一种目标比对学习模型的建立、文本聚类方法及装置与流程
本技术涉及人工智能,特别涉及一种目标比对学习模型的建立、文本聚类方法及装置。
背景技术:
1、文本聚类是指对文档或文本进行的聚类分析,被广泛用于文本挖掘和信息检索领域。通过对文件进行聚类分析,可以确定出高频出现的文本,从而可以警醒有关部门,以从根源上解决高频出现的文本的问题。
2、基于现有的文本聚类方法,无法以较少的训练数据实现语义级别的文本聚类,文本聚类的准确性和效率较低。
3、针对上述技术问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术的目的是提供一种目标比对学习模型的建立、文本聚类方法及装置,以解决现有的文本聚类方法无法兼顾文本聚类的准确性和效率的问题。
2、本说明书提供了一种目标比对学习模型的建立方法,包括:
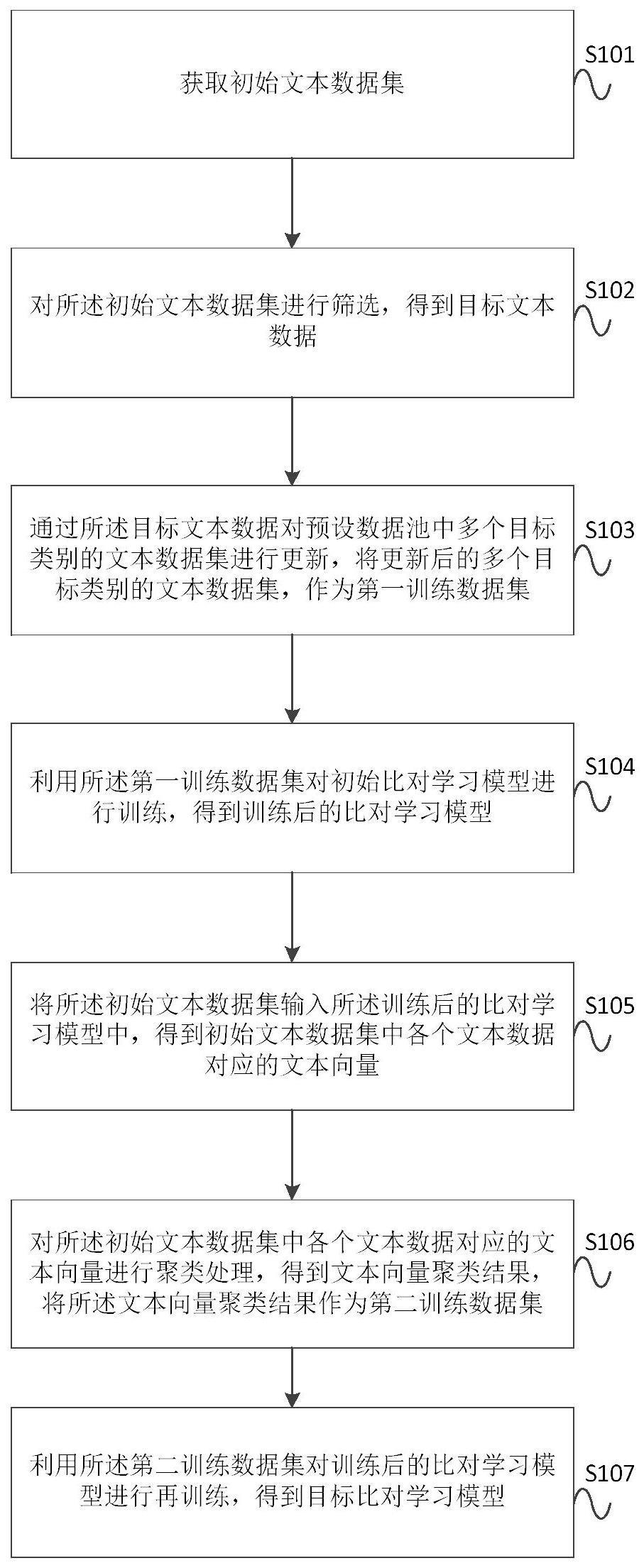
3、获取初始文本数据集;
4、对所述初始文本数据集进行筛选,得到目标文本数据;
5、通过所述目标文本数据对预设数据池中多个目标类别的文本数据集进行更新,将更新后的多个目标类别的文本数据集,作为第一训练数据集;
6、利用所述第一训练数据集对初始比对学习模型进行训练,得到训练后的比对学习模型;
7、将所述初始文本数据集输入所述训练后的比对学习模型中,得到初始文本数据集中各个文本数据对应的文本向量;
8、对所述初始文本数据集中各个文本数据对应的文本向量进行聚类处理,得到文本向量聚类结果,将所述文本向量聚类结果作为第二训练数据集;
9、利用所述第二训练数据集对训练后的比对学习模型进行再训练,得到目标比对学习模型。
10、在一个实施例中,所述对所述初始文本数据集进行筛选,得到目标文本数据,包括:
11、对所述初始文本数据集进行分词合并处理,得到多个不同分词;
12、从所述初始文本数据集中,确定包含所述多个不同分词中各分词对应的文本数据集,作为第一文本数据集;
13、对所述初始文本数据集和所述第一文本数据集进行筛选,得到目标文本数据。
14、在一个实施例中,所述对初始文本数据集和第一文本数据集进行筛选,得到目标文本数据,包括:
15、从所述初始文本数据集,获取待筛选文本数据;
16、从所述第一文本数据集中,获取除待筛选文本数据外的高频文本数据;
17、将所述待筛选文本数据与所述高频文本数据进行相似度计算;
18、在所述待筛选文本数据与所述高频文本数据的相似度计算结果大于预设阈值时,将所述待筛选文本数据作为目标文本数据。
19、在一个实施例中,所述通过所述目标文本数据对预设数据池中多个目标类别的文本数据集进行更新,包括:
20、计算所述目标文本数据与预设数据池中多个目标类别的文本数据集中各个目标类别的文本数据集中文本数据的相似度;
21、根据所述目标文本数据与所述各个目标类别的文本数据集中文本数据的相似度的计算结果,对预设数据池中多个目标类别的文本数据集进行更新。
22、在一个实施例中,所述根据目标文本数据与各个目标类别的文本数据集中文本数据的相似度的计算结果,对预设数据池中多个目标类别的文本数据集进行更新,包括:
23、在所述目标文本数据与所述各个目标类别的文本数据集中文本数据的相似度的计算结果均小于预设阈值时,将所述目标文本数据作为单一类别;
24、基于单一类别的目标文本数据对预设数据池中多个目标类别的文本数据集进行更新。
25、在一个实施例中,所述根据目标文本数据与各个目标类别的文本数据集中文本数据的相似度的计算结果,对预设数据池中多个目标类别的文本数据集进行更新,还包括:
26、在所述目标文本数据与所述各个目标类别的文本数据集中文本数据的相似度的计算结果不小于预设阈值时,确定是否存在第二目标类别,其中,所述第二目标类别在预设数据池的多个目标类别中,所述目标文本数据与所述第二目标类别中的文本数据的相似度计算结果均大于预设阈值;
27、在确定存在第二目标类别时,将所述目标文本数据加入至第二目标类别中对第二目标类别的文本数据进行更新,得到更新后的第二目标类别的文本数据;
28、基于更新后的第二目标类别的文本数据对预设数据池中多个目标类别的文本数据集进行更新。
29、本说明书还提供了一种文本聚类方法,包括:
30、获取待聚类文本数据集;
31、通过上述的目标比对学习模型,将所述待聚类文本数据集转换为文本向量;
32、对所述文本向量进行聚类处理,得到待聚类文本数据集的聚类结果。
33、本说明书还提供了一种目标比对学习模型的建立装置,包括:
34、第一获取模块,用于获取初始文本数据集;
35、筛选模块,用于对所述初始文本数据集进行筛选,得到目标文本数据;
36、一次训练模块,用于通过所述目标文本数据对预设数据池中多个目标类别的文本数据集进行更新,将更新后的多个目标类别的文本数据集,作为第一训练数据集;利用所述第一训练数据集对初始比对学习模型进行训练,得到训练后的比对学习模型;
37、二次训练模块,用于将所述初始文本数据集输入所述训练后的比对学习模型中,得到初始文本数据集中各个文本数据对应的文本向量;对所述初始文本数据集中各个文本数据对应的文本向量进行聚类处理,得到文本向量聚类结果,将所述文本向量聚类结果作为第二训练数据集;利用所述第二训练数据集对训练后的比对学习模型进行再训练,得到目标比对学习模型。
38、本说明书还提供了一种文本聚类装置,包括:
39、第二获取模块,用于获取待聚类文本数据集;
40、转换模块,用于通过上述的目标比对学习模型,将所述待聚类文本数据集转换为文本向量;
41、聚类模块,用于对所述文本向量进行聚类处理,得到待聚类文本数据集的聚类结果。
42、本说明书还提供了一种目标比对学习模型的建立设备,包括处理器以及用于存储处理器可执行指令的存储器,所述处理器执行所述指令时实现本说明书实施例中任意一个目标比对学习模型的建立方法实施例的步骤。
43、本说明书还提供了一种文本聚类设备,包括处理器以及用于存储处理器可执行指令的存储器,所述处理器执行所述指令时实现本说明书实施例中任意一个文本聚类方法实施例的步骤。
44、本说明书还提供了一种计算机可读存储介质,其上存储有计算机指令,所述计算机可读存储介质执行所述指令时实现上述目标比对学习模型的建立方法、实现上述文本聚类方法。
45、本说明书还提供了一种计算机程序产品,包含有计算机程序,所述计算机程序被处理器执行所述指令时实现上述目标比对学习模型的建立方法、实现上述文本聚类方法。
46、本说明书提供的一种目标比对学习模型的建立方法,首先,获取初始文本数据集;其次,对所述初始文本数据集进行筛选,得到目标文本数据,通过对初始文本数据集进行筛选,可以得到有价值的文本数据,提高后续对目标文本数据进行划分的效率;通过所述目标文本数据对预设数据池中多个目标类别的文本数据集进行更新,将更新后的多个目标类别的文本数据集,作为第一训练数据集,通过获取更新后的多个目标类别的文本数据集可以减少训练数据集的数据量,为后续提高模型训练效率奠定基础;进一步,利用所述第一训练数据集对初始比对学习模型进行训练,得到训练后的比对学习模型;将所述初始文本数据集输入所述训练后的比对学习模型中,得到初始文本数据集中各个文本数据对应的文本向量;对所述初始文本数据集中各个文本数据对应的文本向量进行聚类处理,得到文本向量聚类结果,将所述文本向量聚类结果作为第二训练数据集,通过获取第二训练数据集可以进一步提高模型输出的准确性;最后,利用所述第二训练数据集对训练后的比对学习模型进行再训练,得到目标比对学习模型,通过获取目标模型,可以为后续简单、快速进行语义级的文本聚类奠定基础。
47、本说明书提供的一种文本聚类方法,首先,获取待聚类文本数据集;其次,通过上述的目标比对学习模型,将所述待聚类文本数据集转换为文本向量,通过利用目标比对学习模型将文本数据转换为文本向量,能够在不需要大量的文本标记训练的前提下,准确快速地处理字词不相似但语义相似的文本数据,得到高质量的文本向量;最后,对所述文本向量进行聚类处理,得到待聚类文本数据集的聚类结果,通过对文本向量进行聚类处理,可以识别出高频出现的文本数据,从而可以警醒有关部门,避免出现类似的问题。
- 还没有人留言评论。精彩留言会获得点赞!