一种基于迁移学习的跨被试RSVP脑电信号的分类方法
本发明公开了一种基于源域选择和深度迁移模型的跨被试rsvp脑电信号的分类方法,可用于跨被试rsvp信号的识别,属于计算机软件领域。
背景技术:
1、快速序列视觉呈现(rapid serial visual presentation,rsvp)范式首次由maryc.potter提出,其被定义为在同一空间位置上,以高且固定的频率逐一呈现多副图片的过程。脑机接口(brain-computer interface,bci)是一个建立在人与机器之间,以人的脑电活动控制机器完成任务的交流控制系统。rsvp范式所呈现的图片流由频繁出现的非目标图片与非频繁出现的目标图片组成。当被试观察到目标图片时,可诱发出p300成分,通过解码,可以识别对应得目标图像。目前,rsvp-bci在脑机接口增强、警事勘探、医学、认知学、心理学等领域发挥着重要作用。实际使用中,由于eeg信号高维度导致的低信噪比、信号的高不稳定性、每个被试具有不同的脑电模式,当更换新被试后,该被试需要进行长时间的校准工作来提供校准数据,使得模型得以训练以适应当前被试。这种长时间的校准工作降低了rsvp-bci工作的效率以及用户体验性。
2、为解决上述问题,领域内常使用迁移学习方法进行跨被试分类方法的研究。一般来说,该类方法分为三种不同的类型:基于实例、基于特征和基于模型的。
3、在基于实例的迁移方法中,基本思路为衡量源域数据和目标域数据,即源域被试的试次和目标域被试的试次的相似度,给予与目标试次更相似的源域试次更高的权重,即在损失函数中贡献更大的损失值,以此来迁移源域的数据。例如yan li等人在基于lda和bagging方法上提出bagged-iwlda,通过iwlda来解决不同领域间协方差偏移的适应问题,其是lda在样本加权概念上的衍生方法,权重被定义为样本与目标样本的密度之比,但是,估算样本分布密度存在困难,文中指出,可以使用kliep或者ulsif来对权重进行估算。只使用iwlda可能会导致一个方差较大的分类器,其会造成不稳定的分类效果。为了解决该问题,引入了bagging思想,其通过平均多个分类器的结果作为最终结果来提高分类效果。在bci2000的数据集上进行跨天测试,biwlda对比iwlda准确率从0.9336上升至0.965,对比blda从0.8115上升至0.965。类似的,yang liu等人以及jiayun hou等人在p300 speller上做了跨被试的迁移尝试,其在以传统机器学习为代表的svm方法上使用tradaboost,在循环过程中主要完成两件任务,一是对不同样本进行权重赋值,其权重体现为当前被试数据集在测试集上的预测准确度;二是对于获得的n个svm分类器,同样以准确度作为权重,来均衡得到最后的分类器。
4、在基于特征的迁移方法中,基本思路为在源域试次和目标域试次上创造出一个特征空间,在该特征空间上可以达到源域试次和目标域试次上的统一。farah abid等人基于autoencoder思想提出msdas方法,通过denoising autoencoder来实现,该方法相较于传统的kmm方法相比,对于数据的要求较低,不需要每个样本都有效且带有标签,并且和kmm在跨天实验对比中,有大约5%的准确度提升。另外,由于协方差矩阵在脑电信号上的重要性,也有学者提出基于协方差矩阵来达到特征上的统一,例如hyohyeong kang等人通过将目标域、源域中的协方差矩阵进行线性组合来产生最后的协方差矩阵,文中提供了两种不同方式来构建这个线性组合,第一种方式更倾向于使用试次较多的被试,第二种方式更注重于与目标域相似(kl散度衡量)的源域数据。同样的,在跨被试的实验中,其结果皆优于csp方法与svm方法。dieter devlaminck等人提出可以通过重构csp优化函数来构建一个共享空间过滤器,其主要的思想是,该共享空间过滤器主要有两部分组成,一个是全局过滤器(从所有被试训练出),另一个是特定过滤器(从当前被试训练出),最后最小化由共享过滤器生成的优化函数来决定最后的优化函数。不同于以上方法,另外一类基于特征的迁移方法的思路为对齐。例如,ra方法以黎曼空间为基础,在使用特定的参考数据(不同范式有不同的特征参考数据)为辅助,达到在黎曼空间上的对齐。以此为参考,ea方法基于欧氏空间,利用数据本身为参考,达到对齐后的源域数据和目标域数据白化的目的。与此类似的,还有la和pa等方法。
5、在基于模型的迁移方法中,基本思路为在源域试次上进行模型的训练,直接将该模型进行一定的修改后用于目标试次。如wenting tu等人在跨被试迁移方法中提出的方法,其首先对每个被试训练出一个分类器,然后从这些分类器中通过不同的准则来构建两个子分类器,一个被称为robust filter,另一个被称为adaptive filter,最后通过整合这两个分类器来得到最后的分类器。另一种常用的方法是在卷积神经网络cnn上使用fine-tuning来实现迁移学习,因为在cnn模型中,低层的卷积层通常能提取出普遍的特征,而高层的卷积层则逐渐将特征专有化,所以在该方法中,靠前的特征提取层(cnn)参数由其他被试数据集训练得到,而当前数据集只更新dense层以及其后面涉及到的参数。
6、通过对以上现有研究方法的优缺点进行探讨分析,本发明获得了新的启发和研究思路,提出一种基于源域选择和深度迁移模型的方法,简称“mss-adcn”(mixed sourceselection-adversarial deep convolutional net)。首先,使用基于结果和基于相似度相结合的源域被试方法mss对多源域被试进行筛选,以减少训练时间并在一定程度上减少或消除负迁移现象。随后,adcn采用分窗深度卷积模型对rsvp脑电信号进行时空域上的分析,加入反向对抗网络对源域、当前被试进行区分,使得网络能够提取出两者的共同特征,最后进行分类。相比较没有mss的adcn方法,加入mss方法后,训练时间减少而分类精度提升。mss-adcn在被试提供少量校准试次的情况下达到可接受精度,并优于其他迁移学习方法。
技术实现思路
1、本发明提出了一种基于源域选择和深度迁移模型的跨被试rsvp脑电信号的分类方法,该方法可有效提升在跨被试rsvp脑电信号场景下的分类行能。针对源域被试多且不确定因素高的问题,提出mss(mixedsourceselection)方法,该方法融合基于结果和基于相似度的源域选择方法对多个源域被试进行筛选,一方面减少训练时间,另一方面减少或消除负迁移现象。随后,设计adcn(adversarial deep convolutional net)模型,该模型使用分窗的深度卷积模型,对rsvp的时间信息和空间信息进行先后解码分析,并提取出潜在特征,为了消除源域试次和当前试次间的差距,引入反向对抗网络,该网络用于区分输入试次来源于源域或者是目标域,该网络的损失函数通过grl(gradient reverse layer)层,该层使得网络在前向传播时正常,而在反向传播时为负,即将该损失函数变为最大化,从而使得网络能够提取出目标试次和源域试次的共同特征。相比较没有mss的adcn方法,加入mss方法后,训练时间减少而分类精度提升。mss-adcn在被试提供少量校准试次的情况下达到可接受精度,并优于其他迁移学习方法。
2、经过研究讨论和反复实践,本方法确定最终方案如下:
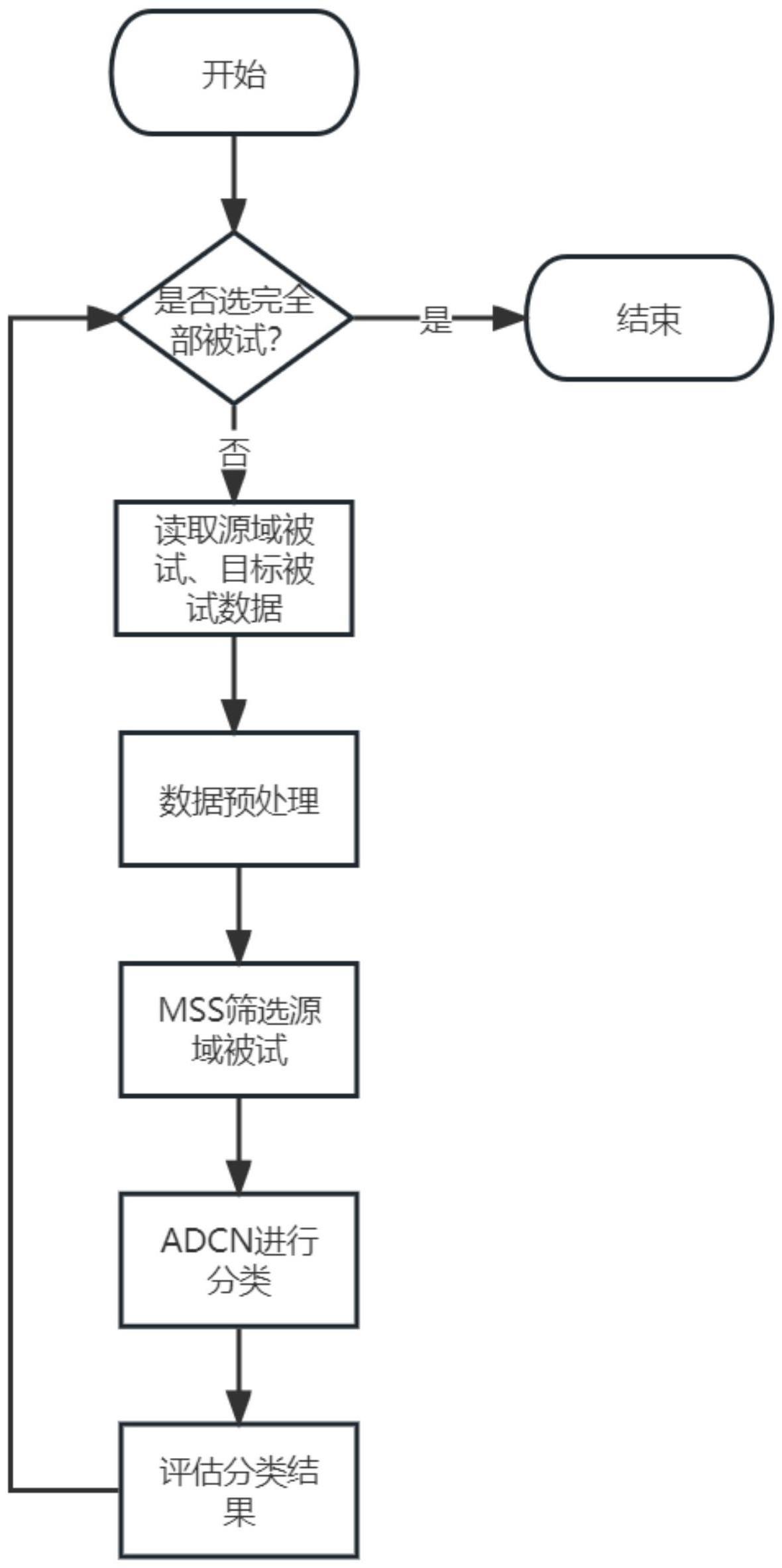
3、首先对原始rsvp脑电数据集进行预处理:试次分割、带通滤波、基带移除等,然后轮流将每个被试作为当前被试,对当前被试进行划分,划分为训练集和测试集,其余被试作为源域被试,作为训练集。将源域被试和当前被试的训练集输入到mss方法中,通过mss方法导出筛选后的源于被试数据;将筛选后的源于被试数据和当前被试的训练数据输入到adcn模型中进行训练,然后将当前被试的测试数据输入到训练后的adcn中得到分类结果,对分类结果进行评估分析,验证方法的有效性。
4、本发明技术方案的具体步骤如下:
5、步骤1.数据预处理:对rsvp脑电信号进行试次的划分,以trigger出现的第0秒到第1秒作为一个试次进行划分;使用带通滤波器对划分后的rsvp脑电信号试次进行带通滤波处理;使用试次内数据,对滤波后的信号做基带移除;对试次数据进行基于通道的标准化。轮流选出一个被试作为当前被试,划分为训练集和测试集,其余被试作为源域被试,作为训练集。
6、步骤2.搭建mss模型,将源域试次输入到mss模型中,通过模型计算,得到筛选后的k个源域被试作为最终的源域训练集。
7、步骤3.搭建adcn模型,将当前被试的训练集和源域训练集整合后,输入到adcn模型中进行训练。
8、步骤4.将当前被试的测试集输入到训练好的adcn模型中得到分类结果,比对原始标签,对模型的分类效果进行评估。
9、本发明具有以下优点:
10、1.增加源域被试筛选方法mss,该方法从两个不同角度出发进行结合来对源域被试进行筛选,减少了adcn的训练时间并减少或消除了负迁移现象。
11、2.使用分窗的cnn模型adcn对rsvp脑电信号进行分析,着重了时域上的分析;在模型中增加了反向对抗网络,使得网络可以提取出源域和目标域的共同特征。
- 还没有人留言评论。精彩留言会获得点赞!