一种基于程序上下文的断言生成方法
本发明属于计算机,尤其是软件分析测试领域。本发明提供了一种面向java语言的、基于程序上下文的断言生成方法,用于生成高质量能编译的断言语句。
背景技术:
1、软件测试是软件生命周期的重要组成部分。研究表明开发人员需要消耗近一半的时间来测试编写的代码,因此自动化测试长时间以来被研究人员关注。在自动化测试中,单元测试主要用于验证代码组件(例如函数,类等)的正确性,与其他等级的测试相比,单元测试能够更加快速的检测代码的缺陷。单元测试的测试用例包括两个部分,测试输入和测试断言,测试断言用于判断测试输入能否按照预期运行。当前常用的测试用例自动生成工具包括java的自动化测试用例生成工具evosuite和randoop,python的自动化工具pynguin等,这些工具更加关注于高的代码覆盖率而忽视了断言的质量。根据almasi等人的研究,这些工具生成的断言只能检测defects4j数据集中40.6%的缺陷。除了断言质量不高外,这些方法还需要动态检测被测程序,有着较高的运行时间成本。
2、目前,已有一些研究利用不同的方法进行自动化断言生成。例如,yu等人利用了信息检索技术,以及watson等人基于深度学习技术进行断言生成,但是他们是通过把测试和被测函数输入到模型中进行断言生成。也就是说,他们将断言生成问题简单当作文本生成问题来处理,没有应用到上下文的依赖信息。因此,这两种方法生成的断言语句不能编译运行,只能供开发人员参考。在这样的背景下,我们提出了一个自动化的实证分析的框架,旨在分析哪些因素影响了python调用图的构造效果,并将评判的标准主要聚焦于召回率。一方面通过对python语言中调用发生的模式进行详尽的分类,把工具的局限性归因到具体的语言特性或使用模式;另一方面,我们以开源项目作为测试的数据,通过语法分析和动态插桩实现对项目中调用的标注,并以动态运行时抽取的动态调用图作为依据,比较分析调用图工具的效果。
3、在这样的背景下,我们提出了一种基于程序上下文的断言生成方法,旨在用神经机器翻译模型生成能编译的断言语句。一方面通过tranx模型的方法,先生成抽象语法树的构造序列再生成断言语句,这样的作法保证了断言的语法正确性;另一方面通过spoon工具提取断言的上下文信息,通过限制翻译模型的解码器的解码生成能编译的断言。
技术实现思路
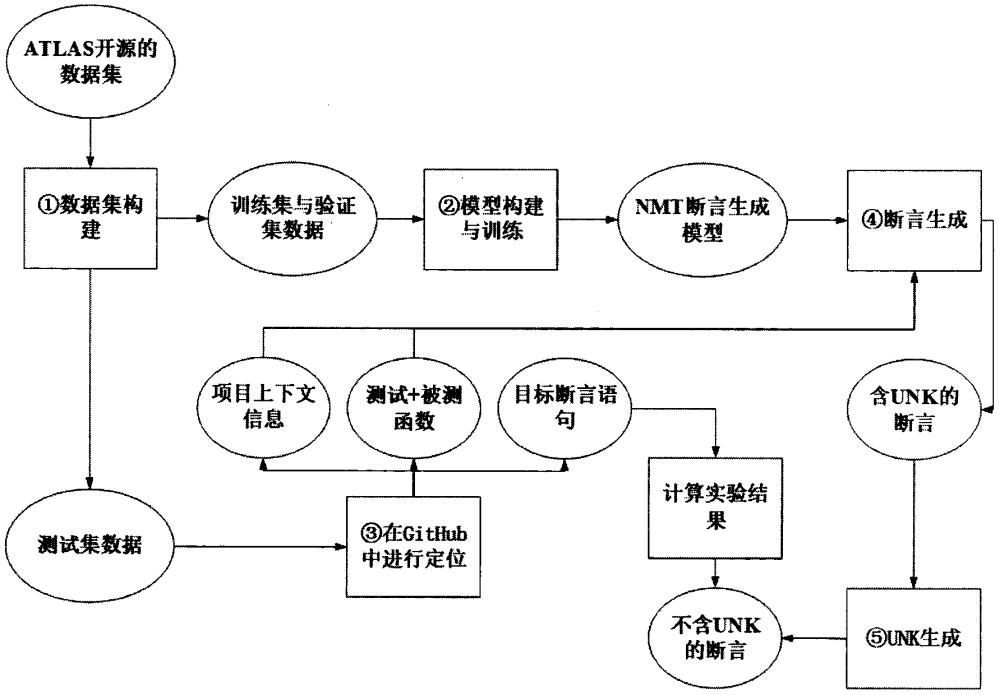
1、本发明提出了以下的断言生成方法,用以生成能编译的断言语句。本发明由以下几个模块组成:
2、●数据集构建:该模块负责对断言语句的语法分析,将其转化为语法序列;
3、●模型构建与训练:该模块负责构建神经机器翻译模型并用数据集进行训练;
4、●数据集定位模块:该模块会到开源项目集合中寻找断言所对应的位置;
5、●断言生成模块:该模块负责在神经机器翻译模型测试过程的解码阶段提取正在生成的断言的上下文,并依照上下文信息对词表进行限制。
6、●unk生成模块:该模块旨在找出神经机器翻译模型生成的unk,并用上下文信息对其进行生成。
7、接下来具体介绍各个模块的运行步骤:
8、首先,数据集构建模块的具体步骤如下:
9、步骤1):起始状态;
10、步骤2):选取atlas工具提供的数据集作为研究对象,数据集用例的格式为<测试函数-被测函数,断言语句>;
11、步骤3):提取atlas数据集中的断言语句,用python的javalang包将其转化为抽象语法树;
12、步骤4):先序遍历抽象语法树,得到抽象语法树的生成序列;
13、步骤5):将atlas提供的测试函数,被测函数与抽象语法树的生成序列结合,构建用例格式为<测试函数-被测函数,语法序列>的数据集;
14、步骤6):按照8∶1∶1的比例将数据集划分为训练集,验证集和测试集;
15、步骤7):数据集构建完毕。
16、其中,模型构建与训练模块的具体步骤如下:
17、步骤1):起始状态;
18、步骤2):从训练集的测试函数-被测函数序列中选取出现频率最高的1000个词作为输入的词表,从训练集的语法规则序列中选取出现频率最高的1000个词作为模型输出的词表;
19、步骤3):用一个双向的lstm作为模型的编码器,用于将输入文本转化为中间向量表示;
20、步骤4):同样用一个双向的lstm作为模型的解码器,用于将中将向量表示转化为文本序列输出。将父节点的信息编码进行解码器,用于限制模型;
21、步骤5):用训练集对模型训练300000轮,耗时约40h;
22、步骤6):模型构建且训练完毕。
23、接着,数据集定位模块的具体步骤如下:
24、步骤1):起始状态;
25、步骤2):从github中提取并克隆项目;
26、步骤3):分析项目的pom文件,查看是否有junit的依赖,过滤掉不包括junit依赖的项目;
27、步骤4):用spoon工具提取所有的测试函数,删除掉注释部分;
28、步骤5):按照文本完全一致的规则,根据每条用例的测试函数和北侧函数寻找其所属的项目;
29、步骤6):数据集定位完毕。
30、进一步,断言生成模块的具体步骤如下:
31、步骤1):起始状态;
32、步骤2):根据已生成的语法序列得知当前正在生成的词的类型;
33、步骤3):用spoon工具从项目中提取对应类型的上下文集合;
34、步骤4):根据词的类型对应的启发式规则对词表进行过滤,不同类型及其对应的启发式规则如下:
35、●常量值value:符合类型检查;
36、●引用类型referencetype:符合类型检查,符合先定义后引用,符合是否存在子类型
37、●变量引用memberreference:符合类型检查,符合先定义后使用
38、●二元操作符binaryoperator:左操作数类型符合
39、●java基本类型basictype:符合类型检查
40、●函数名methodname:返回值符合类型检查,参数序列符合,符合先定义后使用
41、●前缀名prefix:符合先定义后使用
42、步骤5):选取过滤后的词表中预测概率最高的词作为当前的生成结果;
43、步骤6):用模型生成语法序列之后,对其进行规约构建抽象语法树,同时构建断言语句;
44、步骤7):断言生成完毕。
45、接着,unk生成模块的具体步骤如下:
46、步骤1):遍历生成的断言语句中的unk;
47、步骤2):选取其中的一个unk作为生成对象;
48、步骤3):根据生成的抽象语法树得到unk的父节点,并由此可知unk的类型;
49、步骤4):用spoon工具提取对应类型的上下文词的集合;
50、步骤5):当前unk的取值范围即为上下文词的集合与词表的差集;
51、步骤6):若还有unk没有求得取值范围,则跳转到步骤2。
52、步骤7):从每个unk的取值范围中选取一个确定的词,会有若干种选择结果,这些结果构成的集合即为该条带有unk的断言语句生成不带unk的断言语句的解空间;按照断言生成模块中制定的启发式规则为标准,深度遍历该解空间,求得符合这些规则unk的生成结果;
53、步骤8):用上述的unk生成结果取代断言语句中对应的unk,生成理论上可编译的断言语句;
54、步骤9):unk生成结束。
55、最后,效果分析模块的具体步骤如下:
56、步骤1):起始状态;
57、步骤2):计算预测准确率作为测试集的评估度量;
58、步骤3):随机抽取一部分数据,人工验证生成的断言能够编译;
59、步骤4):效果分析完毕。
60、本发明基于程序上下文分析技术,提出了一种生成可编译的断言的方法;在用神经机器翻译模型生成断言语句时,用spoon工具提取程序的上下文信息,并制定了一系列启发式规则用以限制词表;之后通过这些启发式规则求得模型生成的unk可能的取值,对其深度遍历求得满足上述启发式规则的解。最后通过统计预测准确率和通过编译的比例验证本发明的效果。为自动化测试工具生成更高质量的断言提供了方法,从而帮助测试人员更快的编写测试用例,节约了项目开发的时间和人力成本。
- 还没有人留言评论。精彩留言会获得点赞!