基于卷积Transformer联合的目标跟踪方法与流程
本发明属于模式识别与智能计算、图像处理的,特别涉及一种基于卷积transformer联合的目标跟踪方法。
背景技术:
1、视频目标跟踪是计算机视觉领域中一个重要的方向,在军事、医学、安防、无人驾驶等领域有广泛的应用。但是在实际工程中经常存在目标姿态变化、背景干扰、遮挡、尺度变化等情况影响跟踪效果。此外,算法是否满足实时性也是评价跟踪算法是否能够应用的重要指标。因此在满足实时性的前提下,提高算法在复杂场景中的跟踪精度具有重要意义。
2、近年来基于孪生网络的跟踪方法因其具有精度高、速度快的特点成为目标跟踪算法的主流方向。siamfc全面完整地将孪生网络引入目标跟踪中,将目标跟踪看作为简单的相似性度量问题。使用浅层网络alexnet提取特征,使用卷积度量两分支的相似性,为后续的发展提供了一个新的方向。siamrpn将检测领域中的区域提议网络引入到跟踪算法中,一定程度上解决了siamfc的尺度问题,跟踪精度和速度有了一定的提高,但是rpn的引入带来了部分超参,使得网络对于超参过于敏感。siamrpn++和siamdw通过深度分析孪生网络跟踪算法的特点,将骨干网络从浅层的alexnet、googlenet等推广到了深层的resnet,为后续的发展提供了扎实的基础。2020年同时期提出的siamfc++和siamcar算法再一次将目标检测中的anchor-free的策略引入到跟踪领域中,缓解了超参敏感的问题,提升了跟踪精度。2021年流行的transt、stark、trdimp等方法在孪生网路上引入了transformer进行特征的增强和融合,对算法的跟踪效果带来了较大幅度的提升。
3、然而,基于siamese网络的跟踪算法仅仅考虑响应图中最大响应点,而忽略了其他响应点重要性,没有对其进行综合考虑,这样可能会降低对目标位置预测的精确性。同时在尺度方面,大多数算法只取几个不同的系数对目标尺度进行预测或借鉴r-cnn中的回归思想对目标周围截取大量图像进行回归预测来定位目标的精确位置。前者算法只是对目标尺度乘以不同的尺度系数,并找出响应值最高的尺度框作为目标的最终位置,当目标发生较大尺度变化时缺少相应的尺度系数,预测能力显著降低;后者算法在回归预测环节提取大量图像样本特征,增加算法的运算量,降低算法效率。
4、虽然当前基于transformer的目标跟踪方法性能获得了极大的提高,但是目前为止其本质上只是简单使用transformer进行特征的增强和融合,没有充分利用transformer的长距离依赖属性,无法完全发挥出transformer的优势。此外transformer相对于卷积神经网络具有更高的计算量,导致相关算法的网络过于臃肿难以真正投入使用,而且因其长距离依赖属性导致在提取视觉特征时有天然的缺陷无法获取丰富的局部信息,而卷积神经网络恰好在此方面有一定优势。
技术实现思路
1、基于此,因此本发明的首要目地是提供一种基于卷积transformer联合的目标跟踪方法,该方法能够获得更好的跟踪效果和更快的跟踪速度。
2、本发明的另一个目地在于提供一种人基于卷积transformer联合的目标跟踪方法,该方法以卷积和窗口注意力串联的方式和层次化的结构构建了一个通用的目标跟踪骨干网络ctformer,利用互注意力机制构建了特征互增强与聚合网络简化了网络结构,降低计算量并提高跟踪速度;同时,结合目标运动速度估计提出自适应调整搜索区域的跟踪策略,进一步提高跟踪精度。
3、为实现上述目的,本发明的技术方案为:
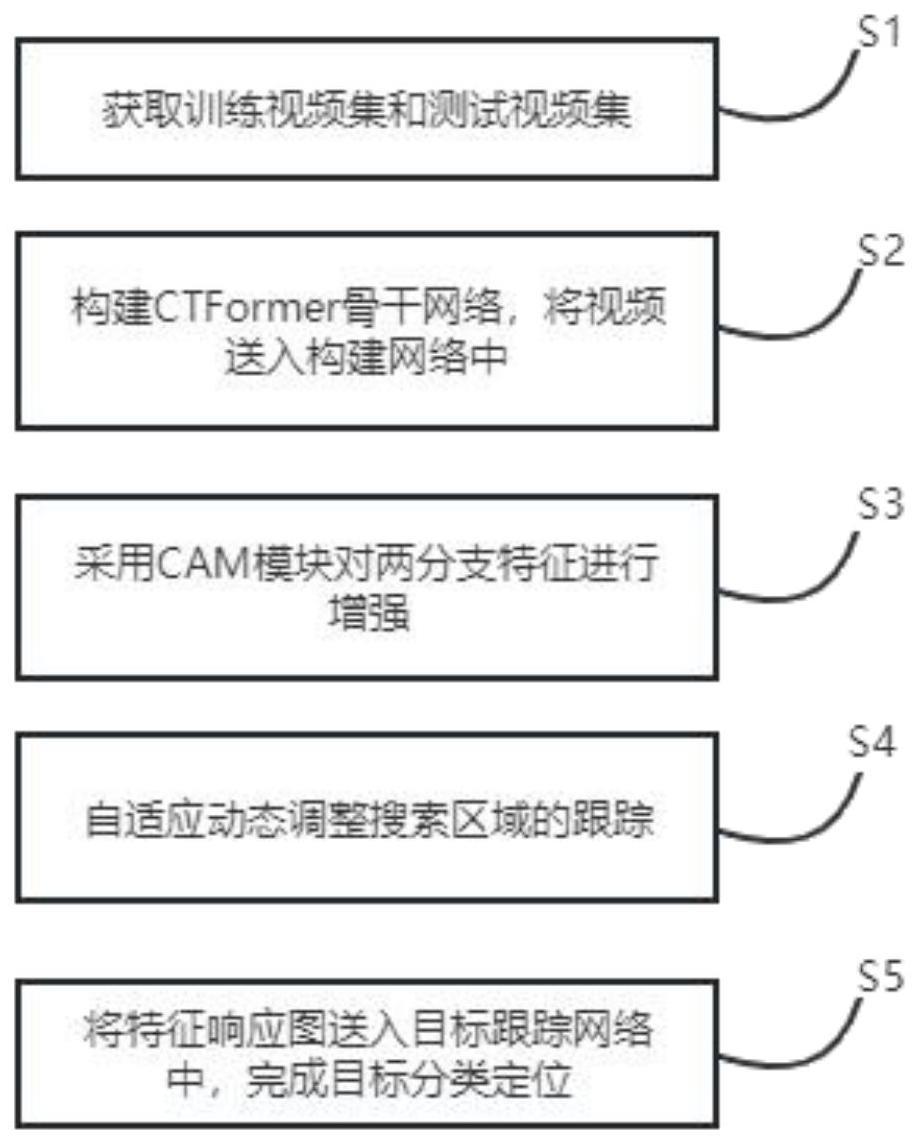
4、一种基于卷积transformer联合的目标跟踪方法,其特征在于包括以下步骤:
5、s1:获取训练视频集和测试视频集;
6、s2:构建ctformer骨干网络,将视频送入构建网络中;
7、s3:采用cam模块对两分支特征进行增强;
8、s4:自适应动态调整搜索区域的跟踪;
9、s5:将特征响应图送入目标跟踪网络中,完成目标分类定位。
10、本发明采用一种基于区域建议的回归模型,提取响应图中高于一定阈值的响应点,得到包含目标信息的候选图像,并放入训练好的回归模型进行位置预测,能够在不损失过多性能下降低算法复杂度,提升算法效率,同时还能提升目标位置准确性,能够获得更好的跟踪效果和更快的跟踪速度。
11、其中,s1步骤中:获取训练视频集和测试视频集;所述训练视频集和测试视频集从无人机目标跟踪视频数据集中获得。
12、s2步骤中:构建ctformer骨干网络,整个网络由浅层特征提取层、ctfromer模块、池化层组成,分为4个阶段,各个阶段的ctfromer模块数量设置为{2,2,8,2};其中浅层特征提取层直接使用efficientnetv2网络的前三个阶段来提取底层特征,同时调整该层输出通道数为96,总步长为4,特征图分辨率降低4倍;池化层为简单的2倍下采样并调整输出通道数为输入的2倍。
13、其中,卷积transformer结合的模块命名为ctfromer,所述ctfromer模块由归一化层(ln)、卷积层(conv)、多层感知器层(mlp)、窗口注意力层(wmsa)组成,其中xl为第l层的输入,xl+1为第l+1层输入也为第l层的输出,xl+2为第l+1层输出;具体计算过程如下所示:
14、
15、
16、
17、使用窗口注意力代替原transformer中计算量庞大的全局自注意力。其中窗口注意力层仅在固定尺寸为8的窗口内计算局部注意力,相对于全局注意力具有更小的计算量,虽然无法像全局注意力一样建模全局特性,但使用局部注意力相对全局注意力在实际跟踪任务中仅有细微的精度损失。为了弥补精度的损失,在前端接入了一个同样以卷积代替全局注意力的类transformer模块,二者串联成对出现组成ctfromer模块。
18、s3步骤中:采用cam模块对两分支特征进行增强;所述cam模块采用残差网络的思想结合多头互注意、归一化、前馈神经网络设计而成,整个cam模块的计算过程可以描述为如下所示:
19、
20、
21、其中xq为本分支的输入,pq为xq的空间位置编码,xkv为另一分支的输入,pkv为xkv的空间位置编码,位置编码均由正弦函数生成。进而可以通过多头互注意力(mhca)获得两分支的相似性后结合残差连接及归一化获得初步聚合增强后的本分支特征然后经过由两个线性变换和一个relu激活函数组成的前馈神经网络进行空间变换增加模型的表现能力、最终通过残差连接和归一化获得聚合增强后本分支特征xcam。
22、cam模块交叉使用,分别对两分支的特征进行增强,组成特征互增强与聚合网络。对其重复多次获取更具有判别性的特征,同时也可借助cam模块度量两分支的相似性,获得相应图。
23、s4步骤中:自适应动态调整搜索区域的跟踪;
24、首先设置初始搜索区域放大倍数为3,进行跟踪获取连续5帧的目标中心点位置(xi,yi)、(xi+1,yi+1)、(xi+2,yi+2)、(xi+3,yi+3),计算相邻两帧的中心点偏差如下式所示:
25、(△x1,△y1)=(|xi+1-xi|,|yi+1-yi|)
26、(△x2,△y2)=(|xi+2-xi+1|,|yi+2-yi+1|)
27、(△x3,△y3)=(|xi+3-xi+2|,|yi+3-yi+2|)
28、(△x4,△y1)=(|xi+4-xi+2|,|yi+4-yi+3|)
29、并计算相对于x轴和y轴运动距离的最大值如下式所示:
30、d1=max(△x1,△y1);d2=max(△x2,△y2)
31、d3=max(△x3,△y3);d4=max(△x4,△y4)
32、根据4个相邻两帧运动距离的最大值d1,d2,d3,d4调整搜索区域的放大倍数s。设置搜索区域放大倍数s和d1,d2,d3,d4的关系如下式所示:
33、
34、该策略相对于固定搜索区域放大倍数的策略具有更好的性能,而且能够减少大尺寸目标图像不必要的padding操作,提高推理速度。
35、与现有技术相比,本发明的有益效果如下:
36、本发明充分利用卷积神经网络与transfomer的特性,在特征提取方面,利用卷积丰富的局部信息和transformer的长距离依赖属性,以卷积和窗口注意力串联的方式和层次化的结构构建了一个通用的目标跟踪骨干网络ctformer;在特征融合方面,仅利用互注意力机制构建了特征互增强与聚合网络简化了网络结构,抛弃了繁琐的编码-解码过程,降低计算量并提高跟踪速度;在搜索区域选择方面,结合目标运动速度估计提出自适应调整搜索区域的跟踪策略,进一步提高跟踪精度。
37、实验表明本发明提高了特征提取的能力,增强了复杂环境下的跟踪效果,有效的提高了无人机跟踪准确率,具有良好的泛化能力和适用范围。
- 还没有人留言评论。精彩留言会获得点赞!