一种基于专家系统的规则引擎对报警数据的处理方法与流程
本发明属于道路交通大数据,具体涉及一种基于专家系统的规则引擎对报警数据的处理方法。
背景技术:
1、当前人工智能技术高速发展,但是由于高速公路的通行复杂性,人工智能在高速公路视频分析事件检测方面始终不得其法。
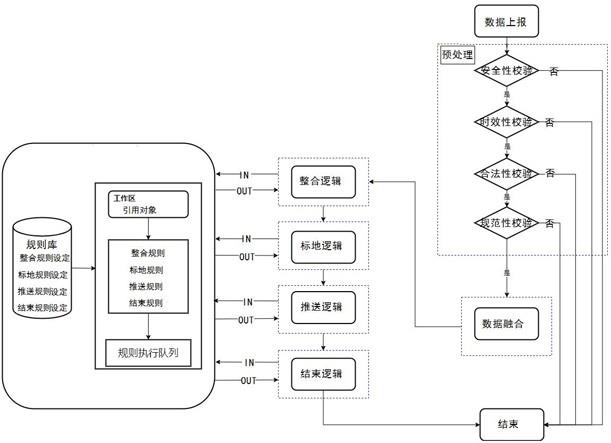
2、业务故事:平台按照发现相机的位置,将报警数据按照相机位置和时间维度整合后形成,1个相机位置为1个业务故事。例如,如果在高速公路上有一辆车因为故障停驶在路边,然后司机打电话给救援有关单位,有关单位通知司机立即下车防止三脚架,然后躲到公路护栏之外等待救援;后续救援车辆到达并停驶在应急车道,救援人员下车放置锥桶,然后进行车辆解脱救援。
3、以上场景,当前人工智能算法只能识别到很多次车辆停驶、行人闯入、抛洒物等具体行为,没有办法判定上述场景是否为一起救援事件。
4、那么以上场景人工智能算法的识别结果如下:
5、在某桩号的应急车道存在小轿车停驶n次。
6、在某桩号的应急车道存在行人闯入n次。
7、在某桩号的应急车道存在三脚架抛洒n次。
8、在某桩号的应急车道存在救援车辆停驶n次。
9、在某桩号的应急车道存在救援人员闯入n次。
10、在某桩号的应急车道存在锥桶抛洒物n次。
11、这些识别结果在救援结束期间,会多次出现,导致数据量巨大无法人工标定,也无法使用在调度系统中落地使用。
12、为便于对本技术方案的理解,关于涉及的专业术语解释如下:
13、调度系统业务数据是指某路公司的调度系统产生的事故或救援总数。
14、专家系统(rbes)属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。专家系统有很多分类:神经网络、基于案例推理和基于规则系统等,该rbes包括三部分:基础规则(规则集)、工作内存和推理引擎。
15、即时规则评估算法就是rete算法,rete是拉丁文,对应英文是net也就是网络的意思。在1974年由内基梅隆大学的 charles l.forgy 博士在他的论文《a fast algorithmfor the many pattern/many object pattern match problem》提出,后来成为了产生式规则系统(production rule system)的大脑,该算法是一个快速的模式匹配算法,是一种在大量规则和大量对象之间进行规则匹配和比较的高效方法。rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关,事实只有在满足本节点时才会继续向下沿网络传递,它通过形成一个rete网络进行模式匹配,利用时间冗余性(temporalredundancy)和结构相似性(structural similarity)这两个特性来提高系统模式匹配效率。
16、推理引擎包括三部分:模式匹配器(pattern matcher)、议程(agenda)和(规则引擎)执行引擎(execution engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式匹配器决定选择执行哪个规则,何时执行规则;议程管理模式匹配器挑选出来的规则的执行次序;执行引擎负责执行规则和其他动作。
技术实现思路
1、本发明的目的在于提供一种基于专家系统的规则引擎对报警数据的处理方法,实现将n*n条算法报警数据通过规则引擎整合成了1条story数据,人工只需要标定1条story数据就能对本次算法检测结果进行定性。
2、为实现上述目的,本发明提供如下技术方案:一种基于专家系统的规则引擎对报警数据的处理方法,具体包括如下步骤:
3、步骤(s1)、基于专家系统建立执行规则集;
4、步骤(s2)、预处理,包括对数据的安全性校验、时效性校验和合法性校验处理;
5、步骤(s3)、数据融合:
6、预处理后的数据作为对象数据,存入工作内存中,并触发执行规则集;
7、步骤(s4)、整合规则:
8、如果不存在同一位置的告警信息,则执行:创建业务故事,存入工作内存;存入数据库,持久化ai报警信息;更新业务故事状态为"待标定";
9、如果存在同一位置告警,但不包含告警类型,则执行:告警类型包含:停驶、非法闯入、抛洒物、警示物、倒车、逆行、拥堵;更新业务故事,存入工作内存;存入数据库,持久化ai报警信息;更新业务故事状态为"待标定";
10、如果存在同一位置告警,并且包含当前告警类型,则执行:更新业务故事,存入工作内存;存入数据库,持久化ai报警信息;更新业务故事状态为"待标定";
11、步骤(s5)、标地规则:
12、如果业务故事状态为"待标定",则执行:根据汇聚的告警信息,标定业务故事是否被检出、是否主动发现、是否报警准确;更新业务故事状态为"待推送";
13、步骤(s6)、推送规则:
14、如果业务故事为"待推送"状态,则执行:根据配置策略,通过接口或数据中间件的方式推送数据至高速公路调度指挥系统;更新业务故事状态为"待结束";
15、步骤(s7)、结束规则:
16、业务故事状态为"待标定",则执行:清除规则引擎内存业务故事数据;
17、持久化业务故事至数据库。
18、作为本发明的进一步改进,所述步骤(s1)中,基于专家系统建立执行规则集具体包括以下步骤:
19、步骤(a1)、将对象数据输入专家系统的工作内存,作为规则1、规则2……规则n;
20、步骤(a2)、使用模式匹配器比较规则库中的规则设定1、规则设定2……规则设定n与工作内存中的规则1,规则2……规则n;对于模式匹配器:一个规则是一组模式的集合;如果事实/假设的状态符合该规则的所有模式,则称为该规则是可满足的;模式匹配的任务就是将事实/假设的状态与规则库中的规则一一匹配,找到所有可满足的规则;正则表达式就是一种典型的模式匹配;
21、步骤(a3)、利用规则引擎执行规则库中规则设定1、规则设定2……规则设定n与工作内存中的规则1、规则2……规则n;
22、步骤(a4)、如果步骤(a3)执行规则时存在冲突,即同时激活了多个规则,将冲突的规则放入冲突集合;
23、步骤(a5)、解决冲突,并将激活的规则按顺序放入议程(用于存储被激活的规则的分类和排序的地方),得到规则执行列队;
24、步骤(a6)、利用规则引擎执行议程中的规则,直到执行完毕规则执行列队中所有的规则,得到执行规则集。
25、作为本发明的进一步改进,所述规则引擎系统中的规则采用即时规则评估算法进行规则评估,该规则评估包括以下步骤:
26、步骤(b1)、启动引擎,所有规则都被认为与可以触发规则的模式匹配数据断开链接;
27、步骤(b2)、根据规则引擎匹配执行的规则,计算并选择下一个评估规则,当为规则填充所有必需的输入值时,该规则被视为已链接更新到相关的模式匹配数据;
28、步骤(b3)、然后,即时规则评估算法创建一个代表该规则的目标,并将该目标放入按规则显着性排序的优先级队列中;
29、步骤(b4)、仅评估为其创建目标的规则,而延迟其他潜在的规则评估;在评估单个规则时,仍然通过分段过程实现节点共享;
30、步骤(b5)、对于正在评估的规则,引擎访问第一个节点并处理所有排队的插入、更新和删除操作;
31、步骤(b6)、结果被添加到一个集合中,并将该集合传播到子节点,在子节点中,处理所有排队的插入、更新和删除操作,将结果添加到同一个集合中;
32、步骤(b7)、然后将该集合传播到下一个子节点;
33、步骤(b8)、重复步骤(b5)—步骤(b7),直到它到达终端节点;
34、步骤(b9)、构建规则网络,为由同一组规则共享的规则网络节点创建段,规则由段路径组成,如果一条规则不与任何其他规则共享任何节点,则它成为一个单独的段;
35、步骤(b10)、为段中的每个节点分配一个位掩码偏移量,为规则路径中的每个段分配另一个位掩码:如果存在至少一个节点的输入,则将节点位设置为on状态;如果段中的每个节点都将位设置为on状态,则段位也设置为on状态;如果任何节点位被设置为off状态,则段也被设置为off状态;如果规则路径中的每个段都设置为on状态,则认为该规则已链接,并创建一个目标来安排该规则进行评估。
36、作为本发明的进一步改进,所述步骤(b10)中,相同的位掩码技术用于跟踪修改的节点、段和规则,如果自步骤(b3)创建评估目标以来已对其进行了修改,则此跟踪功能使已链接的规则从评估中取消调度。
37、作为本发明的进一步改进,所述步骤(s2)中的数据安全性校验是通过md5秘钥和上报时间,得到md5加密后的数据字段,与上报的数据字段相比,相同则通过,反之校验失败。
38、作为本发明的进一步改进,所述步骤(s2)中的数据时效性校验是对上报数据的时间范围进行校验,距离当前不能超过规定时间,规定时间可配置。
39、作为本发明的进一步改进,所述步骤(s2)中的数据合法性校验是必填字段的不能空缺,如若空缺则返回失败。
40、与现有技术相比,本发明的有益效果是:本技术方案通过将n*n条算法报警数据通过规则引擎整合成了1条业务故事数据,人工只需要标定1条业务故事数据,即可实现对本次算法检测结果定性,具有简单快速、节省时间、减少人工标定的工作量,在调度系统中落地使用方便的有益技术效果。
- 还没有人留言评论。精彩留言会获得点赞!