一种应用于云边端的checkpoint分布式系统处理方法
本发明涉及云计算、物联网领域,具体地说,涉及一种应用于云边端的checkpoint分布式系统处理方法。
背景技术:
1、随着互联网用户的数据量不断增加和实时性需求的不断增长,基于云边端的分布式内存计算的数据处理框架己成为公司数据业务和科学研究的首选工具。为了提高计算系统的性能,一方面,处理器供应商不断增加单个芯片晶体管的数量;另一方面,通过增加系统中每个节点的处理器数量以及计算节点的数量来扩大系统的规模,这导致系统发生故障的概率不断增加。云计算作为迎合网络时代发展孕育出来的技术已经收到各界广泛关注,然而就故障处理能力而言,云计算技术仍旧存在许多不足之处。首先云数据中心的系统架构是动态的,并且复杂度不断增长,其次云计算平台的基础组件具有多样性,因此云环境总是出现种种故障。这些故障通常会中断云服务的正常交付并降低云系统性能,严重时甚至可能导致用户的经济损失。
2、现有的分布式系统spark的检查点(checkpoint)操作将rdd的计算结果存储到磁盘上,并缩短lineage,这为lcv策略将rdd数据转移到磁盘,从而进一步释放内存提出了可能性。但并不是所有场景下使用检查点操作都可以获得更好的工作效果,因为检查点会增添一个job专门用于储存rdd数据,此操作由于牵涉到磁盘i/o而十分耗时。flink根据流式计算设计了一个轻量级的异步快照算法,在计算的各阶段结束时设置检查点,在底层文件系统中备份相应的数据文件,每当任务中断导致中间计算结果丢失时,需要从底层读取检查点数据。然而,这种方式需要通过网络连接在节点之间传输大量数据,并且需要读取磁盘上的文件,导致操作成本很高。
技术实现思路
1、本发明的目的在于提供一种应用于云边端的checkpoint分布式系统处理方法,以解决上述背景技术中提出的问题。
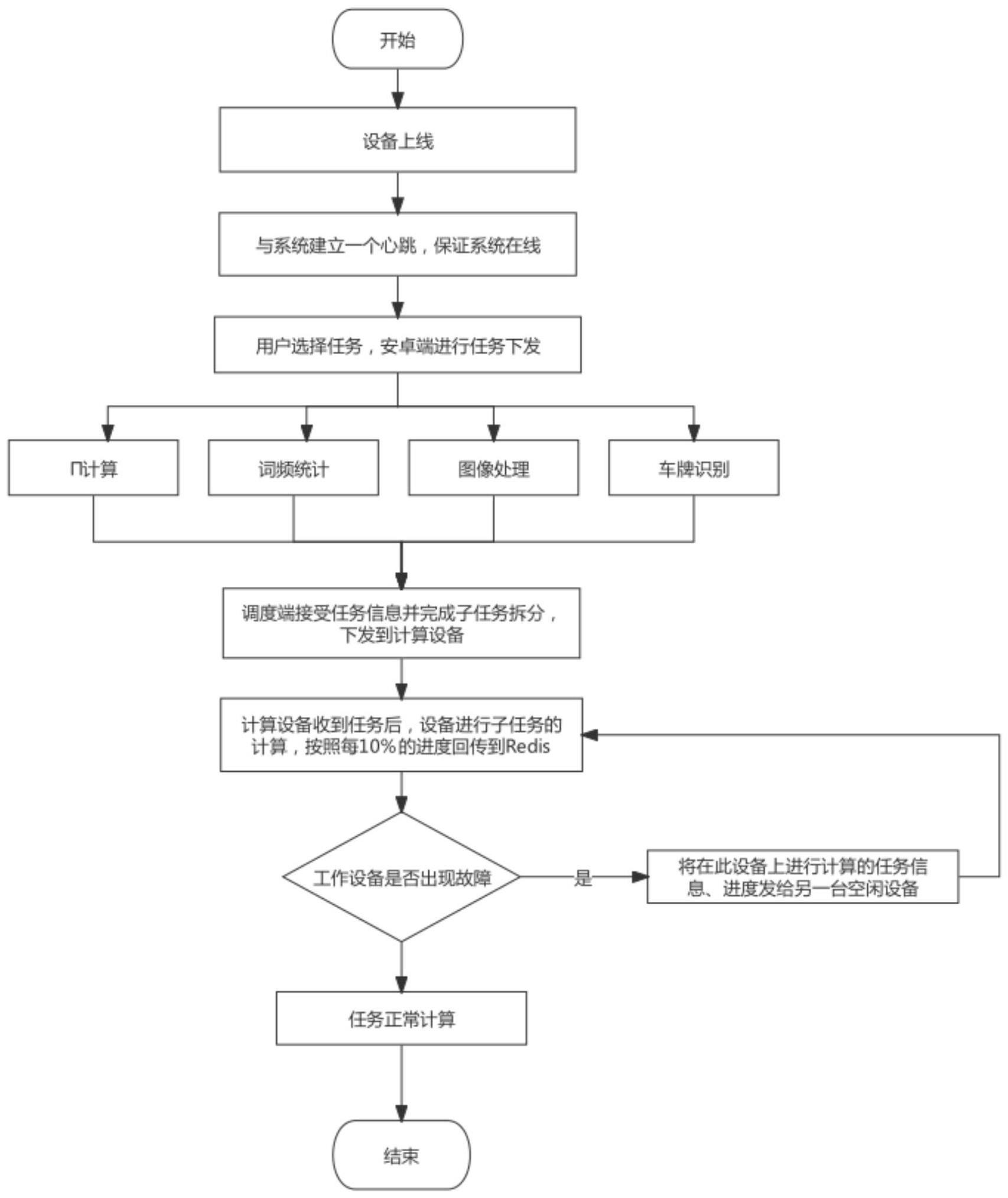
2、为实现上述目的,本发明目的之一在于,提供了一种应用于云边端的checkpoint分布式系统处理方法,所述应用于云边端的checkpoint分布式系统处理方法包括如下步骤:
3、启动设备上线,获取设备信息,与系统建立一个心跳,保证系统在线;
4、用户选择要执行的任务,安卓端获取任务信息并进行任务下发;
5、云端的调度模块从数据库获取将要执行的任务或者任务集,进行加工处理,每个所述要执行的任务拆分成多个子任务放到下发到计算设备;
6、计算设备端解析任务信息,通过http请求从云端获取任务,设备进行子任务的计算,按照每10%的进度将计算信息回传到redis;
7、判断设备是否出现故障,若出现故障,则将保存的故障设备在redis中预存的计算进度信息、当前运行子任务、掉线任务信息和算法信息等数据通过checkpoint将发送给另一台空闲设备,若未出现故障则计算完成。
8、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述用户选择要执行的任务,安卓端获取任务信息并进行任务下发包括:
9、首先新建任务集,创建任务id集,然后形成未执行任务队列和任务队列来控制任务执行流程,对任务队列中单个任务拆分成多个子任务,并形成子任务队列;
10、所述子任务信息包括任务id,子任务id,车辆id,计算函数,状态,结果和参数;
11、所述安卓端从设备调度处选择适合当前任务计算的计算设备端发送这些子任务的信息,用事件队列记录发送成功或者失败的情况;
12、当发送子任务成功后,把子任务信息中状态改成接收成功,当计算设备端遇到故障时,将故障设备的进度信息发送给其他空闲计算设备端直至成功。
13、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述计算设备端解析任务信息,通过http请求从云端获取任务,设备进行子任务的计算包括:
14、设置要执行的任务集队列,通过runallwithname()执行任务集队列中的任务;
15、不断的重复任务执行过程直到任务集队列中的所有任务执行完成。
16、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述不断的重复任务执行过程直到任务集队列中的所有任务执行完成包括:
17、获取一个单任务通过所述runwithname()执行此任务;
18、对所述单任务分解为多个子任务,通过readdeviceinfo()从redis中读取全部在线设备信息,并形成设备列表;
19、调用taskmap()将分解出来的所述子任务集通过sendalgorithminfo()下发到车载安卓设备端,将每个子任务发送成功或者失败的信息记录在sendeventlist事件队列里面;
20、对所述事件队列中发送失败的子任务执行二次调度,再次调用所述sendalgorithminfo()下发到其他在线空闲且适合工作的设备上;
21、遇到设备故障掉线问题,将故障设备的进度信息从redis中提取出来发送给其他空闲设备直至成功,等待计算完成;
22、设备端子任务完成后,结果信息自动发送到云端并记录在redis中。
23、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述进度信息回传到redis,其中周期性的将所述任务的状态和变量定期保存在redis上,当任务执行过程中出现故障时,把redis上的计算信息下发给另一个正常运行的设备,保证任务可以继续正确地执行。
24、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述当计算设备端遇到故障时,将故障设备的进度信息发送给其他空闲计算设备端直至成功包括:
25、故障设备上子任务会被所述设备调度处从redis中拉取出来,并重新选择故障子任务个数的新的在线设备;
26、当前无空闲计算设备可用时,所有运行主任务下的子任务都会每隔10秒监测计算计算设备端上线情况,当有新计算设备端上线,符合计算条件,子任务会被从redis中拉出重新参与计算。
27、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述安卓端从设备调度处选择适合当前任务计算的计算设备端发送这些子任务的信息,用事件队列记录发送成功或者失败的情况包括:
28、子任务过期监听每隔10s后被触发,引发子任务下发超时重传lbfo,无可用计算设备端,子任务又被重新压入过期监听中,每隔10s触发过期监听,当有新的计算设备端接入网络,子任务会被下发到新计算设备端参与计算。
29、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述在redis中预存的计算进度信息,其中redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用,redis底层数据结构值可以是字符串,哈希,列表,集合和有序集合等类型。
30、进一步,在上述应用于云边端的checkpoint分布式系统处理方法中,所述按照每10%的进度信息回传到redis,通过前端展示进度条的形式实时的监控存储的情况。
31、在本发明提供的技术方案中,通过设置checkpoint策略,设备正常运行过程中,周期性的将计算的任务状态和变量定期保存在redis上,当任务执行过程中出现故障时,把redis上的计算信息下发给另一个正常运行的设备,保证任务可以继续正确地执行,并最终完成任务,避免了从头开始运行,减少了故障带来的损失,可以使用先前保存的恢复信息从中间状态重新开始计算,从而减少丢失的计算量,增强云系统的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!