基于随机采样的分布式噪音数据聚类方法及用户分类方法
本发明属于数据处理,具体涉及一种基于随机采样的分布式噪音数据聚类方法及用户分类方法。
背景技术:
1、聚类是机器学习的最基本问题之一。聚类分析是根据数据的信息特征,将数据对象分组,使得组内的数据对象之间尽可能相似,而组间的数据对象之间则尽可能不同。聚类算法的用途非常广泛,在数据决策、数据推荐和数据分析等领域有着广泛应用;因此,聚类模型也一直是人们研究的重点。常用的聚类模型有k-均值聚类,k-中值聚类和k-中心聚类等。聚类问题是经典的np难( nphard)问题,即除非假定np=p,否则无法在多项式时间内找到问题的最优解。因此,近似算法成为常用的聚类分析方法之一。
2、k-中心问题一直是聚类中的一个热门模型,其目标是在给定度量空间内找到k个中心点,将数据分配到中心点形成k个类簇,使得最大类簇半径最小化
3、目前,在度量空间中,已知k-中心问题的近似比为2是该问题的下界。但在实际应用中,数据聚类往往伴随着噪声的干扰,且已知k-中心模型对噪声数据极为敏感。在数据分析中,这些噪声的干扰往往会严重影响最终的聚类结果分析。如何在聚类的过程中去除噪音点的影响,这就是带噪音的聚类问题。
4、目前,带噪音的数据聚类问题,行业内虽然有对应的分布式聚类方法,但是现有方法的聚类精度较差,而且通讯复杂度和机器时间复杂度较高,实际应用时效果较差。
5、正因如此,基于带噪音数据聚类方法的用户分类方法,也受到了极大地影响。目前,由于带噪音数据在聚类过程中的可靠性问题和复杂度问题,基于带噪音数据聚类方法的用户分类方法在实际应用中也存在较大的问题,这将导致用户分类的结果不准确,从而影响后续的用户服务推荐和用户数据分析等过程,从而极大地影响用户的体验。
技术实现思路
1、本发明的目的之一在于提供一种精度较高、通讯复杂度较低、机器运行时间快且实用性好的基于随机采样的分布式噪音数据聚类方法。
2、本发明的目的之二在于提供一种包括了所述基于随机采样的分布式噪音数据聚类方法的用户分类方法。
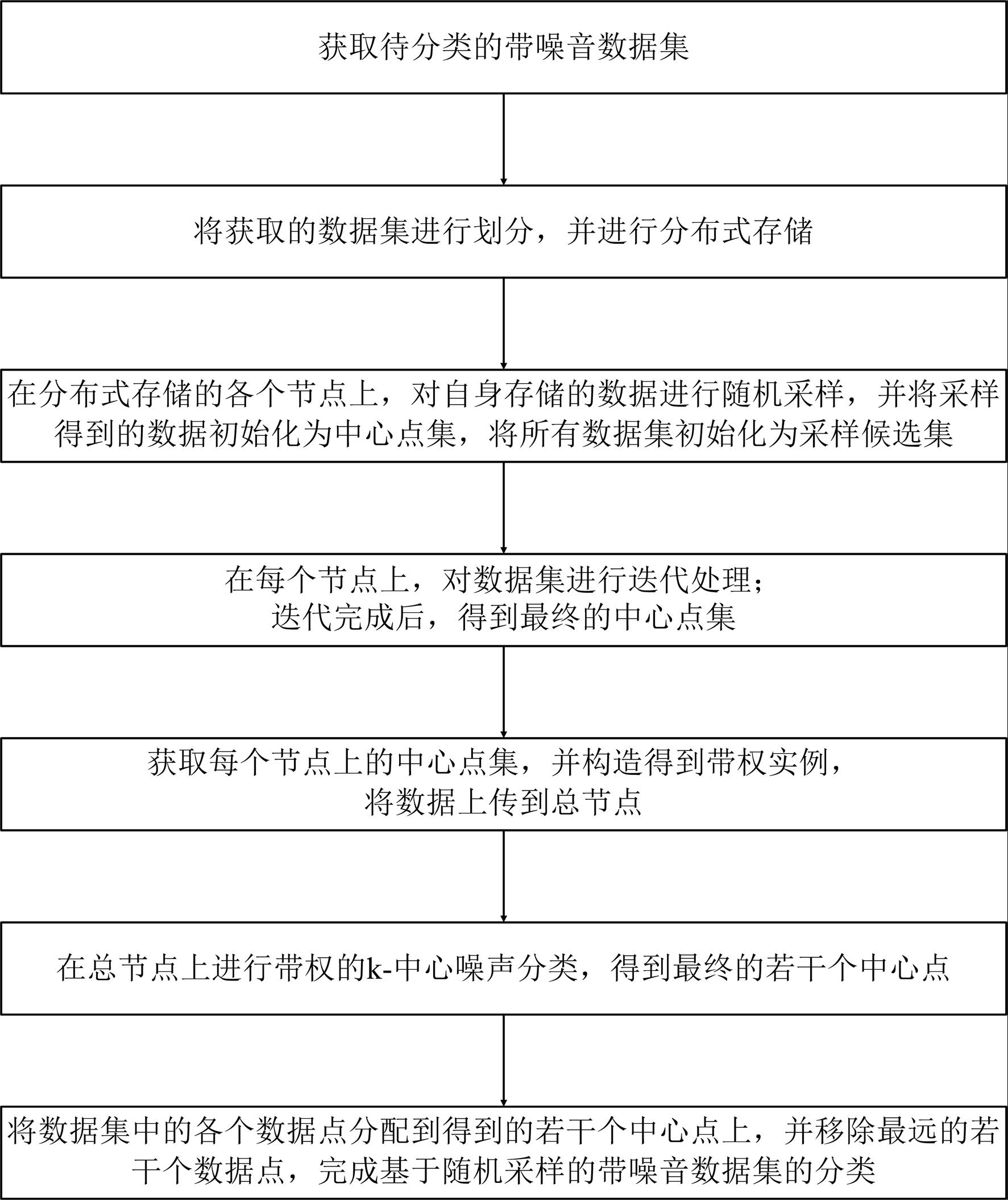
3、本发明提供的这种基于随机采样的分布式噪音数据聚类方法,包括如下步骤:
4、s1. 获取待分类的带噪音数据集;
5、s2. 将步骤s1获取的数据集进行划分,并进行分布式存储;
6、s3. 在分布式存储的各个节点上,各个节点对自身存储的数据进行随机采样,并将采样得到的数据初始化为中心点集,同时将所有数据集初始化为采样候选集;
7、s4. 在每个节点上,对数据集进行迭代处理:每一轮迭代时,随机采样若干个数据点,并在采样得到的数据点中进行二次采样,并将二次采样结果加入到中心点集中,然后将中心点集中的中心点设置范围内的数据点覆盖,并将覆盖的数据点从采样候选集中删除;迭代完成后,得到最终的中心点集;
8、s5. 获取每个节点上的中心点集,并构造得到带权实例,并将数据上传到总节点;
9、s6. 在总节点上进行带权的k-中心噪声分类,得到最终的若干个中心点;
10、s7. 将数据集中的各个数据点分配到步骤s6得到的若干个中心点上,并移除最远的若干个数据点,完成基于随机采样的带噪音数据集的分类。
11、步骤s3所述的随机采样,具体包括如下步骤:
12、采用如下算式作为优化目标函数:式中 x为给定数据集中去除了噪音点的子集,且 x= n\ z, n为步骤s1获取的数据集中所有数据集合, z为去除的噪音点的集合,\为集合删除操作,而且, z为输入参数,表示待移除的噪音点数量上限; p为集合 x中的数据点;将集合 x分为 k个簇,分别为,为所选的第 j个中心点集的中心点;为数据点 p到第 j个中心点集的中心点的距离;随机采样的数据点的个数设定为,其中和均为设定的参数;所述目标函数用于优化最大类簇半径,使得尽可能找到紧密的 k个类簇对数据进行分类,并找到偏离类簇的数据点作为噪音点移除。
13、所述的步骤s4,具体包括如下步骤:
14、根据未被覆盖的数据集的大小,采用分布采样的思想,从当前的候选采样集中随机选取若干个数据点,得到第一随机数据点;
15、然后再从第一随机数据点中再次随机选取若干个数据点,得到第二随机数据点;
16、将第二随机数据点加入到当前的中心点集中,并将更新后的中心点集作为当前的中心点集;
17、在当前的中心点集中,找到距离中心点在设定范围内的数据点进行标记,并将标记后的数据点在采样候选集合中删除;
18、重复以上步骤若干次,最终得到中心点集。
19、所述的步骤s4,具体包括如下步骤:
20、在当前轮次的迭代中,对未被覆盖的数据集大小进行判断:
21、若未被覆盖的数据集中,数据点的个数大于设定值,则从当前的采样候选集中随机选取个数据点,作为第一随机数据点;然后从第一随机数据点中,再随机选取个数据点作为第二随机数据点;将第二随机数据点加入到当前的中心点集中;
22、若未被覆盖的数据集中,数据点的个数小于或等于设定值,则找到整数 r满足;然后,从当前的采样候选集中随机选取个数据点,作为第一随机数据点;再从第一随机数据点中,随机选取个数据点作为第二随机数据点;将第二随机数据点加入到当前的中心点集中;其中,和均为设定的参数, z为噪声的数量,为当前采样候选集 u中的数据个数, m为节点的数量;
23、将第二随机数据点加入到当前的中心点集后,在当前的中心点集中,找到距离中心点范围内的数据点并进行标记,将标记后的数据点在当前的采样候选集合中删除;为设定的参数;
24、重复以上步骤共次,最终得到中心点集;为设置的大于1的常数参数,用于控制聚类质量;取值越大,则聚类质量越高,但是所需的时间复杂度越大; k为待打开的中心点数量。
25、步骤s5所述的构造得到带权实例,具体包括如下步骤:
26、以中心点集中的个候选中心点为中心点,将所有数据点分类给距离自己最近的候选中心点;每个中心点的权值为分配到该中心点的数据点的个数;为计算函数且, k为待打开的中心点数量,为设置的一个大于设定值的实数。
27、步骤s6所述的带权的k-中心噪声分类,具体包括如下步骤:
28、采用贪心迭代的方式,最终选取k个中心点;
29、在迭代过程中,每次选取给定半径范围2内所覆盖的权值之和最大的点作为中心点;在带权实例中,删除以该点为中心点、半径4内所覆盖的所有点;为设定的参数。
30、步骤s7所述的移除最远的若干个数据点,具体为移除最远的个数据点,其中 z为噪声的数量,为设定的参数。
31、本发明还公开了一种包括了所述基于随机采样的分布式噪音数据聚类方法的用户分类方法,包括如下步骤:
32、a. 获取原始的用户基本信息;
33、b. 将步骤a获取的用户基本信息作为待分类的带噪音数据集,采用所述的基于随机采样的分布式噪音数据聚类方法进行分类;
34、c. 将步骤b得到的分类结果作为用户分类结果,完成用户的分类。
35、本发明提供的这种基于随机采样的带噪音数据分类方法及用户分类方法,通过分布采样、随机采样和迭代处理的方式,不仅实现了带噪音数据的分类,而且本发明的可靠性高、准确性好且效率较高。
- 还没有人留言评论。精彩留言会获得点赞!