双阶段视频去噪模型训练方法、视频去噪方法和系统
本技术涉及图像与视频信息处理,尤其涉及双阶段视频去噪模型训练方法、视频去噪方法和系统。
背景技术:
1、视频作为一种广泛使用的媒体,比文字和图像包含更多有用的信息,不仅具有单张图像空间信息,还具有帧与帧之间的时序信息。然而,在生产和生活的具体应用中,视频采集、视频压缩和视频编码等一系列视频处理过程中,可能会受到环境因素和设备条件的影响带来很多噪声,如低光照度、图像传感器尺寸不一致等因素,从而导致视频质量下降。因此,视频去噪作为计算机视觉中的一项基础工作,目标是在去除干扰噪声的同时保持原始视频的基本视觉内容。同时视频去噪的结果可以极大地影响后续下游任务对视频数据的识别和理解,例如老电影修复、视频监控等,因此吸引了大量的学者对其进行研究。
2、目前,现有的视频去噪方法主要分为三类,包括基于图像块(patch)的传统方法、显式运动补偿方法和非显式运动补偿方法。然而,现有的视频去噪方法所采用的直接对空间和时间维度信息进行简单叠加的训练过程,会使得训练得到的视频去噪模型出现去噪效果较差的问题。
技术实现思路
1、鉴于此,本技术实施例提供了双阶段视频去噪模型训练方法、视频去噪方法和系统,以消除或改善现有技术中存在的一个或更多个缺陷。
2、本技术的一个方面提供了一种双阶段视频去噪模型训练方法,包括:
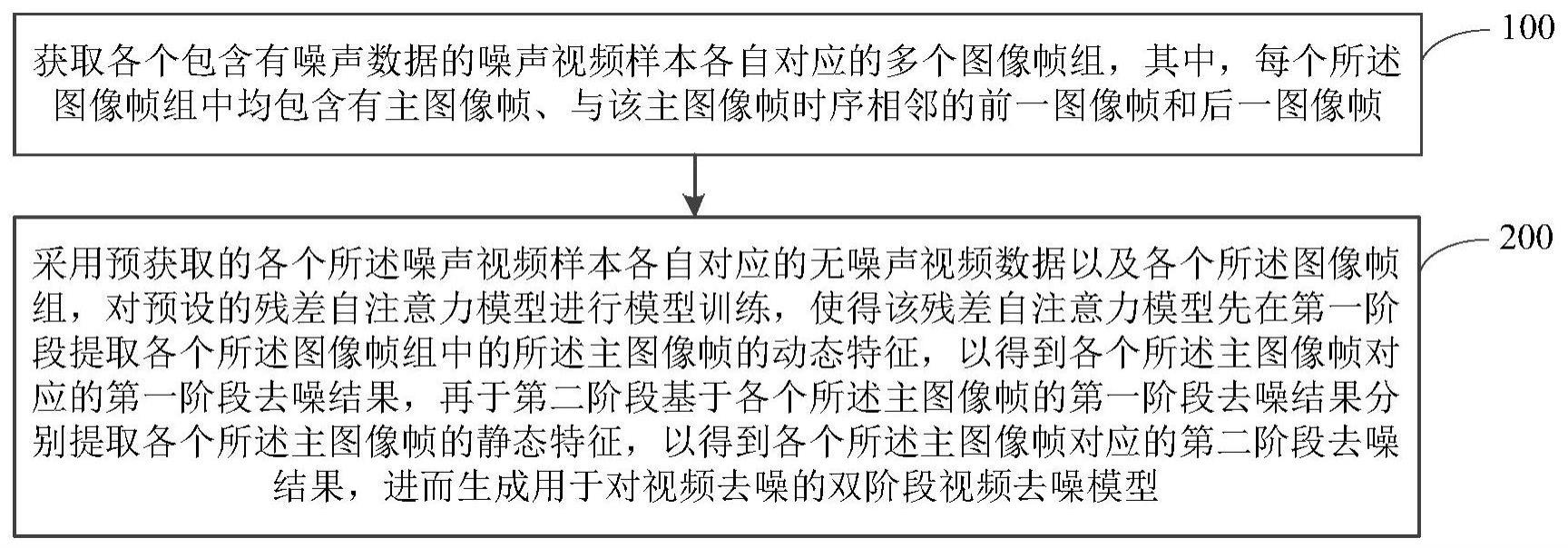
3、获取各个包含有噪声数据的噪声视频样本各自对应的多个图像帧组,其中,每个所述图像帧组中均包含有主图像帧、与该主图像帧时序相邻的前一图像帧和后一图像帧;
4、采用预获取的各个所述噪声视频样本各自对应的无噪声视频数据以及各个所述图像帧组,对预设的残差自注意力模型进行模型训练,使得该残差自注意力模型先在第一阶段提取各个所述图像帧组中的所述主图像帧的动态特征,以得到各个所述主图像帧对应的第一阶段去噪结果,再于第二阶段基于各个所述主图像帧的第一阶段去噪结果分别提取各个所述主图像帧的静态特征,以得到各个所述主图像帧对应的第二阶段去噪结果,进而生成用于对视频去噪的双阶段视频去噪模型。
5、在本技术的一些实施例中,所述残差自注意力模型包括:
6、第一阶段网络,用于提取各个所述图像帧组中的所述主图像帧、前一图像帧和后一图像帧各自对应的全局动态特征,并对每个所述图像帧组中的所述主图像帧、前一图像帧和后一图像帧各自对应的全局动态特征进行特征融合处理,以得到各个所述主图像帧的动态特征;再对各个所述主图像帧的动态特征进行像素重组,得到各个所述主图像帧对应的第一阶段去噪结果;
7、第二阶段网络,与所述第一阶段网络的输出端相连,用于分别提取各个所述第一阶段去噪结果各自对应的主图像帧的静态特征,再对各个所述主图像帧的静态特征进行下采样,得到各个所述主图像帧对应的第二阶段去噪结果。
8、在本技术的一些实施例中,所述第一阶段网络包括:
9、第一编码器模块,用于采用卷积神经网络和自注意力机制提取各个所述图像帧组中的所述前一图像帧的全局动态特征;
10、第二编码器模块,用于采用卷积神经网络和自注意力机制提取各个所述图像帧组中的所述主图像帧的全局动态特征;
11、第三编码器模块,用于采用卷积神经网络和自注意力机制提取各个所述图像帧组中的所述后一图像帧的全局动态特征;
12、特征融合模块,分别连接所述第一编码器模块、第二编码器模块和第三编码器模块的输出端,所述特征融合模块用于对每个所述图像帧组中的所述主图像帧、前一图像帧和后一图像帧各自对应的全局动态特征进行特征融合处理,以得到各个所述主图像帧的动态特征;
13、第一解码器模块,与所述特征融合模块的输出端连接,还与所述第二编码器模块之间采用残差连接,所述第一解码器模块用于采用卷积神经网络对各个所述主图像帧的动态特征进行像素重组,得到各个所述主图像帧对应的第一阶段去噪结果。
14、在本技术的一些实施例中,所述第二阶段网络包括:
15、第四编码器模块,与所述第一阶段网络的输出端相连,用于采用卷积神经网络和自注意力机制分别提取各个所述第一阶段去噪结果各自对应的主图像帧的静态特征;
16、第二解码器模块,与所述第四编码器模块之间采用残差连接,所述第二解码器模块用于采用卷积神经网络对各个所述主图像帧的静态特征进行下采样,得到各个所述主图像帧对应的第二阶段去噪结果。
17、在本技术的一些实施例中,所述第一编码器模块、第二编码器模块、第三编码器模块和第四编码器模块均包括:依次连接的特征提取模型和两个下采样模型;
18、所述特征提取模型包括一卷积神经网络,用于提取图像帧的初始特征;
19、所述下采样模型包括:依次连接的下采样层、卷积神经网络和自注意力模块,用于根据取所述图像帧的初始特征进行下采样处理并提取所述图像帧的全局动态特征,其中,所述卷积神经网络包括:多个依次连接的卷积层。
20、在本技术的一些实施例中,所述第一解码器模块和第二解码器模块均包括:依次连接的两个上采样模型和特征提取模型;
21、所述上采样模型包括:相互连接的一卷积神经网络和上采样层,用于基于像素重组策略对各个所述主图像帧的动态特征进行上采样处理;
22、所述特征提取模型包括一卷积神经网络,用于根据经下采样处理后的各个所述主图像帧的动态特征获取各个所述主图像帧对应的去噪结果,其中,所述卷积神经网络包括:多个依次连接的卷积层。
23、本技术的另一个方面一种视频去噪方法,包括:
24、获取目标视频对应的多个图像帧组,其中,每个所述图像帧组中均包含有主图像帧、与该主图像帧时序相邻的前一图像帧和后一图像帧;
25、将所述目标视频对应的多个图像帧组输入预先基于所述的双阶段视频去噪模型训练方法训练得到的双阶段视频去噪模型中,以使该双阶段视频去噪模型输出所述目标视频对应的第二阶段去噪结果。
26、本技术的第三个方面提供了一种双阶段视频去噪模型训练系统,包括:
27、图像帧提取模块,用于获取各个包含有噪声数据的噪声视频样本各自对应的多个图像帧组,其中,每个所述图像帧组中均包含有主图像帧、与该主图像帧时序相邻的前一图像帧和后一图像帧;
28、双阶段模型训练模块,用于采用预获取的各个所述噪声视频样本各自对应的无噪声视频数据以及各个所述图像帧组,对预设的残差自注意力模型进行模型训练,使得该残差自注意力模型先在第一阶段提取各个所述图像帧组中的所述主图像帧的动态特征,以得到各个所述主图像帧对应的第一阶段去噪结果,再于第二阶段基于各个所述主图像帧的第一阶段去噪结果分别提取各个所述主图像帧的静态特征,以得到各个所述主图像帧对应的第二阶段去噪结果,进而生成用于对视频去噪的双阶段视频去噪模型。
29、本技术的第四个方面提供了一种视频去噪系统,包括:
30、图像帧获取模块,用于获取目标视频对应的多个图像帧组,其中,每个所述图像帧组中均包含有主图像帧、与该主图像帧时序相邻的前一图像帧和后一图像帧;
31、双阶段模型去噪模块,用于将所述目标视频对应的多个图像帧组输入预先基于所述的双阶段视频去噪模型训练方法训练得到的双阶段视频去噪模型中,以使该双阶段视频去噪模型输出所述目标视频对应的第二阶段去噪结果。
32、本技术的第五个方面提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述的双阶段视频去噪模型训练方法,或者,实现所述的视频去噪方法。
33、本技术的第六个方面提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述的双阶段视频去噪模型训练方法,或者,实现所述的视频去噪方法。
34、本技术提供的双阶段视频去噪模型训练方法,通过获取各个包含有噪声数据的噪声视频样本各自对应的多个图像帧组,其中,每个所述图像帧组中均包含有主图像帧、与该主图像帧时序相邻的前一图像帧和后一图像帧;采用预获取的各个所述噪声视频样本各自对应的无噪声视频数据以及各个所述图像帧组,对预设的残差自注意力模型进行模型训练,使得该残差自注意力模型先在第一阶段提取各个所述图像帧组中的所述主图像帧的动态特征,以得到各个所述主图像帧对应的第一阶段去噪结果,再于第二阶段基于各个所述主图像帧的第一阶段去噪结果分别提取各个所述主图像帧的静态特征,以得到各个所述主图像帧对应的第二阶段去噪结果,进而生成用于对视频去噪的双阶段视频去噪模型,本技术能够从两个阶段分别针对时间和空间两个维度的不同特点进行动态特征和静态特征的提取,用一阶段捕获动态信息得到初步的去噪结果,利用二阶段捕获静态信息得到最终的去噪结果,相比于直接对空间和时间信息一起进行去噪的单一阶段的方法,考虑到时间和空间两个维度的不同特点,从而使得去噪结果更为鲁棒;同时,通过采用残差自注意力模型,能够在去噪的过程中保留更多的全局上下文特征和局部信息,使去噪结果更为显著,能够有效提高训练得到的视频去噪模型的性能,进而能够有效提高双阶段视频去噪模型输出的视频去噪结果的鲁棒性、显著性及可靠性。
35、本技术的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本技术的实践而获知。本技术的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
36、本领域技术人员将会理解的是,能够用本技术实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本技术能够实现的上述和其他目的。
- 还没有人留言评论。精彩留言会获得点赞!