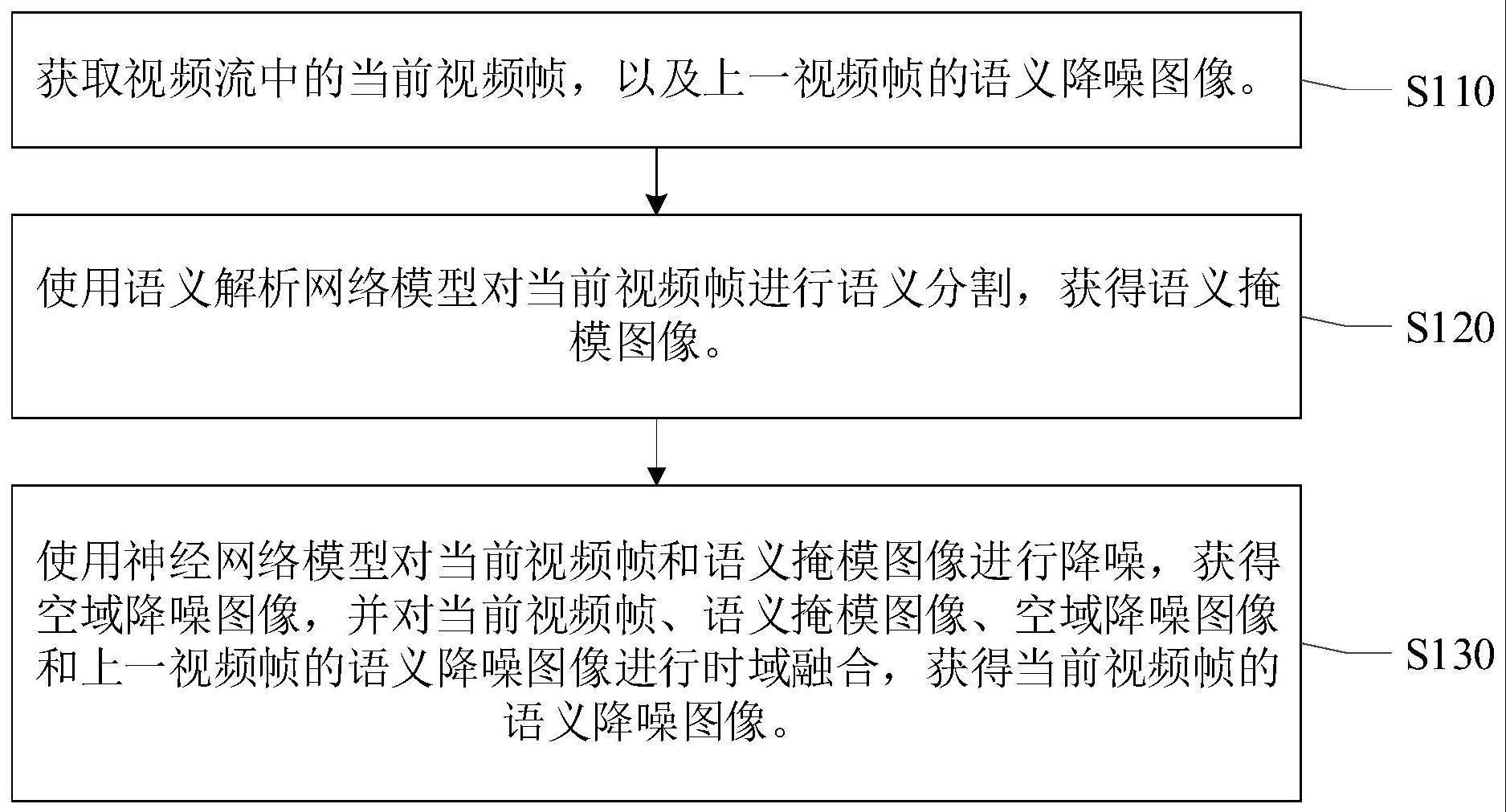
2、本技术实施例提供了一种视频语义降噪方法,包括:获取视频流中的当前视频帧,以及上一视频帧的语义降噪图像;使用语义解析网络模型对当前视频帧进行语义分割,获得语义掩模图像;使用神经网络模型对当前视频帧和语义掩模图像进行降噪,获得空域降噪图像,并对当前视频帧、语义掩模图像、空域降噪图像和上一视频帧的语义降噪图像进行时域融合,获得当前视频帧的语义降噪图像。在上述方案的实现过程中,通过将语义分割的语义掩模图像与空域降噪图像和上一视频帧的语义降噪图像进行时域融合,从而不仅考虑了时间域和空间域两个维度上的信息,还考虑当前视频帧的语义掩模信息,从语义掩模信息、时间域和空间域三个维度来共同降噪,从而有效地利用了语义掩模信息来提高视频流的降噪效果。
3、可选地,在本技术实施例中,使用语义解析网络模型对当前视频帧进行语义分割,包括:使用语义解析网络模型从当前视频帧中分割出感兴趣区域;以感兴趣区域为前景图像,以当前视频帧为背景图像,生成语义掩模图像。在上述方案的实现过程中,通过使用语义解析网络模型从当前视频帧中分割出的感兴趣区域来生成语义掩模图像,从而考虑了当前视频帧的语义掩模信息,从语义掩模信息、时间域和空间域三个维度来共同降噪,从而有效地利用了语义掩模信息来提高视频流的降噪效果。
4、可选地,在本技术实施例中,在使用语义解析网络模型从当前视频帧中分割出感兴趣区域之前,还包括:获取多个样本噪声图像和多个样本掩模图像,样本噪声图像是对样本原始图像进行加噪声获得的,样本掩模图像是样本原始图像对应的掩模图像;以多个样本噪声图像为训练数据,以多个样本掩模图像为训练标签,对语义解析神经网络进行训练,获得语义解析网络模型。在上述方案的实现过程中,通过对语义解析神经网络进行训练,获得语义解析网络模型,有效地结合了视频流降噪任务和语义分割任务的掩模图像,从语义掩模信息、时间域和空间域三个维度来共同降噪,从而有效地利用了语义掩模信息来提高视频流的降噪效果。
5、可选地,在本技术实施例中,获取多个样本噪声图像和多个样本掩模图像,包括:获取前景图像、背景图像和前景图像的掩模图像,并对前景图像的掩模图像进行图像增广,获得样本掩模图像;对前景图像和背景图像进行图层合并,获得合并贴图;对合并贴图进行图像增广,获得增广贴图,并对增广贴图进行逆图像信号处理,获得样本原始图像;向样本原始图像中加入随机噪声,获得样本噪声图像。在上述方案的实现过程中,通过对合并贴图进行图像增广,并对增广贴图进行逆图像信号处理获得样本原始图像,向样本原始图像中加入随机噪声,从而改善了人工方式来获取模型训练数据的效率低且成本较高的情况,有效地提高了获取模型训练数据的效率。
6、可选地,在本技术实施例中,在使用神经网络模型对当前视频帧和语义掩模图像进行降噪之前,还包括:获取多个样本原始图像,以及多个样本原始图像的样本掩模图像;以多个样本噪声图像和多个样本原始图像的样本掩模图像为训练数据,以多个样本原始图像为训练标签,对神经网络模型进行训练。在上述方案的实现过程中,通过对语义解析网络模型和神经网络模型进行分开训练,从而让各个模型相互解耦,可以根据具体项目实际需求来单独对各个模型进行切换或微调,从而有效地提高了训练语义解析网络模型和神经网络模型的灵活性。
7、可选地,在本技术实施例中,神经网络模型包括:空域降噪网络模块和时域融合网络模块;对神经网络模型进行训练,包括:使用空域降噪网络模块对当前样本原始图像和样本掩模图像进行降噪,获得当前样本原始图像的样本降噪图像;获取上一个样本降噪图像的预测语义降噪图像,并使用时域融合网络模块对样本原始图像、样本掩模图像、当前样本原始图像的样本降噪图像和上一个样本降噪图像的预测语义降噪图像进行时域融合,获得当前样本原始图像对应的预测语义降噪图像;计算出当前样本原始图像与当前样本原始图像对应的预测语义降噪图像之间的图像损失值;根据图像损失值更新空域降噪网络模块的权重参数和时域融合网络模块的权重参数。在上述方案的实现过程中,通过根据图像损失值更新空域降噪网络模块的权重参数和时域融合网络模块的权重参数,对空域降噪网络模块和时域融合网络模块分别训练,从而让各个模块相互解耦,可以根据具体项目实际需求来单独对各个模块进行切换或微调,从而有效地提高了训练空域降噪网络模块和时域融合网络模块的灵活性。
8、可选地,在本技术实施例中,语义解析网络模型,包括:unet模型、pspnet模型或者densenet模型。
9、本技术实施例还提供了一种视频语义降噪装置,包括:视频图像获取模块,用于获取视频流中的当前视频帧,以及上一视频帧的语义降噪图像;语义掩模获得模块,用于使用语义解析网络模型对当前视频帧进行语义分割,获得语义掩模图像;空域时域融合模块,用于使用神经网络模型对当前视频帧和语义掩模图像进行降噪,获得空域降噪图像,并对当前视频帧、语义掩模图像、空域降噪图像和上一视频帧的语义降噪图像进行时域融合,获得当前视频帧的语义降噪图像。
10、可选地,在本技术实施例中,语义掩模获得模块,包括:兴趣区域分割子模块,用于使用语义解析网络模型从当前视频帧中分割出感兴趣区域;语义掩模生成子模块,用于以感兴趣区域为前景图像,以当前视频帧为背景图像,生成语义掩模图像。
11、可选地,在本技术实施例中,视频语义降噪装置,还包括:样本图像获取模块,用于获取多个样本噪声图像和多个样本掩模图像,样本噪声图像是对样本原始图像进行加噪声获得的,样本掩模图像是样本原始图像对应的掩模图像;语义网络训练模块,用于以多个样本噪声图像为训练数据,以多个样本掩模图像为训练标签,对语义解析神经网络进行训练,获得语义解析网络模型。
12、可选地,在本技术实施例中,样本图像获取模块,包括:掩模图像获得子模块,用于获取前景图像、背景图像和前景图像的掩模图像,并对前景图像的掩模图像进行图像增广,获得样本掩模图像;合并贴图获得子模块,用于对前景图像和背景图像进行图层合并,获得合并贴图;原始图像获得子模块,用于对合并贴图进行图像增广,获得增广贴图,并对增广贴图进行逆图像信号处理,获得样本原始图像;噪声图像获得子模块,用于向样本原始图像中加入随机噪声,获得样本噪声图像。
13、可选地,在本技术实施例中,视频语义降噪装置,还包括:样本掩模获取模块,用于获取多个样本原始图像,以及多个样本原始图像的样本掩模图像;网络模型训练模块,用于以多个样本噪声图像和多个样本原始图像的样本掩模图像为训练数据,以多个样本原始图像为训练标签,对神经网络模型进行训练。
14、可选地,在本技术实施例中,神经网络模型包括:空域降噪网络模块和时域融合网络模块;网络模型训练模块,包括:图像空域降噪子模块,用于使用空域降噪网络模块对当前样本原始图像和样本掩模图像进行降噪,获得当前样本原始图像的样本降噪图像;图像时域融合子模块,用于获取上一个样本降噪图像的预测语义降噪图像,并使用时域融合网络模块对样本原始图像、样本掩模图像、当前样本原始图像的样本降噪图像和上一个样本降噪图像的预测语义降噪图像进行时域融合,获得当前样本原始图像对应的预测语义降噪图像;图像损失计算子模块,用于计算出当前样本原始图像与当前样本原始图像对应的预测语义降噪图像之间的图像损失值;权重参数更新子模块,用于根据图像损失值更新空域降噪网络模块的权重参数和时域融合网络模块的权重参数。
15、可选地,在本技术实施例中,语义解析网络模型,包括:unet模型、pspnet模型或者densenet模型。
16、本技术实施例还提供了一种电子设备,包括:处理器和存储器,存储器存储有处理器可执行的机器可读指令,机器可读指令被处理器执行时执行如上面描述的方法。
17、本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如上面描述的方法。
18、本技术实施例的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本技术实施例了解。
- 还没有人留言评论。精彩留言会获得点赞!