基于序列级前缀提示的生成式文本摘要方法和装置
本技术涉及文本摘要生成,尤其涉及一种基于序列级前缀提示的生成式文本摘要方法和装置。
背景技术:
1、当今人工智能已开始迈入数据与知识双轮驱动的认知智能时代,预训练语言模型( pre-trained language model,plm )作为ai界的代表性技术受到了广泛关注,其利用基于深度学习的数据驱动方法提升了自然语言处理等任务的算法效果和应用范式。近年来,plm在广泛的自然语言生成(natural language generation,nlg ) 任务中取得了巨大的成功,构建大规模的预训练语言模型已经成为处理日益复杂和多样化的语言任务的流行方法。文本摘要任务是nlg领域的代表性任务,该任务的目标是将长文本进行压缩、归纳和总结,从而形成具有概括性含义的短文本。近些年,随着互联网产生的文本数据越来越多,文本信息过载问题日益严重,网络中充斥着大量长而复杂的文本,对各类文本进行一个“降维”处理显得非常必要。文本摘要便是其中一个重要的手段,其可以让用户在当今世界海量的互联网数据中找到有效的信息,因此具备重大的研究与应用价值。
2、根据摘要方法的不同,文本摘要任务可以分为抽取式方法和生成式方法。其中,抽取式摘要直接从原文中选择若干条重要的句子,并对它们进行排序和重组而形成摘要,但抽取式摘要方法存在的缺陷是抽取出的句子之间衔接生硬,不够自然。由此近些年来该任务的研究重心已经偏移到了生成式摘要上。相较于抽取式摘要,生成式摘要在语法、句法上有一定的保证,并允许生成的摘要中包含新的词语或短语,灵活性高,但是也面临了一定的问题,例如:内容选择错误、生成内容不可控等问题。
3、近些年,预训练语言模型被广泛地用于自然语言生成任务,也涌现出一系列在有条件生成任务上具备优异性能的模型,在生成式文本摘要任务上取得优异表现。基于这类语言模型的方法将摘要表述为一个序列到序列问题,利用自回归方式生成摘要,采取最大似然估计来训练深层网络,使参考输出的预测概率最大化。然而,在推理过程中,模型可能会预测出一个错误的token(字符),并在往后的自回归预测中,模型会关注到已生成的错误信息从而造成预测偏差,这种偏差在生成过程中会不断放大,极大地损害模型的生成性能,这种现象通常被称为曝光偏差。在训练深层网络时使用极大似然估计来优化网络模型权重,这个策略会带来曝光偏差问题并无法优化序列的整体质量,使得生成的摘要逐渐偏离参考摘要。此外,在深层网络训练过程中会消耗大量的算力资源,这极大地增加了模型训练的时间成本与金钱成本。
技术实现思路
1、本技术旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本技术的第一个目的在于提出一种基于序列级前缀提示的生成式文本摘要方法,解决了现有方法存在曝光偏差以及算力成本高昂的技术问题,通过添加前缀网络并在训练过程中冻结深度神经网络的权重优化前缀网络,加快了训练过程并大大降低了计算量,此外,通过设计对比学习模块并引入候选摘要指导前缀网络学习多种潜在生成序列的语义信息,使前缀网络具备序列级语义提示信息,以此提高了生成摘要的准确性。
3、本技术的第二个目的在于提出一种基于序列级前缀提示的生成式文本摘要装置。
4、本技术的第三个目的在于提出一种计算机设备。
5、本技术的第四个目的在于提出一种非临时性计算机可读存储介质。
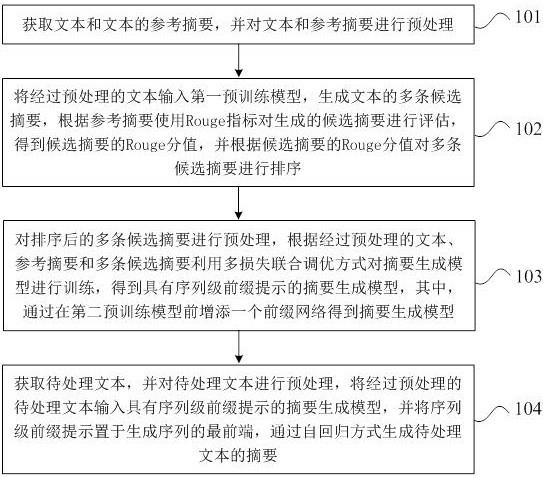
6、为达上述目的,本技术第一方面实施例提出了一种基于序列级前缀提示的生成式文本摘要方法,包括:获取文本和文本的参考摘要,并对文本和参考摘要进行预处理;将经过预处理的文本输入第一预训练模型,生成文本的多条候选摘要,根据参考摘要使用rouge指标对生成的候选摘要进行评估,得到候选摘要的rouge分值,并根据候选摘要的rouge分值对多条候选摘要进行排序;对排序后的多条候选摘要进行预处理,根据经过预处理的文本、参考摘要和多条候选摘要利用多损失联合调优方式对摘要生成模型进行训练,得到具有序列级前缀提示的摘要生成模型,其中,通过在第二预训练模型前增添一个前缀网络得到摘要生成模型;获取待处理文本,并对待处理文本进行预处理,将经过预处理的待处理文本输入具有序列级前缀提示的摘要生成模型,并将序列级前缀提示置于生成序列的最前端,通过自回归方式生成待处理文本的摘要。
7、可选地,在本技术的一个实施例中,对文本和参考摘要进行预处理,包括:
8、分别对文本和参考摘要进行分词,并过滤特殊字符,得到文本的字符序列和参考摘要的字符序列。
9、可选地,在本技术的一个实施例中,将经过预处理的文本输入第一预训练模型,生成文本的多条候选摘要,包括:
10、将预处理得到的文本的字符序列输入第一预训练模型,利用beamsearch策略进行采样生成,得到文本的多条候选摘要。
11、可选地,在本技术的一个实施例中,根据经过预处理的文本、参考摘要和多条候选摘要利用多损失联合调优方式对摘要生成模型进行训练,得到具有序列级前缀提示的摘要生成模型,包括:
12、通过引入对比学习范式,计算多条候选摘要与参考摘要之间的相似度分值作为对比损失;
13、计算摘要生成模型生成的摘要和参考摘要的负对数似然之和作为交叉熵损失;
14、将对比损失与交叉熵损失进行加权,得到摘要生成模型的联合损失函数;
15、根据联合损失函数对摘要生成模型进行训练,得到具有序列级前缀提示的摘要生成模型。
16、可选地,在本技术的一个实施例中,根据联合损失函数对摘要生成模型进行训练,得到具有序列级前缀提示的摘要生成模型,包括:
17、冻结摘要生成模型的第二预训练模型的权重,通过联合损失函数对摘要生成模型的前缀网络进行训练,以将前缀网络分解为序列级前缀提示,得到具有序列级前缀提示的摘要生成模型,并将第二预训练模型的词表作为具有序列级前缀提示的摘要生成模型的词表,其中,通过引入对比损失函数对前缀网络进行训练,使前缀网络拥有序列级信息。
18、可选地,在本技术的一个实施例中,对比损失的公式表示为:
19、
20、其中,表示对比损失,表示第i个候选摘要,表示第j个候选摘要,表示长度归一化后的对数概率之和,表示第i个候选摘要和第j个候选摘要的rouge分值差额乘以第i个候选摘要和第j个候选摘要的等级差;
21、交叉熵损失的公式表示为:
22、
23、其中,表示交叉熵损失,表示交叉熵框架下的one-hot编码,s表示生成的下一位置的摘要字符,d表示预处理得到的字符序列,表示第1到j-1个参考摘要的字符序列,表示摘要生成模型g映射下的概率表示,表示摘要生成模型g的参数;
24、联合损失函数表示为:
25、=+
26、其中,表示联合损失函数,表示交叉熵损失,表示对比损失,γ是对比损失的权重系数。
27、可选地,在本技术的一个实施例中,将经过预处理的待处理文本输入具有序列级前缀提示的摘要生成模型,并将序列级前缀提示置于生成序列的最前端,通过自回归方式生成待处理文本的摘要,包括:
28、将经过预处理得到的待处理文本的字符序列输入具有序列级前缀提示的摘要生成模型,根据序列级前缀提示通过自回归方式逐个预测所有位置的摘要字符,以生成待处理文本的摘要,其中,根据序列级前缀提示、当前位置之前的摘要字符和待处理文本的字符序列,计算当前位置的词表中字符的概率分布,并选取概率最大的字符作为当前位置的摘要字符。
29、为达上述目的,本技术第二方面实施例提出了一种基于序列级前缀提示的生成式文本摘要装置,包括:
30、获取模块,用于获取文本和文本的参考摘要,并对文本和参考摘要进行预处理;
31、第一生成模块,用于将经过预处理的文本输入第一预训练模型,生成文本的多条候选摘要,根据参考摘要使用rouge指标对生成的候选摘要进行评估,得到候选摘要的rouge分值,并根据候选摘要的rouge分值对多条候选摘要进行排序;
32、训练模块,用于对排序后的多条候选摘要进行预处理,根据经过预处理的文本、参考摘要和多条候选摘要利用多损失联合调优方式对摘要生成模型进行训练,得到具有序列级前缀提示的摘要生成模型,其中,通过在第二预训练模型前增添一个前缀网络得到摘要生成模型;
33、第二生成模块,用于获取待处理文本,并对待处理文本进行预处理,将经过预处理的待处理文本输入具有序列级前缀提示的摘要生成模型,并将序列级前缀提示置于生成序列的最前端,通过自回归方式生成待处理文本的摘要。
34、为达上述目的,本技术第三方面实施例提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时,实现上述施例所述的基于序列级前缀提示的生成式文本摘要方法。
35、为了实现上述目的,本技术第四方面实施例提出了一种非临时性计算机可读存储介质,当所述存储介质中的指令由处理器被执行时,能够执行一种基于序列级前缀提示的生成式文本摘要方法。
36、本技术实施例的基于序列级前缀提示的生成式文本摘要方法、装置、计算机设备和非临时性计算机可读存储介质,解决了现有方法存在曝光偏差以及算力成本高昂的技术问题,通过添加前缀网络并在训练过程中冻结深度神经网络的权重优化前缀网络,加快了训练过程并大大降低了计算量,此外,通过设计对比学习模块并引入候选摘要指导前缀网络学习多种潜在生成序列的语义信息,使前缀网络具备序列级语义提示信息,以此提高了生成摘要的准确性。
37、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!