面向资源受限存算一体芯片的DNN推理加速系统及方法
本发明涉及存算一体芯片,尤其涉及一种面向资源受限存算一体芯片的dnn推理加速系统及方法。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、深度神经网络(deep neural network,dnn)已被广泛应用于图像识别、自然语言处理及目标检测等技术,但这些dnn在带来高精度的同时也伴随着数以亿计的权重需要存储及计算。例如,vgg16是一个典型的dnn模型,top-5准确率高达92.7%,但其权重大小约为548mb,每识别一张图片需要1.5×1010次乘法。对于以传统的冯·诺依曼结构为基础的现代计算机系统,运行如此大规模的dnn模型,需要在存储单元和计算单元之间反复传输大量数据,造成巨大的延迟和能量损耗,从而限制了数据处理的效率。
3、存内计算(process-in-memory,pim)技术是为了克服传统冯·诺依曼结构带来的计算限制而被提出的,其不需要将数据从存储器传输到处理器,而是直接将运算部分整合到存储阵列内部执行计算。这种技术消除了内存和处理器之间的数据传输,因此,其在ai各个领域的应用正在被广泛探索。
4、新型非易失存储器(non-volatile memory,nvm),包括静态随机存储器(staticrandom-access memory,sram)、相变存储器(phase change memory,pcm)、磁阻式存储器(magnetoresistive random access memory,mram)、电阻式/阻变存储器(resistiverandom access memory,reram)等,都可以用于存内计算技术。其中reram具有与dram相似的访问性能,同时支持矩阵向量乘法(matrix-vector multiplication,mvm)的就地计算,在过去几年中,已有多项工作对基于reram的dnn加速器进行了探索。
5、随着对基于reram的dnn加速器的探索不断深入,reram加速dnn的潜力也持续被发掘:从基于reram的微体系结构的设计,到符合reram特点的神经网络推理甚至训练过程流水线的设计,再到针对reram的dnn权重的剪枝量化与重用,优化方法由浅入深,层出不穷。然而,这些方法都理想化的认为可以在一个时钟周期内进行整个crossbar的计算。实际上,reram各个单元中的电流在累积过程中产生的偏差会严重影响神经网络的推理精度,因此,有工作提出了一种更实际的结构,每个周期只激活每个crossbar的一小片区域(也称为operation unit,ou)。之后又有作者进一步提出了基于ou的剪枝及重用方法,来减少基于此结构的reram的面积需求及计算开销。
6、然而,过去所有工作都假设reram的资源足够大,以至于dnn的权重可以一次性全部编程到reram中,且编程时延可以忽略不计。但集成电路设计领域的最新的研究显示,面积受限的嵌入式设备或边缘设备上的reram的芯片容量远远小于当前dnn的权重大小。
7、发明人发现,在进行dnn的推理之前,不可能在离线状态下将神经网络的所有权重全部部署到芯片上,而是需要在线多次部署,每次只能部署一部分权重;权重多次在线部署过程的开销,可能会降低dnn在reram中的推理速度。
技术实现思路
1、为了解决上述问题,本发明提出了一种面向资源受限存算一体芯片的dnn推理加速系统及方法,综合考虑符合现实情况的reram芯片资源以及reram芯片自身的编程特点,极大的提高了资源受限下dnn在reram上的推理速度。
2、在一些实施方式中,采用如下技术方案:
3、一种面向资源受限存算一体芯片的dnn推理加速系统,包括:
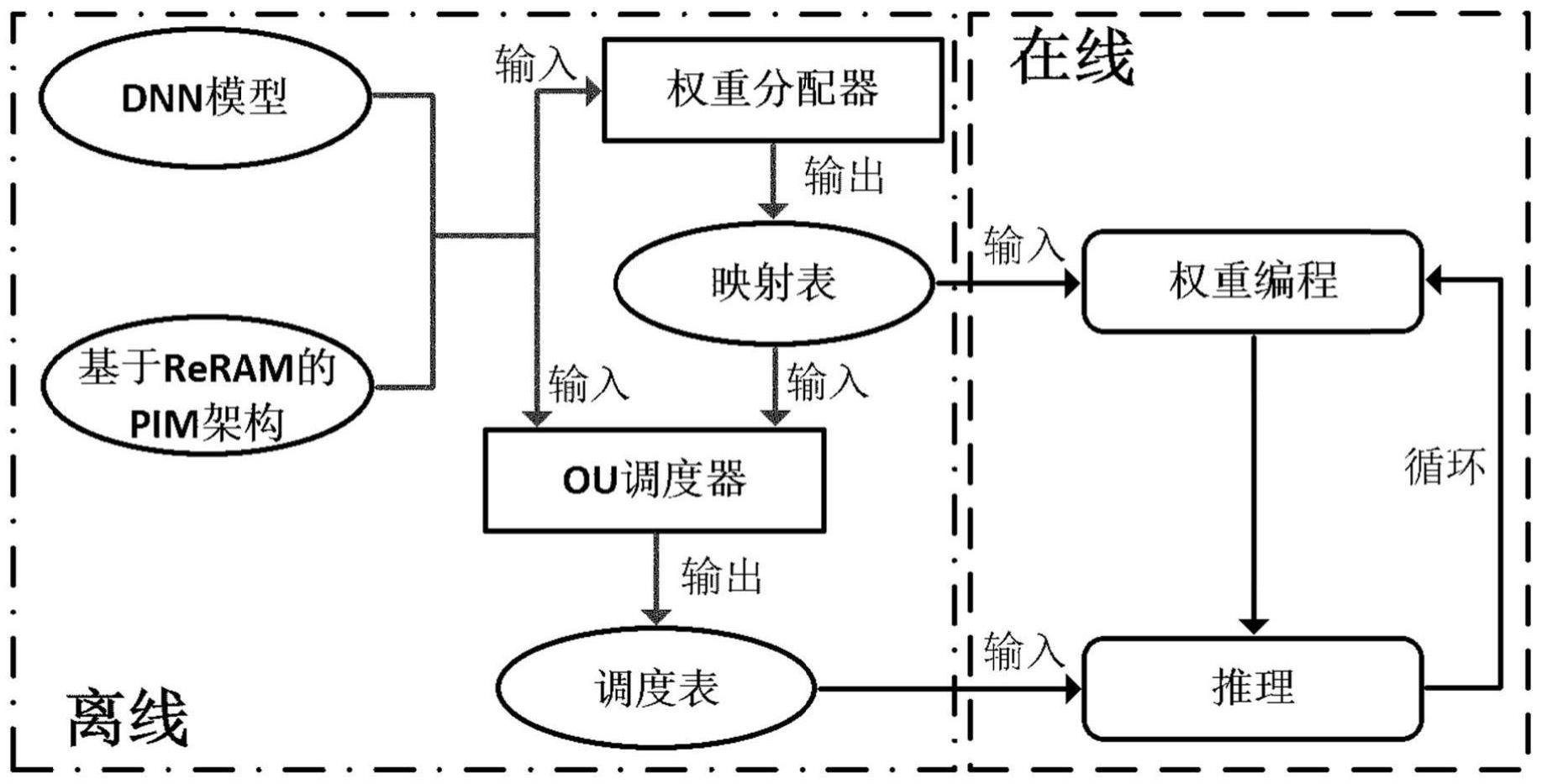
4、权重分配模块,用于在离线状态下获取神经网络信息和reram结构信息,生成一个ou大小的权重块到物理ou的映射表,映射表用来存储神经网络权重在reram上每次部署时,各个ou位置的权重块信息;
5、ou调度模块,用于在离线状态下将神经网络信息、reram结构及映射表信息输入到ou调度器,生成调度表;ou调度器对每个神经网络层的输入特征向量进行排序,并转换为相应crossbar的输入电压;所述调度表用来保存每个ou的运行次数及运行顺序,并控制特征向量的输入以及运行后结果的输出位置;
6、权重编程模块,用于在线状态下根据生成的映射表,将ou大小的权重块写入指定的物理ou中;
7、推理模块,用于在线状态下读取所述调度表,用相应的输入特征向量激活ou上的计算;
8、所述权重编程模块和推理模块迭代运行,直到对所有给定的输入数据完成dnn推理。
9、进一步地,所述权重编程模块每次编程reram设备容量大小的神经网络权重到硬件设备上,硬件设备含有多个crossbar,每个crossbar每个权重部署阶段都有一个相应的映射表。
10、reram上的各个crossbar是并行运行的,每个crossbar在同一时刻只有一个ou被激活进行计算,且每个crossbar在每个推理阶段都有一个相应的调度表。
11、reram上的各个crossbar通过读取调度表中的数据,获取需要激活的ou位置以及该ou本次计算的输入特征向量,通过将输入特征向量转换为电压输入到该ou的位线上,得到本次计算的结果,获取调度表中的输出特征向量信息,将计算结果传输到相应的位置存储。
12、在另一些实施方式中,采用如下技术方案:
13、一种面向资源受限存算一体芯片的dnn推理加速系统的dnn推理加速方法,包括:
14、基于reram的编程时延模型,得到编程时延的优化策略;所述优化策略包括:相似度匹配策略、均衡映射策略和距离感知策略;
15、将训练后的神经网络的权重量化为整数,将神经网络权重划分为reram大小的部署层,并将每个部署层的权重以ou为单位分成权重块;
16、基于相似度匹配策略、均衡映射策略和距离感知策略,生成每一个权重块到物理ou的映射表;
17、基于神经网络结构及量化后的权重信息、reram结构以及映射表信息,生成调度表;
18、上述过程在离线状态下实现。
19、进一步地,所述reram的编程时延模型具体为:将reram的编程时延单位由小到大分解为单次编程时延、单ou编程时延、单crossbar编程时延和整个reram的编程时延;
20、其中,单ou编程时延为该ou中所有单次编程时延的总和,单crossbar编程时延为该crossbar中所有ou编程时延的总和,整个reram的编程时延为编程时延最大的单crossbar编程时延。
21、所述相似度匹配策略具体为:利用ou的相似性减少全局reset操作次数:在单次编程操作中,并行操作的所有单元都不需要从1到0的reset操作时,该操作可省略。
22、所述均衡映射策略具体为:
23、通过调整ou的相似度匹配顺序,实现各个crossbar编程时延的均衡。
24、所述距离感知策略具体为:对完成相似度匹配的ou的位置进行调整,将操作频繁的ou调整到该crossbar中reset编程时延较小的位置,从而降低单crossbar编程时延。
25、与现有技术相比,本发明的有益效果是:
26、(1)本发明提供了一种面向资源受限存算一体芯片的dnn推理加速系统,利用权重分配模块生成的映射表和ou调度模块生成的调度表的信息,合理安排ou的激活顺序、次数及输入输出数据的传输,从而实现dnn在资源受限的reram芯片上的准确高速推理。
27、(2)在资源受限的reram加速器上部署整个dnn是不切实际的。单个神经网络的推理需要进行多次权重部署,而权重部署过程非常耗时。因此,本发明通过对reram编程时延进行分解,深入探究影响编程时延的因素,对reram的编程时延进行了建模。基于reram编程时延的建模公式,提出了面向资源受限存算一体芯片的dnn推理加速方法,该方法包括相似度匹配策略、平衡映射策略和距离感知策略,这三个策略分别对单ou编程时延、单crossbar编程时延和整个reram的编程时延进行了优化,极大的加速了dnn在资源受限的reram芯片上的推理。
28、本发明的其他特征和附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本方面的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!