基于不确定性引导的人体姿态估计域自适应网络及方法
本发明涉及一种人体姿态估计域自适应网络及方法,具体涉及一种基于不确定性引导的人体姿态估计域自适应网络及方法。
背景技术:
1、人体姿态估计是计算机视觉领域中非常重要的一项内容,根据输入图片中人物数目的多少,我们可以将2d人体姿态估计任务分为两类,即单人姿态估计和多人姿态估计。人体姿态估计的基本任务是从输入的图像或视频中估计出人体关节点的2d或3d位置信息,进而生成整个人体的骨骼姿态或者密集网格表面。它是动作识别、人机交互和增强现实等领域的基础,在许多现实场景中有十分广泛的应用。
2、在人体姿态估计任务中,我们经常会遇到算法实际应用的场景与其训练样本之间有较大分布差异的情况,如室内场景与道路场景、真实场景与虚拟场景之间均存在较大的风格差异。在这些情况下,算法的性能通常会有大幅度的下降。而若要针对不同数据域来单独采集样本并标注的话,这极其费时费力,且不现实。因此,如何让在源域中训练完成的人体姿态估计算法能够在目标域上有较好的泛化性能,是一个极具挑战的难题。针对人体姿态估计领域,现在主要有基于模型的传统人体姿态估计方法和基于深度学习的人体姿态估计方法。
3、传统的人体姿态估计方法主要分为两类,一类是利用图结构模型的方法来建模人体的各个部位,并利用概率统计模型来进行人体姿态估计。另一类则是将人体姿态估计任务看做分类任务来进行求解,例如rogez等人利用人工设计的特征,并通过提出的随机决策树等方法来对人体姿态进行检测。与现有的深度学习方法相比,这些传统的方法具有计算复杂度低和推理速度快等优势,同时具有更强的可解释性,但是传统方法的检测精度较低。
4、基于深度学习的方法主要通过学习端到端的映射函数,通过端到端训练,从输入的图像推断出图像中的人体关节点,基于深度学习的方法性能超越了传统方法,成为当前主流的体姿态估计方法。该类方法通常可分为:基于坐标回归的人体姿态估计方法和基于热图检测的人体姿态估计方法。基于坐标回归的人体姿态估计方法思想简洁,所以其网络通常拥有较小计算复杂度,因此这类方法有着明显的速度优势。然而,由于让网络直接预测关节点坐标的方式,可利用的监督信息较少,这使得网络学习映射关系的难度较大,从而导致了这类算法的效果欠佳。基于热图检测的人体姿态估计方法首先利用各个关节点的坐标来制作热图标签,即以关节点坐标位置为中心制作一个固定方差的高斯热图,从而对于每类关节点得到其对应的一层热图,然后让深度神经网络学习预测该热图。与基于坐标回归的方法相比,其通过制作热图的形式变相地增加了网络的监督信息,使网络在学习过程中更容易收敛,因此这类方法往往有着更好的性能表现。然而,由于定位热图最大响应位置的操作不可微分,因此该类方法不能进行端到端的训练。此外,为了使关节点被更精细地被定位,网络往往要输出具有较高分辨率的热图,因此该类方法计算复杂度高、推理时间慢。
5、随着深度神经网络的提出与快速进展,使用深度学习方法解决人体姿态估计难题已经获得较好的成绩,例如:rogez等人利用人工设计的特征(参见rogez g,rihan j,ramalingam s,et al.randomized trees for human pose detection[c]//2008ieeeconference on computer vision and pattern recognition.ieee,2008:1-8.),并通过提出的随机决策树等方法来对人体姿态进行检测。toshev等人首次在人体姿态估计任务中使用深度学习方法,并提出了deeppose算法(参见toshev a,szegedy c.deeppose:humanpose estimation via deep neural networks[c]//proceedings of the ieeeconference on computer vision and pattern recognition.2014:1653-1660.),在人体姿态估计中取得了优异的性能表现。
6、然而,现有技术中,使用深度学习方法进行人体姿态估计也存在许多不足之处,因为在人体姿态估计任务中,样本经常会出现关节点被遮挡、运动模糊、人物分辨率低等退化的情况,对于这些样本,网络的预测结果往往是不可靠的。同时,在训练过程中,网络强行拟合这些样本,训练后也将导致算法性能的下降。此外,算法应用的实际场景往往和训练数据有一定的分布差异,也会导致算法在应用场景下的效果不佳。
7、下面举两个典型的例子具体说明一下以上存在的不足之处:niteshb.gundavarapu等人发表的论文structured aleatoric uncertainty in human poseestimation(参见gundavarapu n b,srivastava d,mitra r,et al.structuredaleatoric uncertainty in human pose estimation[c]//cvpr workshops.2019,2:2.)中,提出了一种在人体姿态估计任务中考虑数据不确定性的算法,该算法采用自顶向下的思路和基于回归的方法来处理多人姿态估计问题,具体是在使用resnet骨干网络回归关节点坐标的基础上,假设该坐标服从二维高斯分布,同时在网络末端增加了两个检测头来学习分布的协方差矩阵。然后,利用回归任务的损失函数,来对协方差矩阵进行无监督学习,即当图像数据中关节点出现遮挡等退化情况时,让网络趋向学习一个大的方差来减少其带来的损失。该算法通过关节点遮挡实验发现,随着遮挡块的不断增加,可观察到网络估计的方差也不断增加,证明了网络学习到数据不确定性是正确有效的。因此,该算法通过引入域自适应迁移学习的思想,提升了人体姿态估计的鲁棒性与性能。然而,该算法虽然考虑了不确定性的学习,但该算法采用协方差矩阵来进行不确定性学习,导致人体姿态估计的域自适应能力较差,进而使得算法不稳定、准确率较差,计算负担较大。
8、jiang j等人发表的论文regressive domain adaptation for unsupervisedkeypoint detection(参见jiang j,ji y,wang x,et al.regressive domain adaptationfor unsupervised keypoint detection[c]//proceedings of the ieee/cvfconference on computer vision and pattern recognition.2021:6780-6789.)中,提出了一种针对无监督关键点检测的回归域自适应方法。该算法认为在概率意义上,模型的输出空间是稀疏的。如果能将输出空间从完整的像素空间缩小到仅有k个关键点的离散空间,则缩小回归问题与分类问题之间的差距将成为可能。该算法在关键点检测问题中引入了一个对抗回归器来最大化目标域上的预测差异。同时鼓励特征提取器最小化预测差异,从而学到与域无关的特征。该算法通过采用同一个目标的极大较小博弈进行对抗训练。在关键点检测问题中,计算主回归器输出热力图和对抗回归器输出的kl散度。然而对抗回归器会最大化这个散度,而特征提取器会最小化这个散度,导致关键点检测效果较差,影响最终人体姿态估计结果的准确性。
技术实现思路
1、本发明的目的是解决现有基于模型的传统人体姿态估计方法计算精度较低、基于深度学习的人体姿态估计方法的域自适应能力不足、关键点检测不准确以及计算繁杂负担大导致人体姿态估计效果较差的技术问题,而提供基于不确定性引导的人体姿态估计域自适应网络及方法。
2、本发明的技术解决方案是:
3、本发明一种基于不确定性引导的人体姿态估计域自适应网络,其特殊之处在于:
4、包括主框架网络和子框架网络;
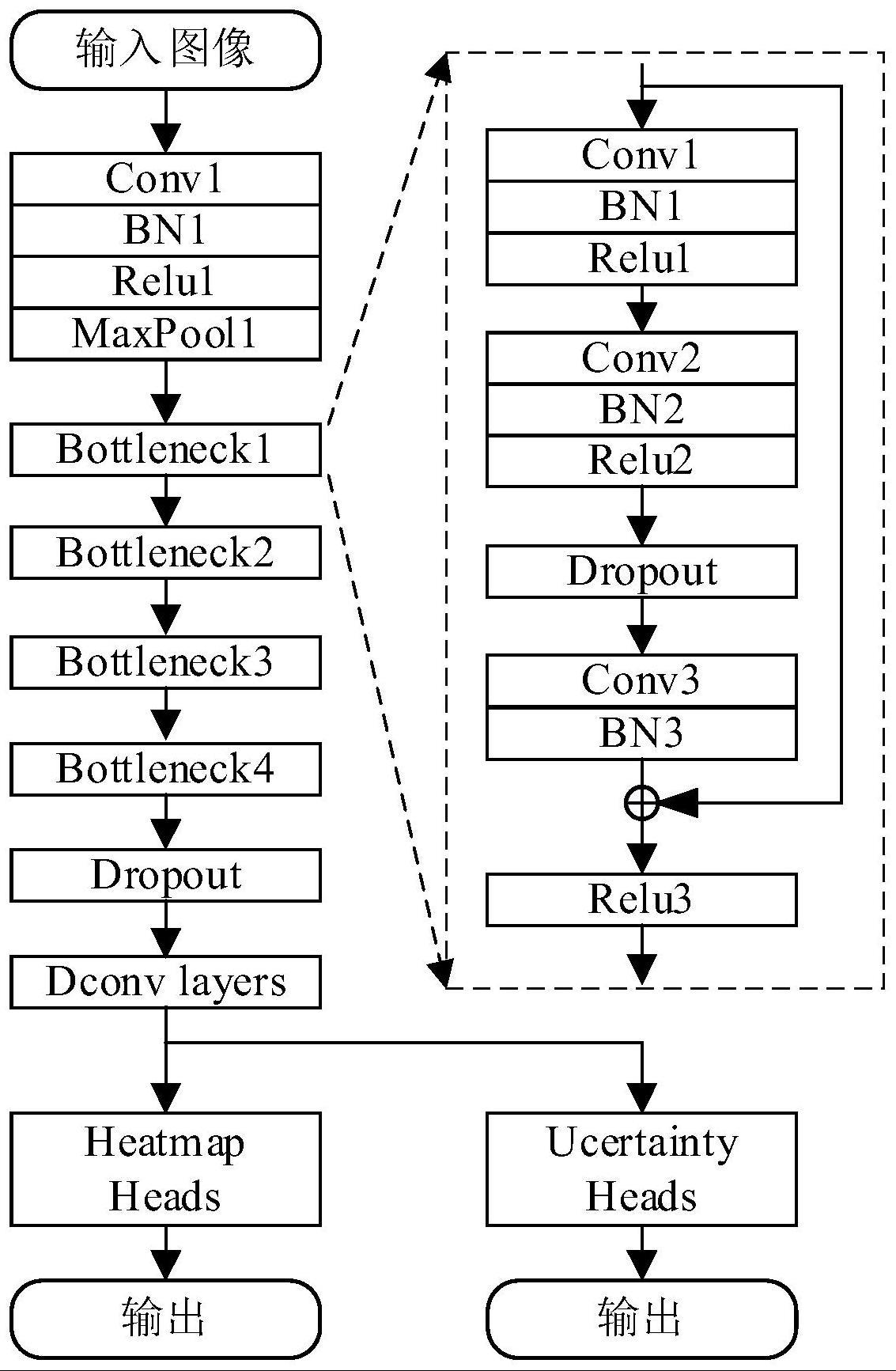
5、所述主框架网络包括依次连接的输入层、第一卷积层、第一batchnorm层、第一激活函数层、最大值池化层、第一瓶颈层、第二瓶颈层、第三瓶颈层、第四瓶颈层、dropout层、反卷积层,以及分别和反卷积层输出端连接的热力图模块和不确定性学习模块;
6、其中,第一瓶颈层、第二瓶颈层、第三瓶颈层和第四瓶颈层的网络结构均包括子框架网络;
7、所述子框架网络包括依次连接的第一卷积层、第一batchnorm层、第一激活函数层、第二卷积层、第二batchnorm层、第二激活函数层、droupout层、第三卷积层、第三batchnorm层、跳跃连接相加层、第三激活函数层;
8、所述输入层用于输入多帧相邻的视频帧图像;
9、所述热力图模块和不确定性学习模块的输出结果用于估计人体姿态的类别标签。
10、进一步地,所述主框架网络的各层参数设置为:
11、所述第一卷积层的输入通道数为3或5或7,输出通道数为64~256,卷积步长为2;
12、所述第一瓶颈层的输入通道数与第一卷积层的输出通道数相同,第一瓶颈层的输出通道数为256~512,卷积步长为1;
13、所述第二瓶颈层的输入通道数与第一瓶颈层的输出通道数相同,第二瓶颈层的输出通道数为512~1024,卷积步长为1;
14、所述第三瓶颈层的输入通道数与第二瓶颈层的输出通道数相同,第三瓶颈层的输出通道数为1024~2048,卷积步长为1;
15、所述第四瓶颈层的输入通道数与第三瓶颈层的输出通道数相同,第四瓶颈层的输出通道数为2048,卷积步长为1;
16、所述不确定性学习模块的输入通道数为2048,输出通道数为3或5或7,反卷积步长为1;
17、所述热力图模块的输入通道数为2048,输出通道数为2048,反卷积步长为1。
18、进一步地,所述主框架网络和子框架网络中dropout的丢弃概率均为0.1;
19、所述主框架网络的各层参数设置为:
20、所述第一卷积层的输入通道数为3,输出通道数为64,卷积步长为2;
21、所述第一瓶颈层的输入通道数为64,输出通道数为256,卷积步长为1;
22、所述第二瓶颈层的输入通道数为256,输出通道数为512,卷积步长为1;
23、所述第三瓶颈层的输入通道数为512,输出通道数为1024,卷积步长为1;
24、所述第四瓶颈层的输入通道数为1024,输出通道数为2048,卷积步长为1;
25、所述不确定性学习模块的输入通道为2048,输出通道为3,反卷积步长为1;
26、所述热力图模块的输入通道为2048,输出通道为2048,反卷积步长为1。
27、进一步地,所述输入层为奇数帧图像。
28、本发明还提供了一种基于不确定性引导的人体姿态估计域自适应方法,使用上述的基于不确定性引导的人体姿态估计域自适应网络,其特殊之处在于,包括以下步骤:
29、步骤1)获取训练源域数据集和目标域数据样本集;
30、所述训练源域数据集为带标签的数据集,所述目标域数据样本集为不带标签的待测试数据集;
31、步骤2)利用训练源域数据集对上述的自适应网络进行预训练,再将目标域数据样本集送入该自适应网络中,得到目标域数据样本集所有图像的预测标签;
32、步骤3)获得模型不确定性和数据不确定性
33、步骤3.1)将目标域数据样本集所有图像的预测标签进行t次向前推理分别获得t个预测热图和对应预测标签,利用所得预测热图和对应预测标签得到模型不确定性;
34、步骤3.2)对每个图像的t个预测标签取平均值作为最终预测标签,通过t个预测热图得到每张图像的数据不确定性;
35、步骤4)获取伪标签
36、步骤4.1)根据步骤2)中预测标签和步骤3.2)中最终预测标签获取每个预测热图中每个关节点的响应值,获取每个预测热图中最大响应值和对应的坐标,再根据步骤3.2)中的数据不确定性和预先设定的判定依据筛选出每个预测热图的可靠关节点;
37、步骤4.2)通过可靠关节点得到对应的伪标签;
38、步骤5)根据不确定性指导的分割方法,利用步骤3.1)中模型不确定性得到损失权重,再通过损失权重、步骤4.2)的伪标签、步骤4.1)中设定的判定依据得到损失函数,采用损失函数l对自适应网络进行训练;
39、步骤6)将训练源域数据集输入自适应网络,根据损失函数下降的梯度,更新网络参数;
40、步骤7)将目标域数据样本集输入自适应网络,得到人体姿态估计结果。
41、进一步地,步骤1)中,将训练源域数据集定义为:
42、
43、将目标域数据样本集定义为:
44、
45、xid和yid分别代表图像和其对应的标签,id代表每个图像的索引,ns和nt分别代表训练源域数据集和目标域数据样本集的样本个数。
46、进一步地,步骤2)中,所述预测标签定义为id代表每个图像的索引。
47、进一步地,步骤3.1)中,所述模型不确定性muid通过以下公式获得;
48、
49、e是均值;
50、步骤3.2)中,最终预测标签和数据不确定性duid分别通过以下公式得到:
51、
52、
53、σ(·)为每次采样的不确定性;为第t帧的预测标签,t=1,2,…,t;
54、xid为目标域数据样本集的图像。
55、进一步地,步骤4.1)具体为:根据步骤2)中预测标签和步骤3.2)中最终预测标签获取每个预测热图中每个关节点k的响应值,获取每个预测热图中最大响应值和对应的坐标其中和分别代表最大响应值的关节点k的横坐标和纵坐标,再根据步骤3.2)中的数据不确定性和预先设定的判定依据筛选出可靠关节点,判定依据如下:
56、
57、β是权重超参数,thr是算法测试过程中设置的通用阈值,取值为0.2;
58、步骤4.2)通过可靠关节点并采用以下公式得到第k个关节点对应的伪标签
59、
60、σ是高斯热图的方差,(i,j)是除最大响应值外其他响应值的关节点的坐标。
61、进一步地,步骤5)中,所述损失函数l为;
62、
63、
64、为损失权重;
65、α是权重超参数;
66、k是关节点总数;
67、δ(·)为条件选择函数,满足条件输出1,反之输出0。
68、本发明的有益效果:
69、1.本发明基于不确定性引导的人体姿态估计域自适应网络,在骨干网络中的每个瓶颈层模块里添加了一层dropout,并使其在训练和测试过程中保持打开的状态,同时,本发明进行人体姿态估计的域自适应学习,是基于不确定性热图进行关键点检测,并且引入mc dropout(蒙特卡洛丢弃方法)的方法进行不确定性估计,相较于对抗训练的极大较小博弈更加有效,与现有人体姿态估计网络相比,在不增加网络模型计算负担的情况下,可以进一步提升网络模型的人体姿态估计域自适应能力,使网络模型更加的鲁棒和稳定。
70、2.本发明基于不确定性引导的人体姿态估计域自适应方法,通过mc dropout的方法来近似估计后验概率,并且利用t次向前推理获得预测热图和各类不确定性,进一步提升人体姿态估计的域自适应能力,与现有人体姿态估计方法相比,在不确定性估计上更加准确和稳定,计算负担小。
71、3.本发明基于不确定性引导的人体姿态估计域自适应方法,是基于热图估计的方式进行检测,对于每一个关节点,使用预测热图最大响应值位置处所对应的数据不确定性来进行判断,利用不确定性学习提升热图估计的准确性和鲁棒性。与现有方法相比,在关键点检测上更加鲁棒。
72、4、本发明基于不确定性引导的人体姿态估计域自适应网络及方法,结合基于不确定性估计和基于深度学习方法的优势,设计出一个基于不确定性引导的人体姿态估计域自适应方法,利用不确定性学习的方法来评估样本的退化程度,从而削弱退化样本对训练的影响;利用模型不确定性分析网络对样本的认知程度,进而设法提高网络在目标域上的性能表现,相比传统方法更加简单高效,并且可以获得优于现有人体姿态估计方法的估计性能,可广泛应用于图像、视频的人体姿态估计等视觉任务。
- 还没有人留言评论。精彩留言会获得点赞!