基于区块链的交互金融支付和大数据压缩存储方法及系统与流程
本发明涉及语音分析,具体而言,涉及一种基于区块链的交互金融支付和大数据压缩存储方法及系统。
背景技术:
1、近年来,随着互联网金融服务的逐渐普及,越来越多的用户可以方便地完成金融支付业务。然而在金融支付的过程中,许多金融支付系统没有较好的交互功能,不仅不能给用户带来较好的支付体验,而且存在较为明显的安全隐患;同时,对金融支付过程中的重要数据进行存储往往会占用巨大的存储资源,且存储过程也没有较高的安全性。
2、随着现代信息技术的不断更新换代,人工智能、区块链等领域的技术可以有效地提升金融支付系统的交互性、安全性,并有效地降低重要数据存储过程中的资源消耗。因此,提出一种基于区块链的交互金融支付和大数据压缩存储方法及系统有非常重要的价值和意义。
技术实现思路
1、为了克服上述问题或者至少部分地解决上述问题,本发明实施例提供一种基于区块链的交互金融支付和大数据压缩存储方法及系统,结合基于样本多轮次高质量替换的多决策平面互验声纹识别模型、基于表情分析后验的语音识别模型、基于多模块并行连接的后端比对式语音压缩编码模型,大大提高了金融支付过程中的安全性和效率;并利用区块链技术将核心信息上链存储,保证数据安全。
2、本发明采用的技术方案为:
3、第一方面,本发明实施例提供一种基于区块链的交互金融支付和大数据压缩存储方法,包括以下步骤:
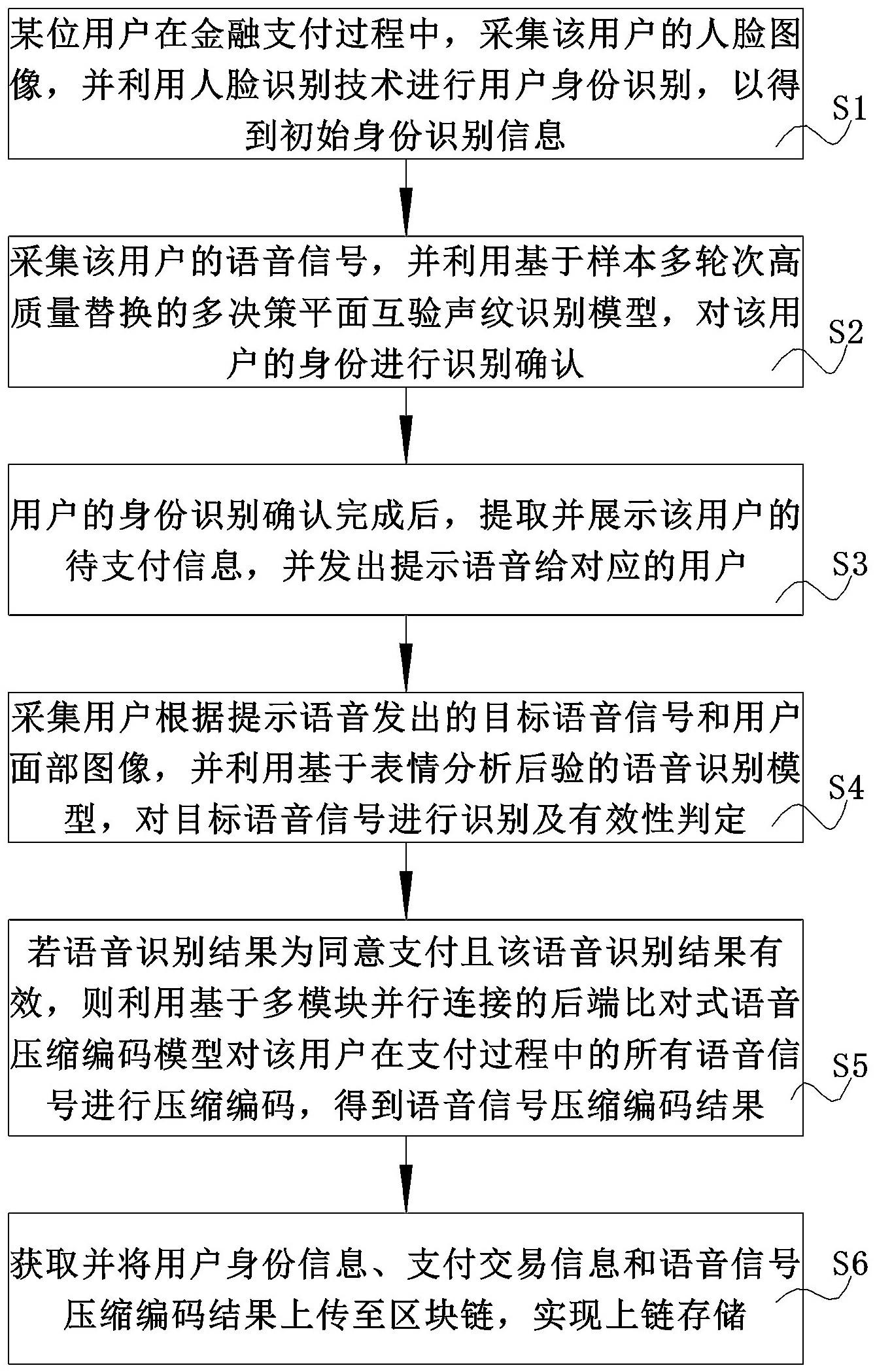
4、某位用户在金融支付过程中,采集该用户的人脸图像,并利用人脸识别技术进行用户身份识别,以得到初始身份识别信息;
5、采集该用户的语音信号,并利用基于样本多轮次高质量替换的多决策平面互验声纹识别模型,对该用户的身份进行识别确认;
6、用户的身份识别确认完成后,提取并展示该用户的待支付信息,并发出提示语音给对应的用户;
7、采集用户根据提示语音发出的目标语音信号和用户面部图像,并利用基于表情分析后验的语音识别模型,对目标语音信号进行识别及有效性判定;
8、若语音识别结果为同意支付且判定该语音识别结果有效,则利用基于多模块并行连接的后端比对式语音压缩编码模型对该用户在支付过程中发出的所有语音信号进行压缩编码,以得到语音信号压缩编码结果;
9、获取并将用户身份信息、支付交易信息和语音信号压缩编码结果上传至区块链,实现上链存储。
10、本发明提出了基于样本多轮次高质量替换的多决策平面互验声纹识别模型,对用户身份进行识别确认;该模型充分利用了多决策平面互验的思想,显著提升了用户身份识别确认的精准度。在此基础上,本发明提出了基于表情分析后验的语音识别模型,对语音信号进行识别及有效性判定;该模型利用了基于图像超分辨率的编码相似度检测方法,完成了用户表情的识别,并通过用户表情识别结果对用户的语音识别有效性进行判定,进一步提升了语音识别结果的安全性和有效性。进一步地,本发明还提出了基于多模块并行连接的后端比对式语音压缩编码模型,对用户发出的所有语音信号进行压缩编码;该模型利用多个模块智能连接及后端比对的方式,获取到压缩比最高的语音信号压缩编码结果。同时,本发明利用了区块链技术,将用户身份信息、交易信息、语音信号压缩编码结果进行上链存储,确保了系统的安全性。
11、基于第一方面,在本发明的一些实施例中,上述利用基于样本多轮次高质量替换的多决策平面互验声纹识别模型,对用户的身份进行识别确认的方法包括以下步骤:
12、根据初始身份识别信息,在预置的语音数据库中提取对应用户的多段语音信号组成正样本数据集,提取非该用户的多段语音信号组成多个负样本数据集;
13、利用正样本数据集和各个负样本数据集分别对svm模型进行训练,以得到多个声纹识别决策平面;
14、分别利用多个声纹识别决策平面对用户的语音信号进行声纹识别,以得到并根据多个声纹识别结果确定该用户的身份。
15、基于第一方面,在本发明的一些实施例中,上述利用基于表情分析后验的语音识别模型,对目标语音信号进行识别及有效性判定的方法包括以下步骤:
16、利用语音识别模型对目标语音信号进行识别,生成语音识别结果;
17、若语音识别结果为同意支付,则对用户面部图像进行表情分析,生成并根据分析结果判定语音识别结果是否有效。
18、基于第一方面,在本发明的一些实施例中,上述对用户面部图像进行表情分析,生成并根据分析结果判定语音识别结果是否有效的方法包括以下步骤:
19、将用户面部图像和预置的多个表情模板图像分别进行超分辨率重建;
20、对重建后的用户面部图像和各个表情模板图像进行图像编码,并计算用户面部图像和每个表情模板图像之间的相似度,以确定最终用户表情识别结果;
21、若最终用户表情识别结果为负面表情,则判定语音识别结果无效,禁止支付;反之,则判定语音识别结果有效。
22、基于第一方面,在本发明的一些实施例中,上述利用基于多模块并行连接的后端比对式语音压缩编码模型对该用户在支付过程中发出的所有语音信号进行压缩编码的方法包括以下步骤:
23、将采用不同语音压缩方法的语音压缩编码模块进行并联,并在各个语音压缩模块末端共同连接一个压缩结果比对模块,以得到基于多模块并行连接的后端比对式语音压缩编码模型;其中,压缩结果比对模块用于判断各个语音压缩编码模块的语音信号压缩结果是否最小,并发出信号将对应的最小语音信号压缩结果作为最终输出结果;
24、利用基于多模块并行连接的后端比对式语音压缩编码模型对该用户在支付过程中发出的所有语音信号进行压缩编码。
25、第二方面,本发明实施例提供一种基于区块链的交互金融支付和大数据压缩存储系统,包括初始识别模块、身份确认模块、支付提示模块、识别判定模块、语音压缩模块以及上链存储模块,其中:
26、初始识别模块,用于某位用户在金融支付过程中,采集该用户的人脸图像,并利用人脸识别技术进行用户身份识别,以得到初始身份识别信息;
27、身份确认模块,用于采集该用户的语音信号,并利用基于样本多轮次高质量替换的多决策平面互验声纹识别模型,对该用户的身份进行识别确认;
28、支付提示模块,用于用户的身份识别确认完成后,提取并展示该用户的待支付信息,并发出提示语音给对应的用户;
29、识别判定模块,用于采集用户根据提示语音发出的目标语音信号和用户面部图像,并利用基于表情分析后验的语音识别模型,对目标语音信号进行识别及有效性判定;
30、语音压缩模块,用于若语音识别结果为同意支付且判定该语音识别结果有效,则利用基于多模块并行连接的后端比对式语音压缩编码模型对该用户在支付过程中发出的所有语音信号进行压缩编码,以得到语音信号压缩编码结果;
31、上链存储模块,用于获取并将用户身份信息、支付交易信息和语音信号压缩编码结果上传至区块链,实现上链存储。
32、本系统通过初始识别模块、身份确认模块、支付提示模块、识别判定模块、语音压缩模块以及上链存储模块等多个模块的结合,大大提高了金融支付过程中的安全性和效率。本系统采用基于样本多轮次高质量替换的多决策平面互验声纹识别模型,对用户身份进行识别确认;该模型充分利用了多决策平面互验的思想,显著提升了用户身份识别确认的精准度。在此基础上,本系统采用基于表情分析后验的语音识别模型,对语音信号进行识别及有效性判定;该模型利用了基于图像超分辨率的编码相似度检测方法,完成了用户表情的识别,并通过用户表情识别结果对用户的语音识别有效性进行判定,进一步提升了语音识别结果的安全性和有效性。进一步地,本系统还采用了基于多模块并行连接的后端比对式语音压缩编码模型,对用户发出的所有语音信号进行压缩编码;该模型利用多个模块智能连接及后端比对的方式,获取到压缩比最高的语音信号压缩编码结果。同时,本系统利用了区块链技术,将用户身份信息、交易信息、语音信号压缩编码结果进行上链存储,确保了系统的安全性。
33、第三方面,本技术实施例提供一种电子设备,其包括存储器,用于存储一个或多个程序;处理器。当一个或多个程序被处理器执行时,实现如上述第一方面中任一项的方法。
34、第四方面,本技术实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述第一方面中任一项的方法。
35、本发明实施例至少具有如下优点或有益效果:
36、本发明实施例提供一种基于区块链的交互金融支付和大数据压缩存储方法及系统,提出了基于样本多轮次高质量替换的多决策平面互验声纹识别模型,对用户身份进行识别确认;该模型充分利用了多决策平面互验的思想,显著提升了用户身份识别确认的精准度。在此基础上,本发明提出了基于表情分析后验的语音识别模型,对语音信号进行识别及有效性判定;该模型利用了基于图像超分辨率的编码相似度检测方法,完成了用户表情的识别,并通过用户表情识别结果对用户的语音识别有效性进行判定,进一步提升了语音识别结果的安全性和有效性。进一步地,本发明还提出了基于多模块并行连接的后端比对式语音压缩编码模型,对用户发出的所有语音信号进行压缩编码;该模型利用多个模块智能连接及后端比对的方式,获取到压缩比最高的语音信号压缩编码结果。同时,本发明利用了区块链技术,将用户身份信息、交易信息、语音信号压缩编码结果进行上链存储,确保了系统的安全性。
- 还没有人留言评论。精彩留言会获得点赞!