一种基于CSR存储格式的SpMV实现方法、装置及介质
本发明涉及高性能数值计算,尤其涉及一种基于csr存储格式的spmv实现方法、装置及介质。
背景技术:
1、稀疏矩阵向量乘(spmv)是稀疏线性代数中的基本原语,在许多科学计算应用中占主导地位,如用于求解大型线性系统和特征值问题的迭代方法、数据挖掘、图分析等。而在这些科学计算应用中,spmv往往是性能瓶颈,因此加速spmv操作具有十分重要的意义。
2、图像处理单元(gpu)具有吞吐量大、并行性高的特点,在科学计算领域是一个很有吸引力的选择。面向gpu的spmv算法中,访存行为往往是性能瓶颈,有效地处理访存行为是提高spmv的关键之一。gpu在读取内存的时候会一次性读取一段连续的内存空间,即使并非所有读取的数据都是需要的。而当所需数据分布在不同的连续段时,gpu会读取多段连续内存空间来获取所需要的数据,所以gpu中的随机访问会造成很大时间开销。
3、对于面向gpu基于csr存储格式的spmv算法的研究,前人已经做过许多工作。bell和garland提出了csr-vector,csr-vector为矩阵的每行都分配32个线程(一个线程束)作为一个vector,vector会计算行中的非零元素与稠密向量x的乘积,并将乘积结果求和,最后将求和结果写回到稠密向量y中。yongchao liu和bertil schmidt提出了lightspmv,当矩阵中的行非零元素个数小于32时,就会造成多余的线程在空转,为了尽量避免浪费,lightspmv会根据矩阵的平均行非零元素个数来确定vector_size(一个vector所包含的线程束,每个vector负责处理矩阵的一行)。arash ashari等人提出的acsr是一种动态分配负载的算法,它首先读取矩阵每行非零元素的个数,将个数相近的行划分为同一组(称为bin),每个bin根据元素个数为vector设置合适的vector_size,从而实现动态分配负载。
4、目前对于面向gpu基于csr存储格式的spmv算法的研究,多是从负载均衡的角度切入,尽可能地使得每个线程的负载相同来提高整体性能。但是在spmv中内存访问占据了大量的时间开销,而上述算法缺乏对在这方面的考虑。前人提出的算法一般是将spmv的取值、乘积与求和过程合在一起,但是矩阵每行的长度不定,且有些矩阵行的数据量远小于gpu一次访问内存事物所读到的数据量。
技术实现思路
1、为至少一定程度上解决现有技术中存在的技术问题之一,本发明的目的在于提供一种基于csr存储格式的spmv实现方法、装置及介质。
2、本发明所采用的技术方案是:
3、一种基于csr存储格式的spmv实现方法,包括以下步骤:
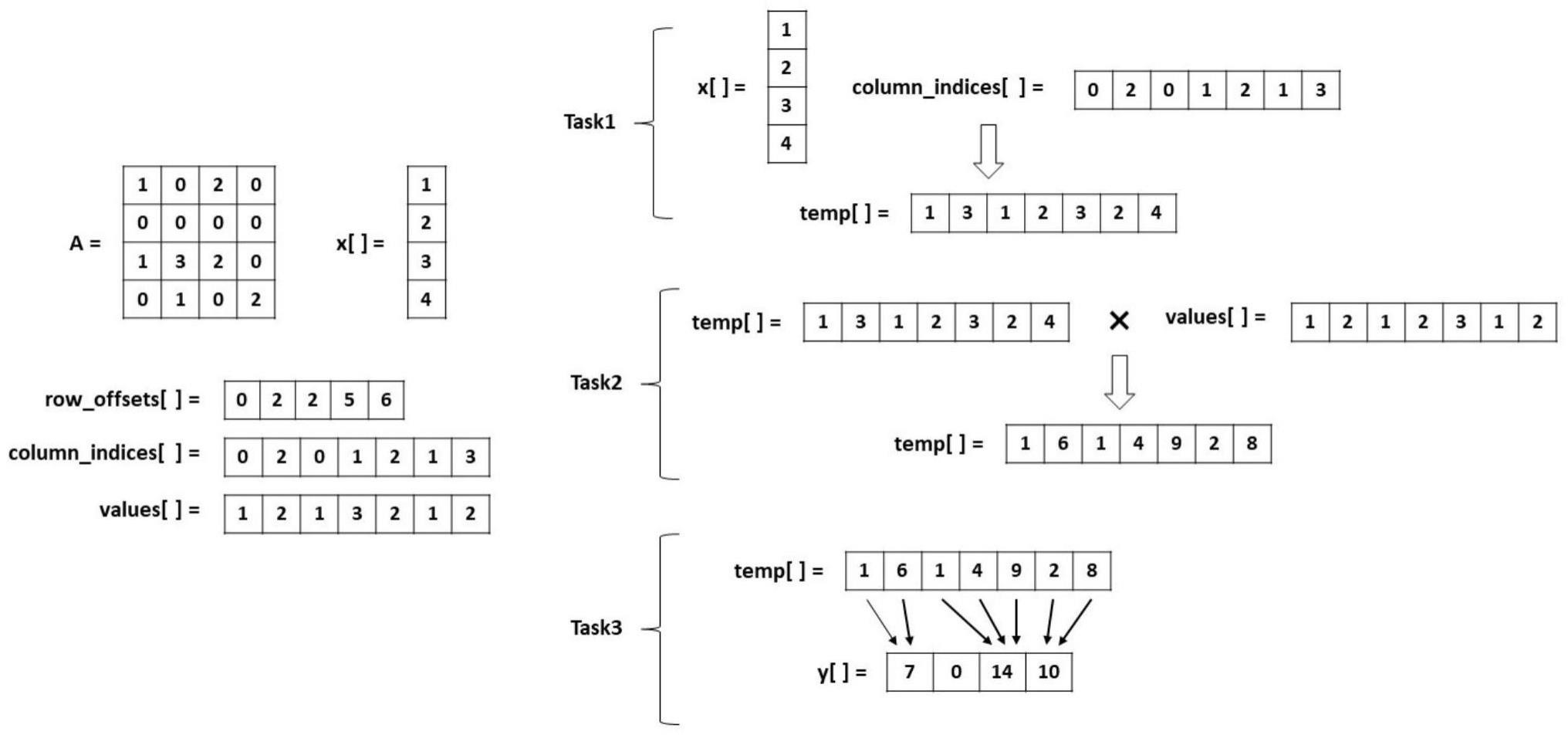
4、设稀疏矩阵a的规模为m行n列,稀疏矩阵包括多个非零元素;采用csr存储格式保存矩阵,获得三个数组values、column_indices和row_offsets;
5、将spmv分成三段操作,三段操作分别为取值操作(task1)、乘积操作(task2)、求和操作(task3),每段操作对应一种任务;
6、将每种任务划分为多个任务块;其中,取值操作对应的任务块记为task1 block,乘积操作对应的任务块记为task2 block,乘积操作对应的任务块记为task3 block;
7、将所有的线程划分为多个vector,一个vector包括vector_size个线程,所述vector是任务块的执行单元;
8、设计两个发射队列和一个计数器来记录任务块的就绪状态;
9、每个vector获取并执行处于就绪状态的任务块,在执行后更新任务块的就绪状态;当所有任务块都被执行完后,完成spmv操作。
10、进一步地,取值操作(task1)是根据稀疏矩阵中每个非零元素所处的列坐标,获取稠密向量x对应的值,并将结果写入到临时数组temp中作为中间值,伪代码表示为:x[column_indices[i]]→temp[i]。
11、进一步地,乘积操作(task2)是将取值操作中保存到临时数组temp的中间值与values数组的元素一一相乘,并将结果写回到临时数组temp中作为中间值;伪代码表示为:temp[i]*values[i]→temp[i]。
12、进一步地,求和操作(task3)是将乘积操作中保存到临时数组temp的中间值,按每矩阵行拥有的非零元素个数进行求和,并将求和结果写回到稠密向量y的对应位置中,伪代码表示为:
13、进一步地,所述将每种任务划分为多个任务块,包括:
14、对任务划分时,task1 block和task2 block的大小相同,任务块的大小设置为线程束大小的整数倍;
15、根据矩阵行来划分求和操作的任务,处于同一矩阵行的非零元素划分为一个任务块。
16、进一步地,任务块之间存在依赖关系,task1 block始终满足依赖关系,task2block会一一对应地依赖于task1 block,task3 block会一对一或一对多地依赖于task2block;
17、满足依赖关系的任务块处于就绪状态,处于就绪状态的task2 block和task3block会被添加到两个发射队列task2_issue_queue和task3_issue_queue中。
18、进一步地,所述每个vector获取并执行处于就绪状态的任务块,包括:
19、vector按照优先级获取处于就绪状态的任务块来执行,该过程称为任务块的发射;
20、task2 block和task3 block通过发射队列发射给vector来执行;取值操作通过计数器,来记录当前需要发射的task1 block;
21、其中优先级的顺序为:task3 block>task2 block>task1 block。
22、进一步地,所述在执行后更新任务块的就绪状态,包括:
23、当vector执行完task1 block,将对应的task2 block添加到对应的发射队列task2_issue_queue;
24、当vector执行完task2 block,检查是否有task3 block满足了依赖条件,并将task3 block添加到对应的发射队列task3_issue_queue。
25、本发明所采用的另一技术方案是:
26、一种基于csr存储格式的spmv实现装置,包括:
27、至少一个处理器;
28、至少一个存储器,用于存储至少一个程序;
29、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现上所述方法。
30、本发明所采用的另一技术方案是:
31、一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行如上所述方法。
32、本发明的有益效果是:本发明将“取值”与“乘积”划分为固定大小的任务块,提高了gpu内存访问的数据利用率。vector不需要等待所有的“取值”与“乘积”的任务块都完成时才执行“求和”任务块,只需要在队列中获取处于就绪状态的任务块即可执行,以达到类似乱序执行的效果,提高了并行性,避免了线程同时发起内存访问以造成阻塞的问题。
- 还没有人留言评论。精彩留言会获得点赞!