一种面向边缘硬件设备计算的层间流通数据全量化方法与流程
本发明属于深度神经网络量化领域,具体涉及一种面向边缘硬件设备计算的层间流通数据全量化方法。
背景技术:
1、随着人工智能技术应用领域的不断扩大,其部署的平台由gpu集群向端侧设备不断扩散。云计算和gpu与端侧设备相比,不仅拥有较强的计算能力,而且一定程度上不会受限于内存或电量消耗。所以将深度神经网络部署于端侧设备时,需从推断速度、内存和功耗等多方面考虑。为了更好的实现端侧应用,如何在保证应用效果的情况下实现网络模型轻量化成为重点。实现网络模型轻量化,目前主要从两个方向入手:第一,搭建网络层数少或结构特殊参数量较少的网络模型,如采用depthwise结构的mobilenet系列;第二,通过网络结构剪枝减少网络结构参数量、浮点数据量化通过降低数据精度实现减少存储和计算量,而卷积层和batchnorm的融合操作可进一步加速推断计算。在实际的应用过程中,结合精度要求和内存要求,网络模型往往倾向于选择第二种方法。主要原因如下:(1)适用性强:无需开发新的网络模型,在已有的模型基础上实现模型精度较小丢失和网络参数量较大减少的效果。且多数端侧推理平台都支持定点数据运算;(2)所需存储空间小:量化实现可选择fp32转int16,int8,int4和int1。当网络模型为2值网络时,即网络参数只有0和1,多选转为int1,存储空间减少32倍,但这种网络模型较少。当转为int4时,由于数据丢失较为严重,所以当网络结构较深时,极易出现不收敛的情况。而选int16时,保留了较多数据,不易出现模型精度丢失,但易造成数据冗余。所以一般多选择int8,可以将网络存储空间减少4倍,且模型精度丢失较少;(3)功耗低:移动8bit定点型数据与移动32bit浮点型数据相比,在效率上前者比后者高4倍,对于许多深度网络结构,内存的使用量一定程度上正比于功耗。
2、现有技术中在对卷积神经网络进行量化运算中,将定点化int8位数据反化至浮点32位数据,该浮点32位数据与偏置相加后再进行激活运算,运算得到的浮点32位数据最后通过反量化至定点int8位数据传输给下一层的卷积层,其中定点化int8位数据卷积运算位于fpga,而偏置和激活函数的浮点运算位于cpu中,则会因为cpu和fpga之间存在大量数据传输而导致fpga推断时间过长或停顿的问题,而浮点运算的存在则需要额外增加cpu等浮点运算器件,降低了fpga的存在意义,且目前fpga支持的可运算数据一般为定点数据,即量化后的数据。
技术实现思路
1、本发明的目的在于针对解决背景技术中提出的问题,提出一种面向边缘硬件设备计算的层间流通数据全量化方法。
2、为实现上述目的,本发明所采取的技术方案为:
3、本发明提出的一种面向边缘硬件设备计算的层间流通数据全量化方法,包括获取网络模型中各层的权重值以及输入网络模型的特征图的特征值,通过量化方法生成各层权重值量化系数,以及特征值量化系数。
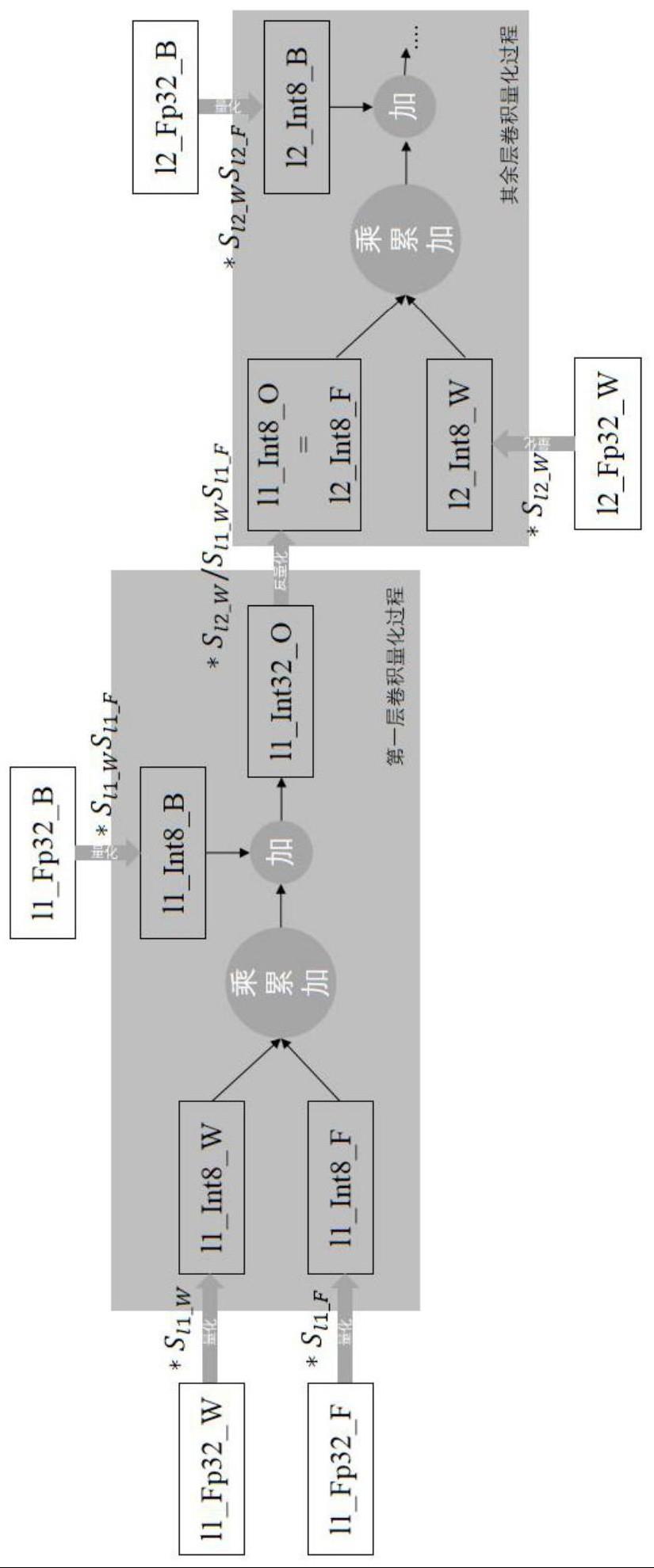
4、对于第一层,通过第一层权重值量化系数和特征值量化系数依次对第一层权重值和特征值进行定点化,对于其他层,通过本层权重值量化系数对本层权重值进行定点化。
5、通过本层权重量化系数和特征值量化系数对本层偏置数据定点化。
6、然后再对本层定点化后的权重值和特征值进行乘累加运算,乘累加的结果与本层定点化后的偏置相加得到定点p位中间数据。
7、最后通过本层的权重值量化系数、本层的特征值量化系数和下一层的权重值量化系数将定点p位中间数据反量化为定点m位输出数据,且定点m位输出数据作为下一层定点化后的输入特征值。
8、优选地,通过量化方法生成各层权重值量化系数,以及特征值量化系数,包括:
9、量化的一般公式如下:
10、q(x,s)=clip(round(x·s))
11、其中,x表示需量化的张量,s表示量化系数,q(x,s)表示量化后的张量,round表示向上取整,clip表示截断。
12、使用ql表示网络模型第l层的浮点输出,表示第l层量化后反量化的结果:
13、ql=al*wl
14、
15、其中,al表示第l层的激活值,wl表示第l层的权重值,sl_w表示第l层权重值的量化系数,sl_f表示第l层特征值的量化系数,且al,wl和sl均为fp32。
16、量化方法easyquant引入cos相似性对目标函数进行优化:
17、
18、其中,n表示输入的样本数,表示第i个样本的第l层的浮点输出,表示第i个样本的第l层量化后反量化的结果。
19、优化时,先特征量化系数,通过最大化cos相似性优化权重量化系数,然后固定权重量化系数优化特征值量化系数,如此交替优化直到cos值收敛或超出预定时间。
20、优选地,对于第一层,通过第一层权重值量化系数和特征值量化系数依次对第一层权重值和特征值进行定点化,对于其他层,通过本层权重值量化系数对本层权重值进行定点化,包括:
21、第一层特征值定点化:l1_int8_f=l1_fp32_f*sl1_f。
22、各层权重值定点化:l_int8_w=l_fp32_w*sl_w。
23、其中,sl1_f表示第一层的特征值量化系数,l1_int8_f表示第一层特征值定点化后的,l1_fp32_f表示第一层特征值,sl_w表示第l层的权重值量化系数,l_fp32_w表示第l层权重值,l_int8_w表示第l层的权重值定点化后的。
24、优选地,通过本层权重量化系数和特征值量化系数对本层偏置数据定点化,包括:
25、各层偏置数据定点化:l_int32_b=l_fp32_b*sl_f*sl_w。
26、其中,sl_f表示第l层的特征值量化系数,l_fp32_b表示第l层的浮点偏置数据,l_int32_b表示第l层定点化后的偏置值。
27、优选地,然后再对本层定点化后的权重值和特征值进行乘累加运算,乘累加的结果与本层定点化后的偏置相加得到定点p位中间数据,包括:
28、p的值为int32。
29、定点32位中间数据:l_int32_o=l_int8_f*l_int8_w+l_int32_b。
30、其中,l_int32_o表示第l层的定点32位中间数据,l_int8_f表示第l层定点化后的特征值。
31、优选地,最后通过本层的权重值量化系数、本层的特征值量化系数和下一层的权重值量化系数将定点p位中间数据反量化为定点m位输出数据,且定点m位输出数据作为下一层定点化后的输入特征值,包括:
32、m的值为int8;
33、将定点32位中间数据反量化为定点8位输出数据:
34、
35、(l+1)_int8_f=l_int8_o
36、其中,l_int8_o表示第l层的定点8位输出数据,且作为第l+1层的输入特征值,(l+1)_int8_f表示第l+1层的输入特征值,sl+1_w表示第l+1层的权重量化系数。
37、优选地,面向边缘硬件设备计算的层间流通数据全量化方法还包括对网络模型各层的激活函数定点化处理:
38、结合激活函数曲线特性获取各层对应定点32位中间数据int32_o的激活函数数据act(int32_o)。
39、然后再通过本层的权重值量化系数、本层的特征值量化系数和下一层的权重值量化系数将32位中间数据对应的激活函数数据反量化为定点8位输出数据:
40、
41、其中,l_act(int32_o)表示第l层定点32位中间数据对应的激活函数数据。
42、优选地,对于各层,激活函数的种类如下:
43、当激活函数为relu时:
44、若输入的int32_o小于或等于0,则经激活函数后的输出值截断为定点0;
45、若输入的int32_o大于0,则经激活函数后的输出值截断的最大值为定点127;
46、当激活函数为leakyrelu时:
47、若输入的int32_o小于或等于0,则经激活函数后的输出值为(int32_o*13/128.0-0.5);
48、若输入的int32_o大于0,则经激活函数后的输出值的截断的最大值为定点127;
49、当激活函数为relu6时:
50、若输入的int32_o小于0,则该值截断为定点0;
51、若输入的int32_o大于0且小于max_6乘以下一层的权重值量化系数且小于127,则经激活函数后的输出值保持原输入值;
52、若输入的int32_o大于max_6乘以下一层的权重值量化系数且大于127,则经激活函数后的输出值的截断的最大值为定点127。
53、与现有技术相比,本发明的有益效果为:
54、本面向边缘硬件设备计算的层间流通数据全量化方法通过对网络模型中权重值、特征值和偏置数据的量化,以及对激活函数数据的量化,将原来位于cpu的浮点偏置数据和激活函数运算量化为适用于fpga等只支持定点运算的边缘硬件,进而消除因中间大量数据传输导致fpga推断时间过长或停顿的问题,实现定点数据流通。
- 还没有人留言评论。精彩留言会获得点赞!